



10分钟快速搭建基于推理微服务的RAG对话机器人应用
发表于: 2025/05/21
1 简介
核心优势
推理微服务基于RESTful API接口,提供vLLM与MindIE后端,可配置多种优化参数配置以提供高吞吐、低时延与均衡默认的性能倾向。
1、高性能推理引擎兼容:vLLM与MindIE推理引擎后端的支持可显著提升模型推理速度,同时降低能耗和部署成本。
2、多种性能配置一键切换:提供多种性能优化配置并支持一键式切换,满足不同场景吞吐、时延的需求。还可通过配置切换推理后端与模型量化类型。
3、丰富的模型支持:支持Qwen(VL),LLaMA,BGE等主流大模型,结合Dify与OpenWebUI等前端工具,实现多模型多任务的混合推理应用。
能力提供
1、多模态模型微服务:视图分析与理解的智能服务。可高效处理和分析视觉数据,提供精准的视图理解能力。
2、大语言模型微服务:文本总结与对话的智能服务。可高效地处理和生成自然语言文本,提供精准的文本总结和对话能力。
3、向量化微服务:数据向量化的智能服务。可将多种输入数据转换为向量表示以构建检索知识库,此外还可对检索的候选结果进行重排。
2 软件版本
| 镜像版本 | CANN 版本(微服务镜像已包含) | PyTorch版本(微服务镜像已包含) |
|---|---|---|
| 7.1.T2-800I-A2-aarch64 | 8.0.0(LLM) / 8.1.RC1(VLM) | 2.5.1 |
3 NPU配置
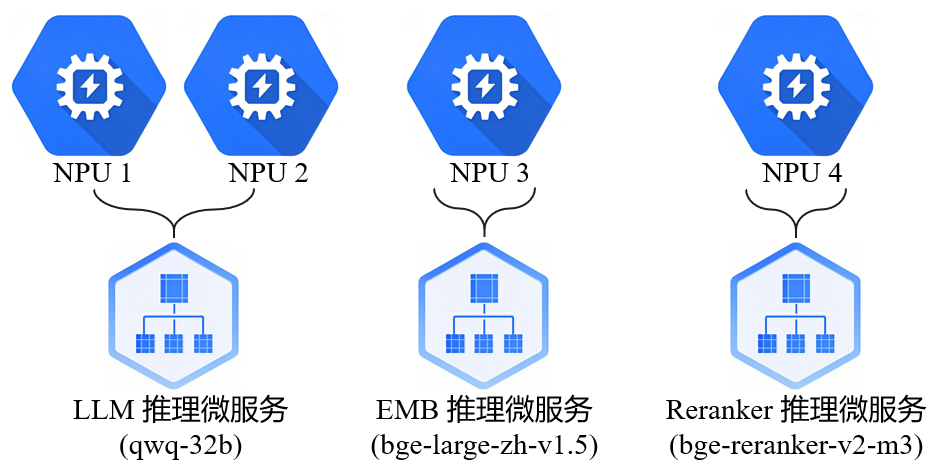
4 快速部署
推理微服务可通过快速便捷的部署不同模型的微服务来处理视频、文本等内容,避免了以往复杂的依赖安装和性能调优,并且可以通过模型镜像来快速替换微服务。通过优化配置可实现高吞吐量、低延迟及默认性能模式的灵活切换,确保在不同应用场景下都能达到最佳的性能表现。
(1)下载镜像
从昇腾社区镜像仓库下载相应的推理微服务镜像,即可快速部署推理微服务。
打开对应镜像模型界面,切到镜像版本,点击下载后生成镜像拉取命令,按步骤依次执行即可下载镜像。
下载镜像后,通过docker加载完成,可运行如下命令查看环境上所有镜像的列表:
docker images(2)基于镜像部署LLM、Embedding 和 Reranker 推理微服务
推理微服务允许用户选择vLLM与MindIE推理引擎并根据性能需求(高吞吐、低时延或默认)配置推理引擎。更多详情请参考各镜像模型的镜像概述
启动LLM推理微服务
# 设置本地缓存路径
export LOCAL_CACHE_PATH=/home/models
# 设置容器名称
export CONTAINER_NAME=qwq-32b
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/qwq-32b:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=0-3 \
-e MIS_CONFIG=atlas800ia2-4x32gb-bf16-mindie-service-default \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
-p 8000:8000 \
--shm-size 1gb \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}启动EMB推理微服务
export LOCAL_CACHE_PATH=/home/models
# 设置容器IP与端口
export MIS_EMB_HOST=0.0.0.0
export MIS_EMB_PORT=7003
# 设置容器名称
export CONTAINER_NAME=bge-large-zh-v1.5
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/bge-large-zh-v1.5:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
-u root -p $MIS_EMB_PORT:9091 \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=4 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
$IMG_NAME $MIS_EMB_HOST 9091
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}启动Reranker推理微服务
export LOCAL_CACHE_PATH=/home/models
# 设置容器IP与端口
export MIS_EMB_HOST=0.0.0.0
export MIS_EMB_PORT=7004
# 设置容器名称
export CONTAINER_NAME=bge-reranker-v2-m3
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/bge-reranker-v2-m3:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
-u root -p $MIS_EMB_PORT:9091 \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=5 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
$IMG_NAME $MIS_EMB_HOST 9091
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}确认推理微服务启动状态
执行启动命令后,在对应的微服务启动界面显示如下内容则表示启动成功:
Application startup complete如需关闭推理微服务,执行如下命令即可关闭对应的微服务
docker stop $CONTAINER_NAME (3)启动Dify大模型开发框架,配置推理微服务
步骤1:下载Dify仓库
如使用GitHub,运行如下命令克隆仓库:
git clone https://github.com/langgenius/dify.git如使用gitee,运行如下命令克隆仓库:
git clone https://gitee.com/dify_ai/dify.git运行如下命令,切换版本(0.15.3 版本较为稳定):
cd dify
git checkout 0.15.3步骤2:启动Dify本地服务
cd ./dify/docker
docker-compose up -d # 视docker compose 版本而定访问部署的Dify服务器IP,即可进入Dify前端页面(进入方式可参考Dify文档 https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose ),首次登陆需配置管理员账户。
步骤3:配置推理微服务
点击进入:个人头像 -> 设置 -> 模型供应商。页面如下图所示:
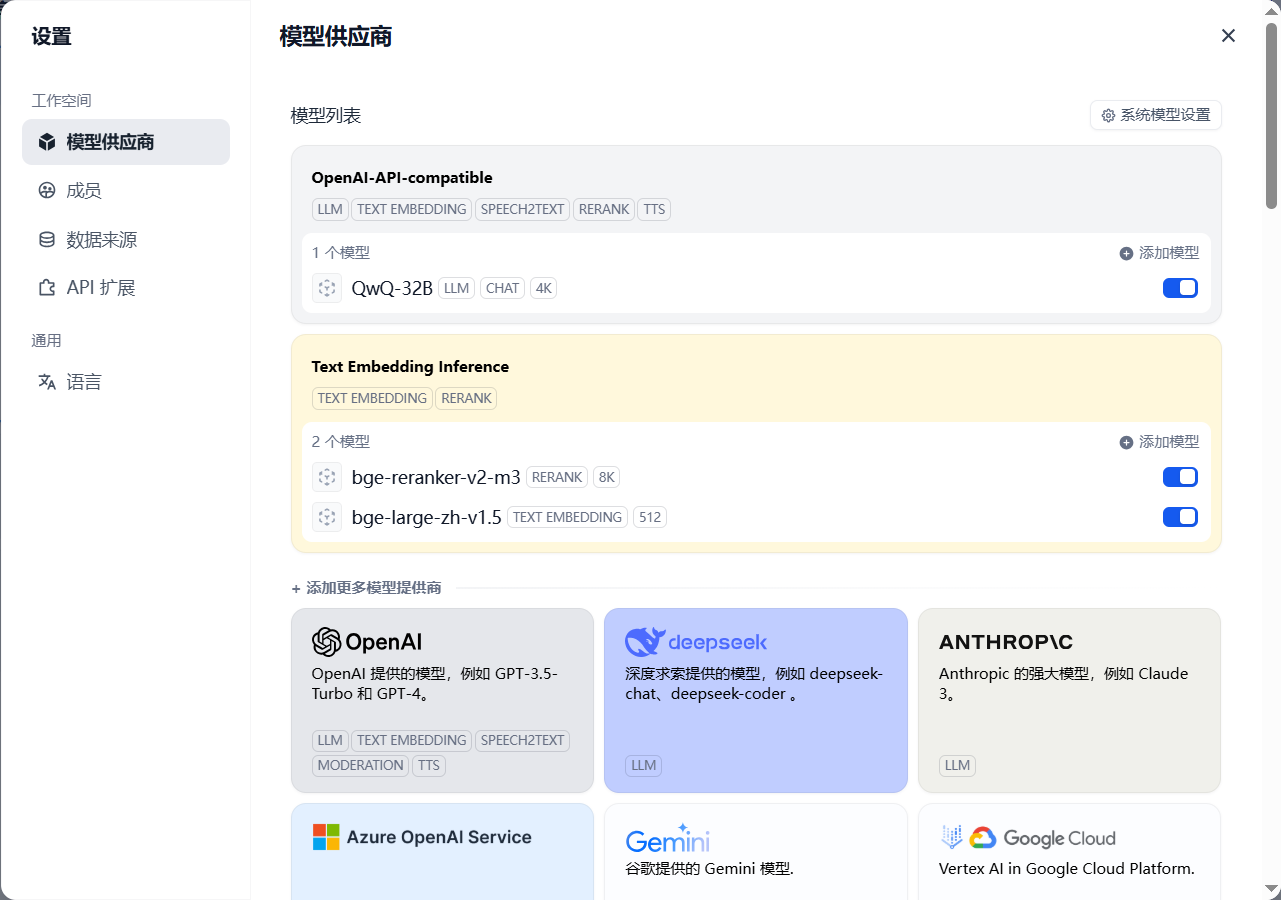
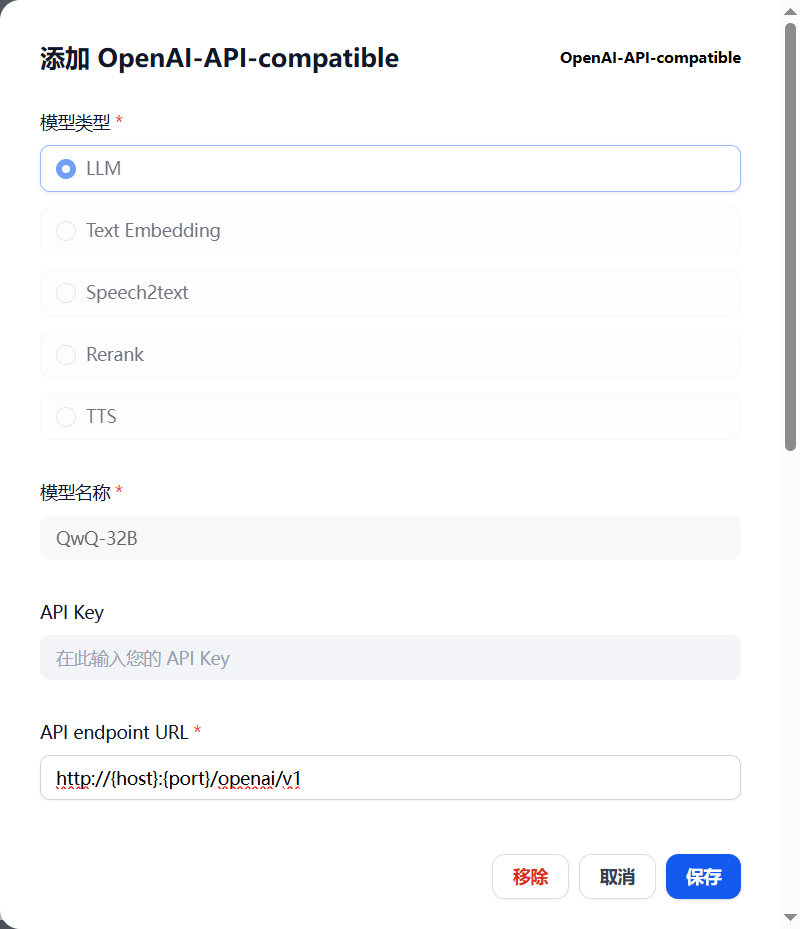
在当前页面,点击进入OpenAI-API-compatible中配置LLM微服务:
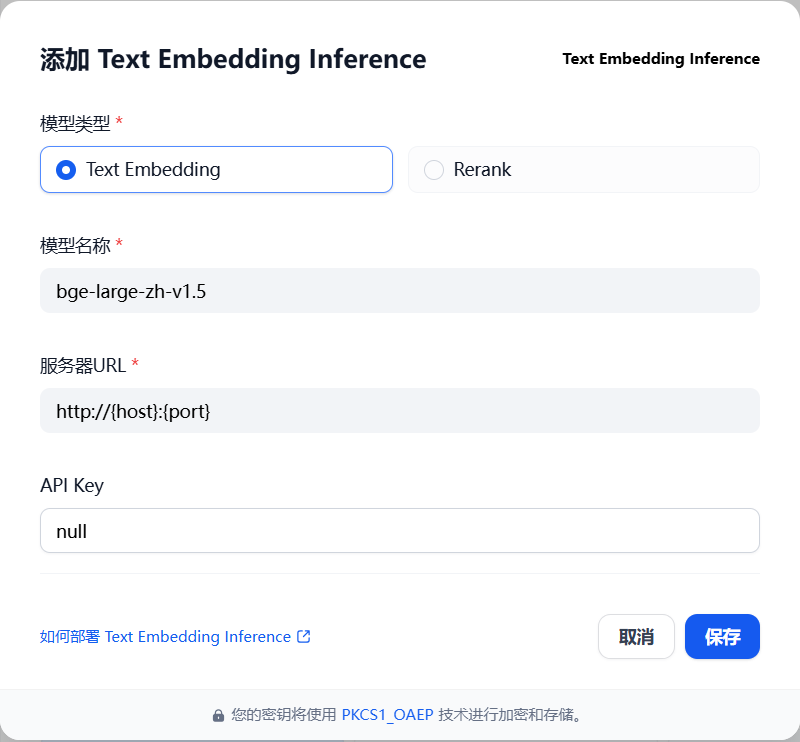
在当前页面,点击进入Text Embedding Inference中配置EMB和 Reranker 微服务:
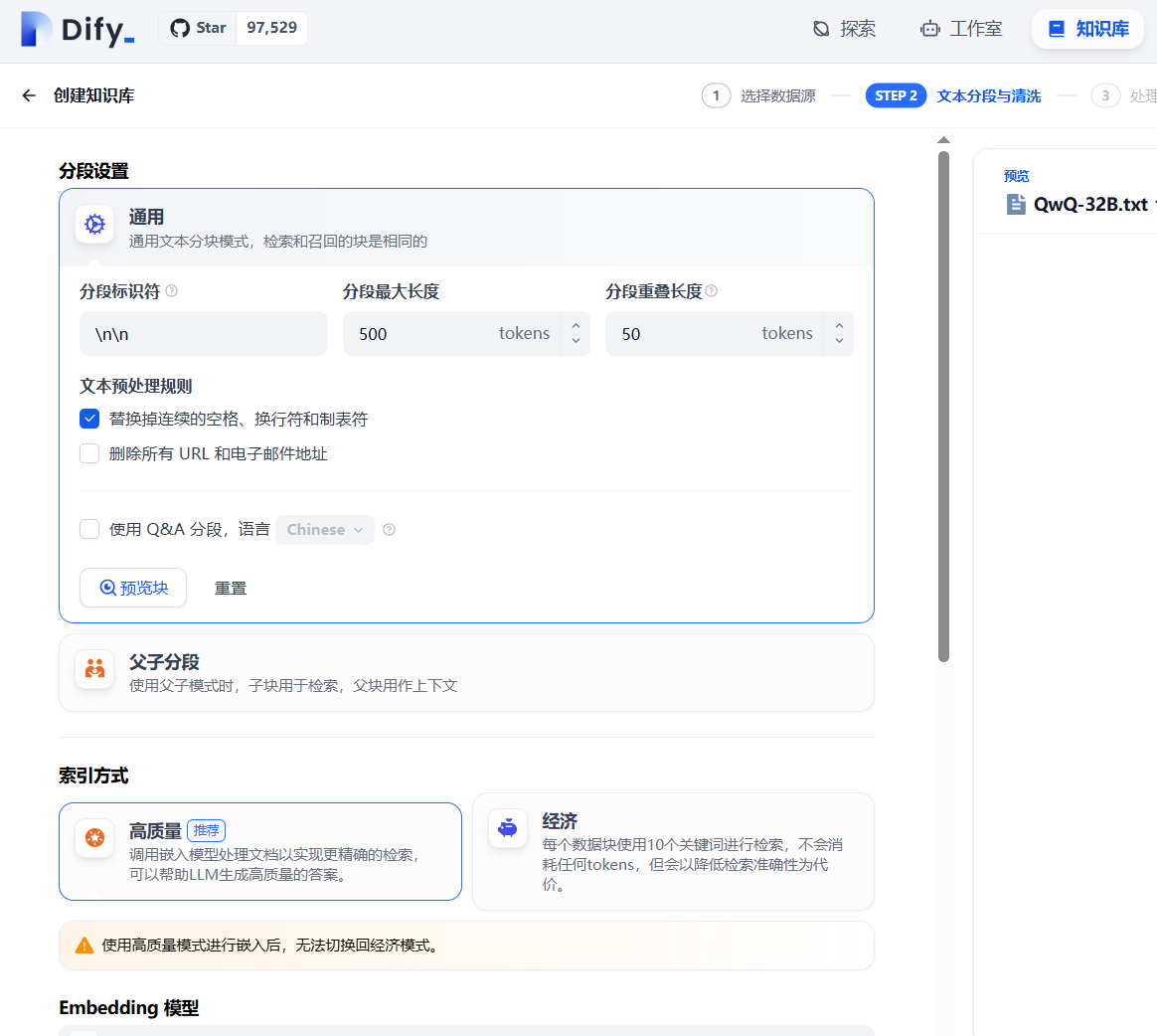
步骤4:构建知识库:上方菜单栏点击知识库 -> 创建知识库 -> 选择相应知识文档/内容 -> 知识库分段,索引与检索配置
步骤5:构建对话机器人应用:
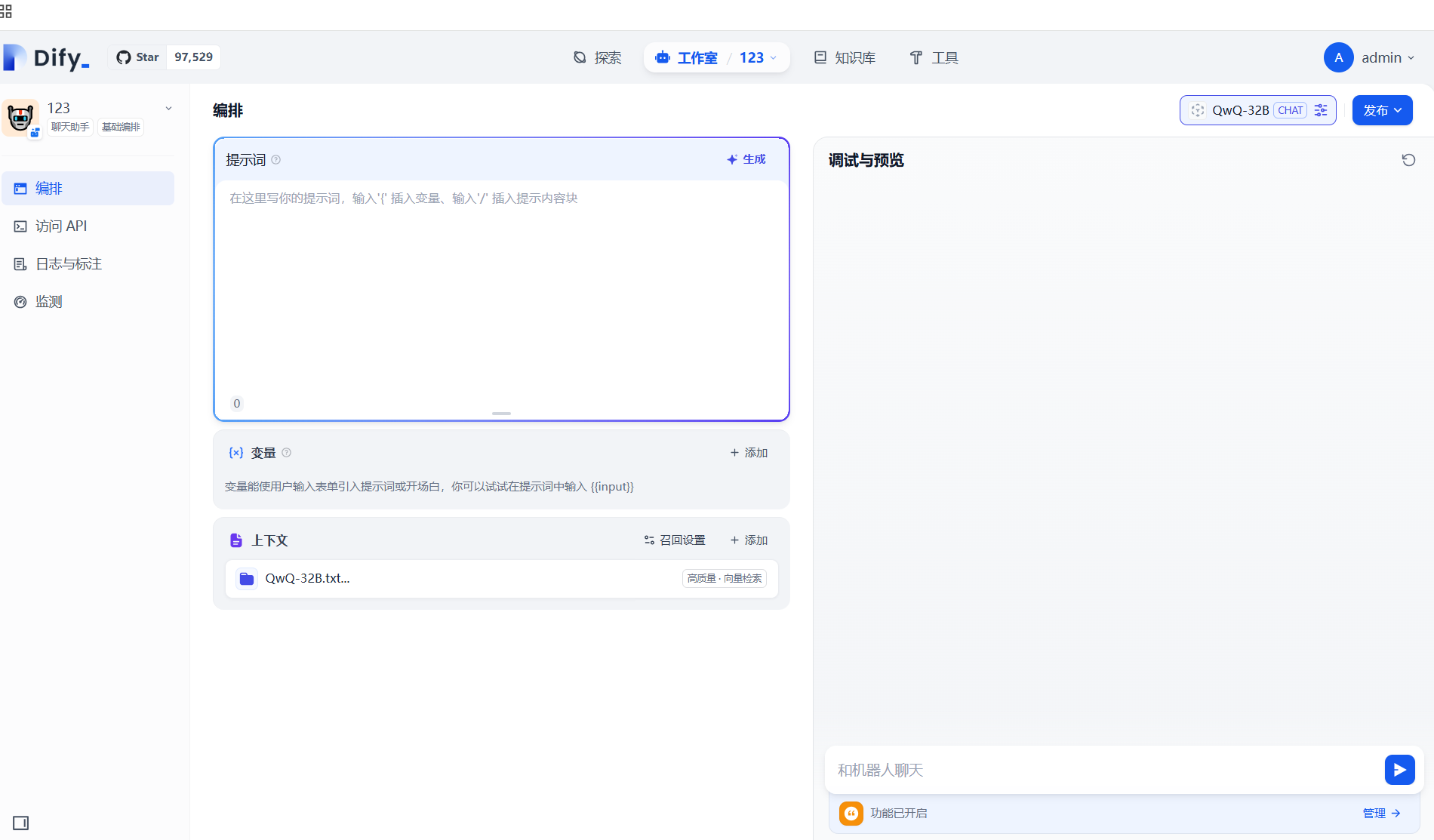
步骤6:上下文引入知识库
点击聊天机器人左侧上下文,点击添加按钮,选择定义的知识库即可完成引入,并在召回设置选择 Reranker 模型
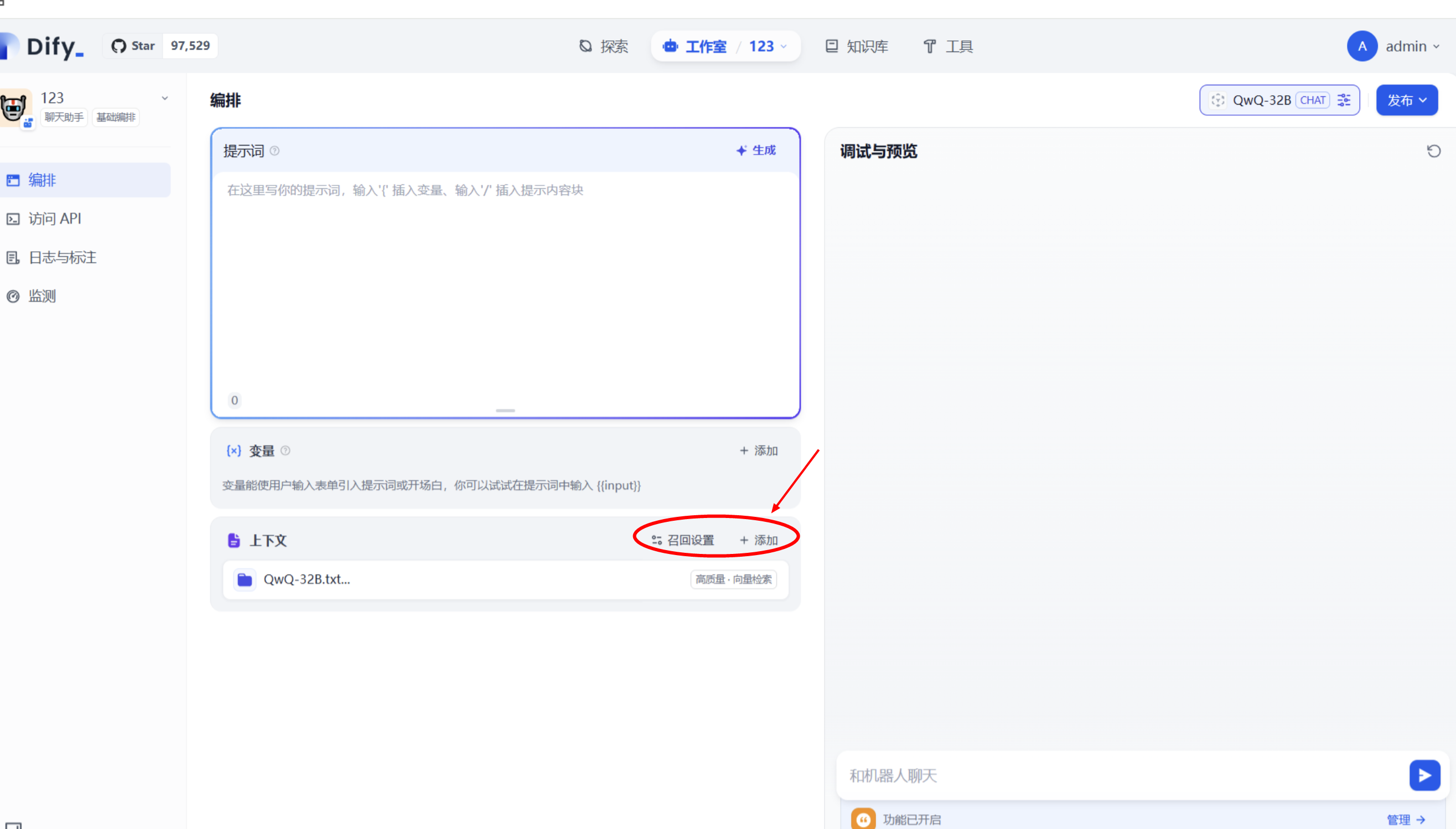
至此,应用构建完成,可进行知识库对话。
(4)体验RAG对话机器人应用1、首先,在上下文不包含知识库的情况下,询问一个在知识库中出现的问题可以看到,模型的回答很有建设性但是与知识库无关。2、在上下文设置中加入知识库后询问相同问题可发现回答很与知识库内容紧密相关,且在文末给出相似段落的检索结果。