单算子调用流程
本节介绍调用单算子的两种方式、以及这两种方式下的接口调用流程。
开发应用时,如果涉及执行单个算子,请先参见AscendCL接口调用流程了解整体流程,再查看本节中的流程说明。
系统支持的算子请参见《AOL算子加速库接口参考》中的“CANN算子规格说明”。
对于系统不支持的算子,用户需先参见《Ascend C算子开发指南》完成自定义算子开发。

单算子调用方式:单算子模型执行、单算子API执行、Kernel加载与执行
- 单算子API执行:基于C语言的API执行算子,无需提供IR(Intermediate Representation)定义,直接调用单算子API执行下的算子接口即可。该方式下接口形式定义为“两段式接口”,形如:
1 2
aclnnStatus aclxxXxxGetWorkspaceSize(const aclTensor *src, ..., aclTensor *out, ..., uint64_t *workspaceSize, aclOpExecutor **executor); aclnnStatus aclxxXxx(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream);
必须先调用第一段接口aclxxXxxGetWorkspaceSize,用于计算本次API调用过程中需要多少workspace内存,获取到本次计算所需的workspaceSize后,按照workspaceSize申请NPU内存,然后调用第二段接口aclxxXxx执行计算。其中“aclxx”表示算子接口前缀,如aclnn;而“Xxx”表示对应的算子类型,如Add算子。
当前支持以单算子API执行方式调用的算子包括如下几类:
- NN算子:Neural Network算子,CANN内置的基础算子,接口前缀为aclnnXxx,主要覆盖TensorFlow、Pytorch、MindSpore、ONNX等框架中深度学习算法相关的计算类型,例如常见的Softmax、MatMul、Convolution等。
- 融合算子:CANN内置的融合算子,接口前缀为aclnnXxx,由多个独立的基础“小算子”(如向量Vector、矩阵Cube等)融合成“大算子”,多个小算子功能与大算子功能等价,而大算子在性能或内存收益优于小算子。例如常见的Flash Attention、通算融合算子(简称MC2算子)等。
- DVPP算子:Digital Vision Pre-Processing算子,接口前缀为acldvppXxx,提供高性能视频/图片编解码、图像裁剪缩放等预处理API。
- 单算子模型执行:基于图IR执行算子,先编译算子(例如,使用ATC工具将Ascend IR定义的单算子描述文件编译成算子om模型文件),再调用AscendCL接口加载算子模型(例如aclopSetModelDir接口),最后调用AscendCL接口执行算子(例如aclopExecuteV2接口)。
- Kernel加载与执行:基于算子Kernel执行算子,先调用aclrtBinaryLoadFromFile加载算子二进制文件(*.o文件),再调用aclrtLaunchKernelWithConfig接口Launch Kernel,最后调用aclrtBinaryUnLoad接口卸载算子二进制。

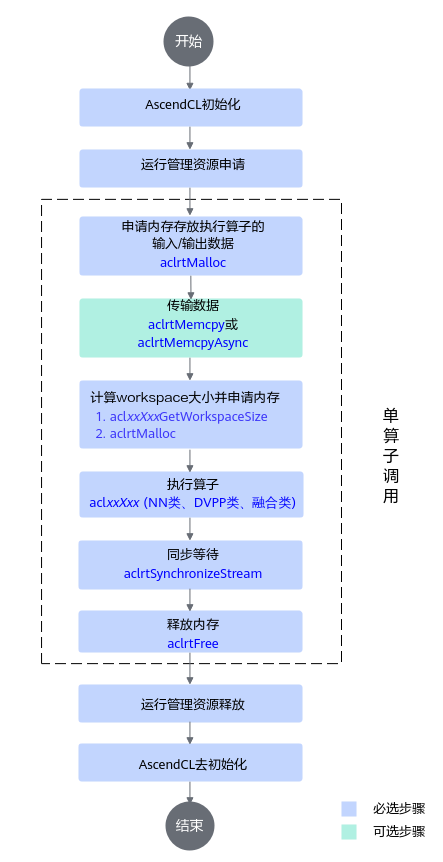
单算子API执行接口调用流程
-
依次申请运行管理资源,具体流程请参见运行管理资源申请与释放。
- 数据内存申请和传输。
- 调用aclrtMalloc接口申请Device上的内存,存放待执行算子的输入、输出数据。
- 调用aclCreateTensor、aclCreateIntArray等接口构造算子的输入、输出数据,如aclTensor、aclIntArray等,详细接口请参见单算子API执行。
如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输。
- 计算workspace并执行算子。
- 调用aclrtSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用aclrtFree接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。
- 运行管理资源释放。
- 调用aclDestroyTensor、aclDestroyIntArray等接口释放算子的输入、输出,相关接口请参见单算子API执行。
- 所有数据释放后,需要依次释放运行管理资源,具体流程请参见运行管理资源申请与释放。
- AscendCL去初始化。
单算子模型执行接口调用流程
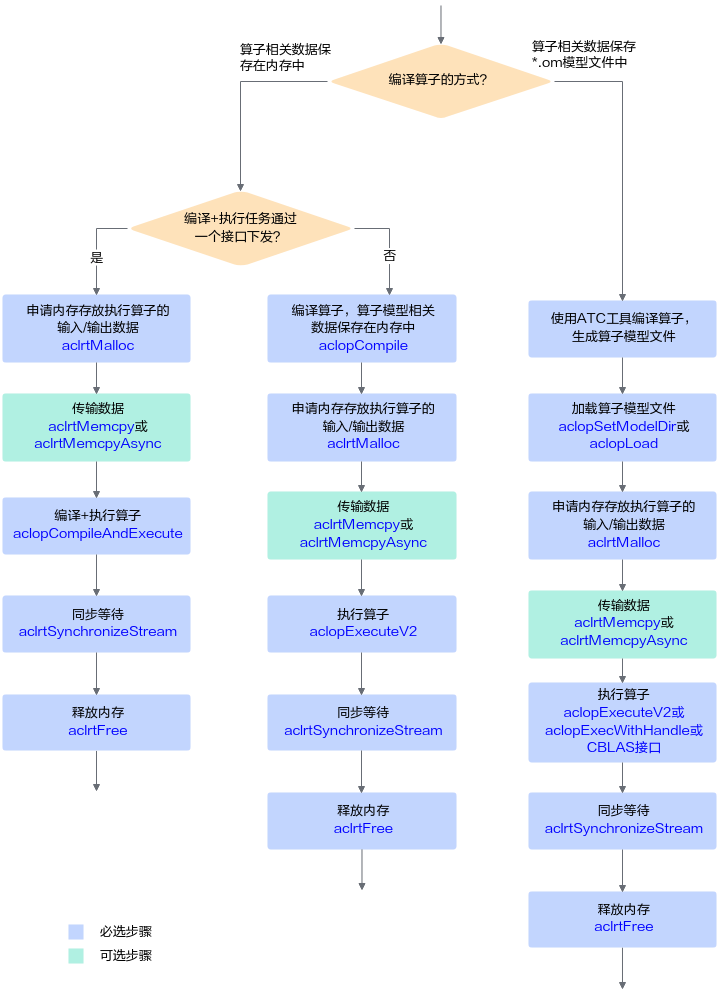
- 编译算子。
根据算子编译的方式,可分为以下两种:
- 加载算子模型文件。
- 调用aclrtMalloc接口申请Device上的内存,存放执行算子的输入、输出数据。
如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输。
- 动态Shape场景,如果无法明确算子的输出Shape时,在执行算子前,还需推导或预估算子的输出Shape。
需用户调用aclopInferShape接口、aclGetTensorDescNumDims接口、aclGetTensorDescDimV2接口、aclGetTensorDescDimRange等接口,推导或预估算子的输出Shape,作为算子执行接口aclopExecuteV2的输入。
- 执行算子。
- 调用aclrtSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用aclrtFree接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。
Kernel加载与执行接口调用流程

关键流程说明如下:
- 调用aclInit接口初始化AscendCL。
详细说明请参见AscendCL初始化与去初始化。
- 申请运行管理资源,包括调用aclrtSetDevice接口指定用于运算的Device、调用aclrtCreateStream接口创建Stream。
详细说明请参见运行管理资源申请与释放。
- 调用aclrtBinaryLoadFromFile接口加载算子二进制文件。
- 调用aclrtBinaryGetFunctionByEntry或aclrtBinaryGetFunction接口获取核函数句柄。
- 根据核函数句柄操作其参数列表,操作包括:
- 初始化参数列表
当前支持由系统管理内存(调用aclrtKernelArgsInit接口)、由用户管理内存(调用aclrtKernelArgsInitByUserMem接口)两种方式。
- 追加参数、更新参数值
核函数参数列表中包含不同类型的参数,例如指针类型参数、placeHolder、uint8_t类型参数等,其中:
- 指针类型参数:其值为Device内存地址。一般来说,算子的输入、输出是该种类型的参数,用户需提前调用Device内存申请接口(例如aclrtMalloc接口)申请内存,并自行拷贝数据至Device侧。
- placeHolder:也是指针类型参数,但区别在于,用户无需手动将参数数据复制到Device,这项操作由Runtime完成。在追加参数时Runtime并不会填写真实的Device地址,而是在Launch Kernel时才会刷新为真实的Device地址,所以称之为placeHolder。对算子的非输入、输出参数,可以使用placeHolder方式,将小块数据(建议小于2KB)的Host->Device拷贝合并到Launch Kernel时的一次拷贝操作中去,减少拷贝次数,提升性能。

不同类型参数,可调用不同的参数追加接口:
- 对于placeHolder参数,由于关联的内存必须放在所有参数之后,所以在追加参数时,先调用aclrtKernelArgsAppendPlaceHolder接口占位,等所有参数都追加之后,可调用aclrtKernelArgsGetPlaceHolderBuffer接口获取对应占位符指向的内存地址。用户可根据获取的内存地址,管理该内存中的数据。
- 对于非placeHolder参数(例如指针类型参数、uint8_t类型参数等),调用aclrtKernelArgsAppend接口将用户设置的参数值追加拷贝到argsHandle指向的参数数据区域。如果要更新参数值,可调用aclrtKernelArgsParaUpdate接口进行更新。
注意,核函数参数列表中,实际可能存在多个参数,并且不同类型的参数可能交错出现,因此需要按照参数列表中的参数顺序从左到右进行追加,追加的参数最多支持128个。
- 结束参数列表的追加、参数值的更新
在所有参数追加之后,调用aclrtKernelArgsFinalize接口以标识参数组装完毕。但aclrtKernelArgsFinalize接口之后,也支持继续更新参数值,更新之后,还要再调用一次aclrtKernelArgsFinalize接口。
- 初始化参数列表
- 调用aclrtLaunchKernelWithConfig接口Launch Kernel,启动对应算子的计算任务。
- 调用接口aclrtBinaryUnLoad卸载算子二进制文件。
- 释放运行管理资源,包括调用aclrtDestroyStream接口释放Stream、调用aclrtResetDevice接口释放Device上的资源。
详细说明请参见运行管理资源申请与释放。
- 调用aclFinalize接口去初始化AscendCL。
详细说明请参见AscendCL初始化与去初始化。