DeepSeek 应用最佳实践之量化
发表于: 2025/02/22
环境配置
- 有关DeepSeek的量化,需要下载安装最新版CANN包及msmodelslim(br_noncom_MindStudio_8.0.0_POC_20251231分支),环境配置以及量化工具安装请参考使用说明的方式二安装。(https://gitee.com/ascend/msit/blob/br_noncom_MindStudio_8.0.0_POC_20251231/msmodelslim/README.md)
- 如果使用mindie镜像的话,需要下载安装msmodelslim(br_noncom_MindStudio_8.0.0_POC_20251231分支),安装方式参考使用说明的方式二安装。(https://gitee.com/ascend/msit/blob/br_noncom_MindStudio_8.0.0_POC_20251231/msmodelslim/README.md)
运行前必检
在运行脚本前,请根据以下必检项对相关内容进行更改。
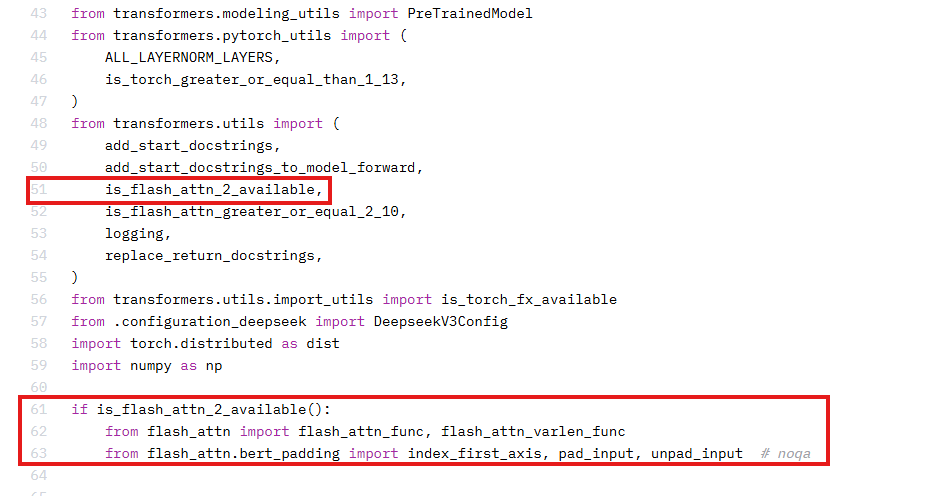
1、昇腾不支持flash_attn库,运行时需要注释掉权重文件夹中modeling_deepseek.py中的部分代码。
2、需安装更新transformers版本(>=4.48.2)。
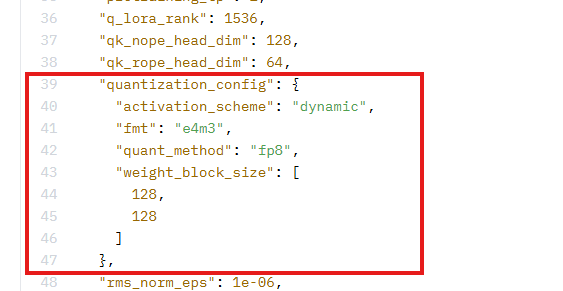
3、当前昇腾设备不支持FP8格式加载,需要将权重文件夹中config.json中的以下字段删除:
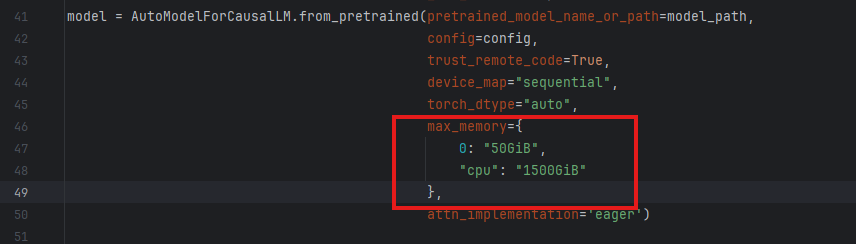
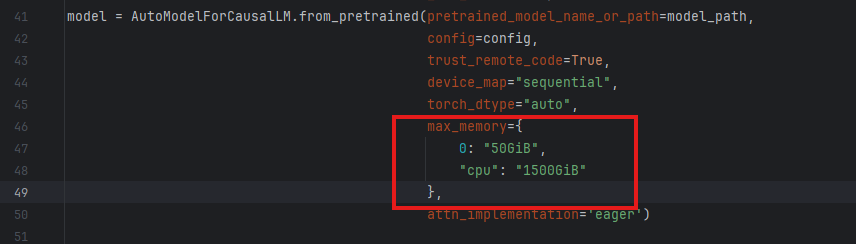
4、修改quant_deepseek_w8a8.py脚本,增加卡数,eg: max_memory={0: "50GiB", 1: "50GiB", "cpu": "1500GiB"}, 可以根据自己的卡数以及显存情况设置,以防OOM显存不够报错。
量化权重生成
- 量化权重可使用quant_deepseek.py和quant_deepseek_w8a8.py脚本生成,以下提供DeepSeek模型量化权重生成快速启动命令。
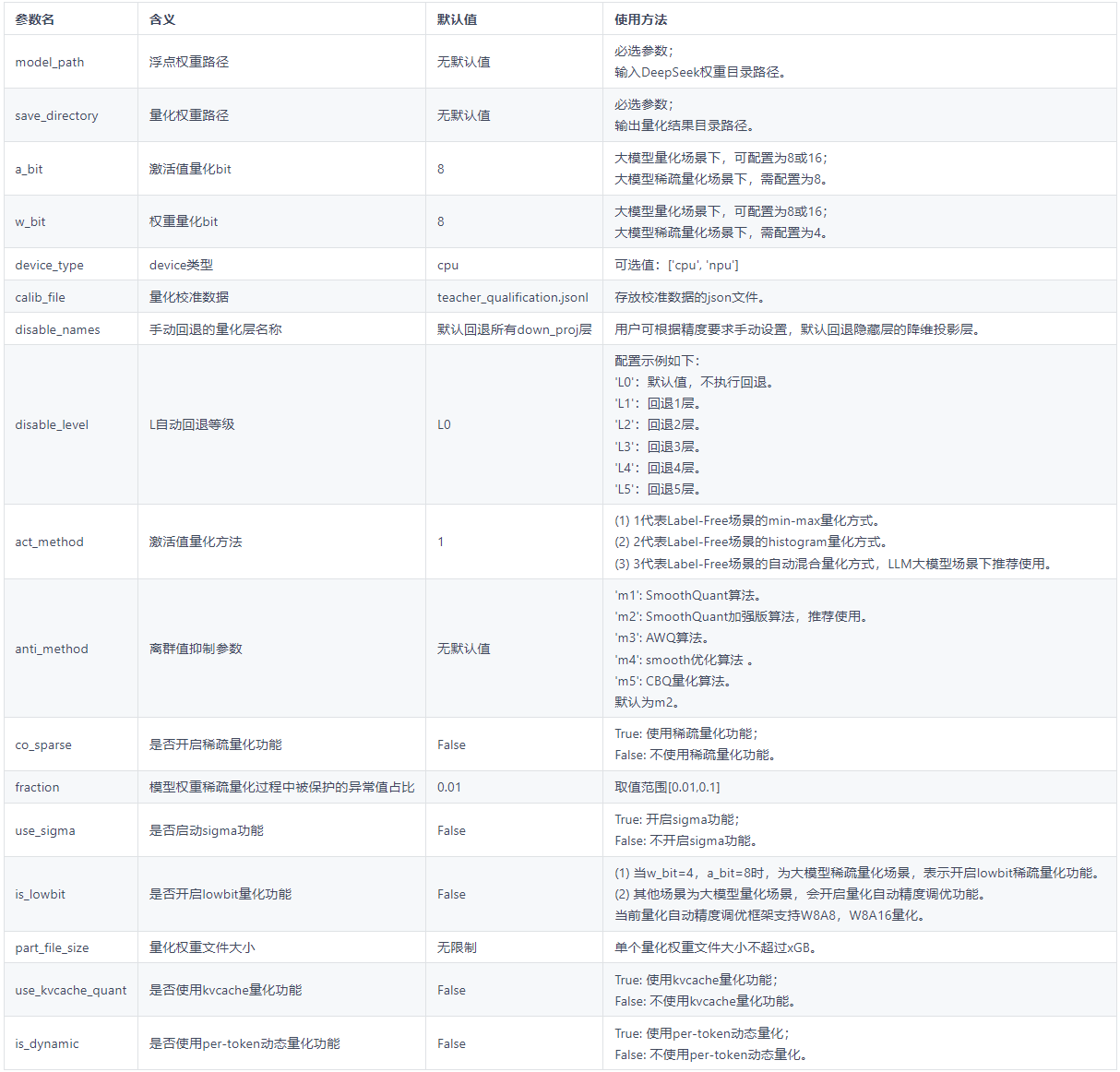 quant_deepseek_w8a8.py 量化参数说明
quant_deepseek_w8a8.py 量化参数说明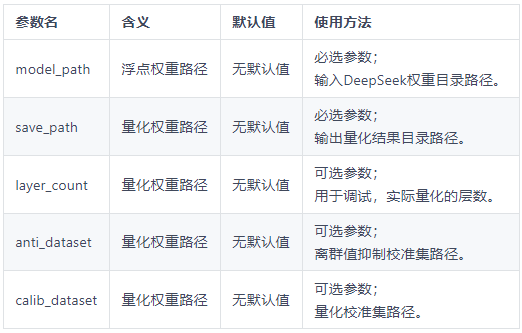
- 更多参数配置要求,请参考量化过程中配置的参数 QuantConfig 以及量化参数配置类 Calibrator
使用案例
请将{浮点权重路径}和{量化权重路径}替换为用户实际路径。
如果需要使用npu多卡量化,请先配置环境变量,支持多卡量化:
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7export PYTORCH_NPU_ALLOC_CONF=expandable_segments:False
DeepSeek-V2/V3/R1 模型量化
生成DeepSeek-V2模型w8a16量化权重,使用histogram量化方式,在CPU上进行运算
python3 quant_deepseek.py --model_path {浮点权重路径} --save_directory {W8A16量化权重路径} --device_type cpu --act_method 2 --w_bit 8 --a_bit 16
生成DeepSeek-V2模型 w8a8 dynamic量化权重,使用histogram量化方式,在CPU上进行运算
python3 quant_deepseek.py --model_path {浮点权重路径} --save_directory {W8A16量化权重路径} --device_type cpu --act_method 2 --w_bit 8 --a_bit 16
3、DeepSeek-V2/V3/R1 w8a8 混合量化(MLA:w8a8量化,MOE:w8a8 dynamic量化)
注:当前量化只支持输入bfloat16格式模型
生成DeepSeek-V2/V3/R1模型 w8a8 混合量化权重
python3 quant_deepseek_w8a8.py --model_path {浮点权重路径} --save_path {W8A8量化权重路径}
4、DeepSeek-V2/V3/R1 w4a16 per-group量化(MLA:float,MOE:w4a16)
注:当前量化只支持输入bfloat16格式模型
生成DeepSeek-V2/V3/R1模型 w4a16 量化权重
python3 quant_deepseek.py \
--model_path {浮点权重路径} \
--save_directory {W4A16量化权重路径} \
--w_bit 4 \
--a_bit 16 \
--group_size 64 \
--is_lowbit True \
--open_outlier False \
--device "npu" \
--calib_file ""
DeepSeek量化QA
Q:报错 This modeling file requires the following packages that were not found in your environment:flash_attn. Run 'pip install flash_attn'
A: 当前环境中缺少flash_attn库且昇腾不支持该库,运行时需要注释掉权重文件夹中modeling_deepseek.py中的部分代码。
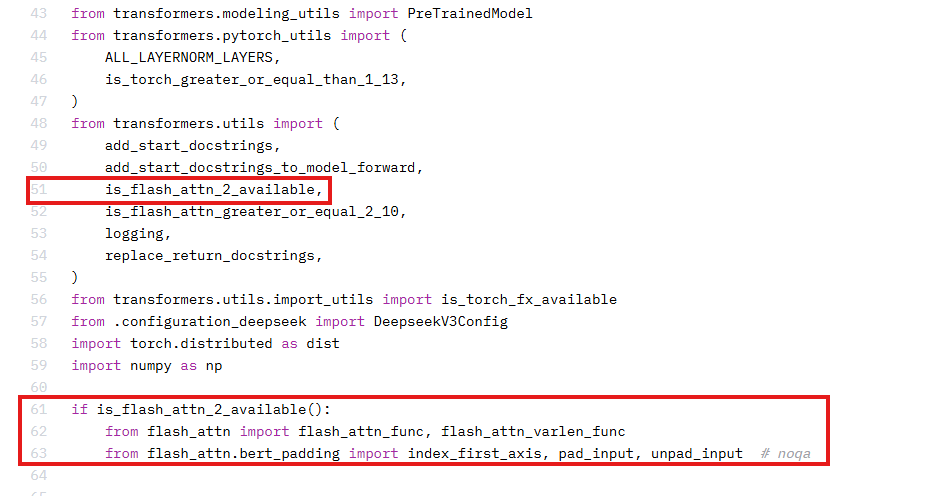
Q:modeling_utils.py报错 if metadata.get("format") not in ["pt", "tf", "flax", "mix"]: AttributeError: "NoneType" object has no attribute 'get';
A:说明输入的的权重中缺少metadata字段,需安装更新transformers版本(>=4.48.2)。
Q:报错 Unknown quantization type,got fp8 - supported types are:['awq', 'bitsandbytes_4bit','bitsandbytes_8bit', 'gptq', 'aqlm', 'quanto', 'eetq', 'hqq','fbgemm_fp8']。
A: 由于当前昇腾设备不支持FP8格式加载,需要将权重文件夹中config.json中的以下字段删除:
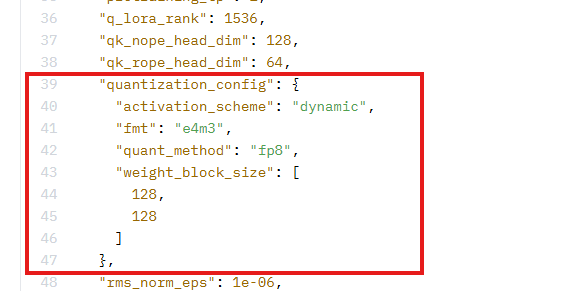
Q: 遇到OOM显存不够报错。
A:修改quant_deepseek_w8a8.py脚本,增加卡数,eg: max_memory={0: "50GiB", 1: "50GiB", "cpu": "1500GiB"}, 可以根据自己的卡数以及显存情况设置。