



服务器运维监控平台参考实践
发表于: 2026/06/30
非商用说明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
1 方案介绍
1.1 背景
昇腾NPU与鲲鹏服务器共同构成算力集群的重要基础,二者的运行状态都会直接影响AI任务的稳定性和性能表现。其中昇腾NPU作为核心算力单元,承担模型训练、推理加速等关键计算任务,其算力利用率、温度、功耗、显存使用率等指标能够反映加速设备的运行负载与健康状态;鲲鹏服务器作为承载NPU设备和业务服务的基础平台,其CPU负载、内存使用、磁盘容量、磁盘 I/O、网络吞吐等基础资源状态,同样关系到任务调度、数据读写、服务响应和集群稳定运行。因此,运维系统需要同时关注昇腾NPU 与鲲鹏服务器的运行状态,实现对算力资源和基础资源的统一监控,帮助运维人员及时发现资源瓶颈、硬件故障或系统异常,降低故障定位耗时,提升算力集群的运维效率和可靠性。
本参考实践基于NPU-Exporter和Node-Exporter,提供一套覆盖昇腾NPU设备与鲲鹏服务器基础资源的标准化监控方案,帮助用户从算力设备到服务器节点形成完整的监控视图,保障服务器集群稳定、高效运行。
1.2 方案简介
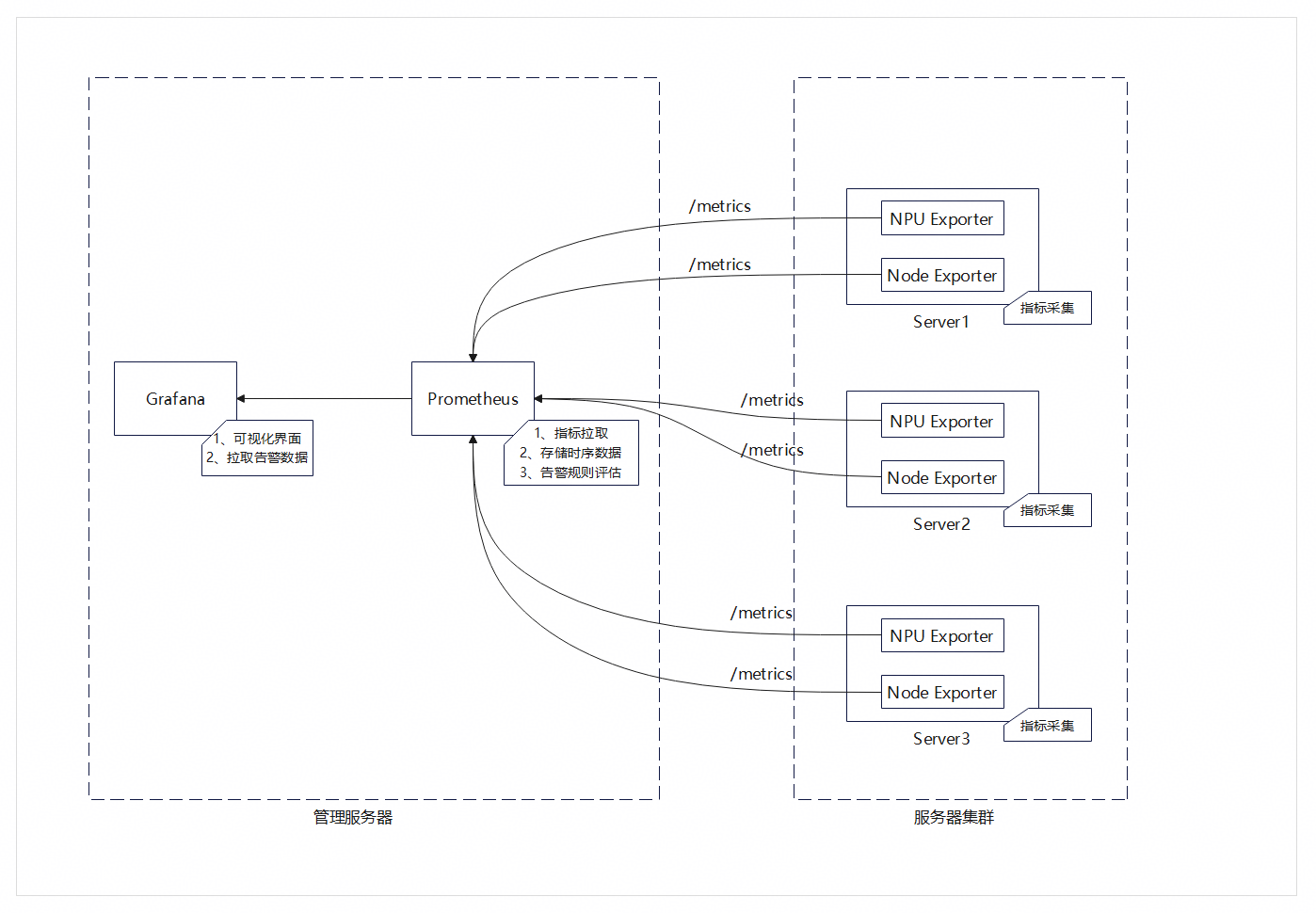
本参考实践采用开源Node-Exporter组件、昇腾NPU-Exporter组件、开源软件Prometheus(数据汇总和阈值监控)、和Grafana(可视化组件)的组合,构建了一套全流程、一体化的鲲鹏服务器+昇腾NPU监控体系,实现对服务器和昇腾NPU从指标采集、存储到可视化展示与告警管理的全生命周期监控。
各组件功能说明如下:
- Node-Exporter:服务器基础资源指标采集组件,能够采集服务器CPU、内存、磁盘、文件系统、网络等运行指标,并以Prometheus标准格式对外暴露,帮助运维人员了解服务器节点的资源使用情况和系统健康状态。
- NPU-Exporter:昇腾NPU指标采集的核心组件,能够以Prometheus标准化的格式采集算力利用率、温度、功耗、内存使用率等核心运行指标,并通过metrics接口向外暴露指标数据。
- Prometheus:指标存储与告警规则触发的核心角色,通过定时拉取NPU-Exporter采集的指标数据,实现监控数据的存储与检索,同时支持自定义监控规则。
- Grafana:可视化展示工具,基于Prometheus的指标数据提供图表类型和仪表盘配置能力,将NPU的运行指标以直观的可视化形式呈现,在专属告警面板展示集群告警详情(如告警级别、触发时间、指标阈值、恢复状态等),帮助运维人员实时掌握NPU的运行状态、分析性能趋势,并快速定位故障问题。
各组件关系图如下:
图1 监控平台各组件关系图
1.3 关键特性
- 标准化指标采集:NPU-Exporter和Node-Exporter均以Prometheus标准数据格式对外暴露指标,便于统一接入监控体系,避免因数据格式不一致带来的集成问题。NPU-Exporter针对昇腾NPU的硬件架构和运行机制进行适配,能够采集算力利用率、温度、功耗、芯片负载、显存使用率、内存带宽等核心运行指标。Node-Exporter用于采集鲲鹏服务器的基础资源指标,包括CPU使用率、系统负载、内存使用率、磁盘容量、磁盘I/O、文件系统状态、网络吞吐等。
- 告警管理:基于Prometheus的告警规则引擎,用户可针对昇腾NPU和鲲鹏服务器分别配置告警阈值。例如,NPU侧可配置处理器温度持续过高、AI Core利用率异常、显存使用率过高等告警;服务器侧可配置 CPU负载过高、内存使用率过高、磁盘空间不足、磁盘 I/O异常、网络流量异常等告警。告警触发后,可通过Grafana告警面板展示告警详情,帮助运维人员及时发现问题并快速响应。
- 可视化:Grafana提供丰富的可视化组件,包括折线图、柱状图、仪表盘等,可根据运维需求灵活配置NPU监控仪表盘和服务器资源监控仪表盘,直观展示NPU的实时运行状态、历史性能趋势、集群整体负载,以及鲲鹏服务器的CPU、内存、磁盘、网络等基础资源使用情况,帮助运维人员从设备和主机两个层面掌握集群运行状态。
- 支持硬件类型:本方案支持昇腾Atlas系列推理、训练产品,以及鲲鹏服务器。
1.4 应用场景
在基于昇腾NPU与鲲鹏服务器构建的AI训练和推理集群中,该方案可同时监控 NPU 的算力利用率、功耗、温度、显存使用率等指标,以及鲲鹏服务器的CPU、内存、磁盘、网络等基础资源指标。运维人员可通过Grafana仪表盘统一查看集群负载、服务器资源和NPU运行状态,合理分配训练任务和推理请求,避免因算力资源过载或服务器资源异常导致任务延迟或失败。
当NPU出现温度异常、硬件故障、显存使用率过高,或服务器出现CPU负载过高、内存不足、磁盘空间不足、网络异常等问题时,告警系统可及时触发通知,帮助运维人员快速定位并处理故障,保障AI业务稳定运行。
1.5 部署方案
1.5.1 典型硬件配置
下表提供了本方案的硬件典型配置:
表1 硬件典型配置表
节点类型 | 服务器配置 | 数量 | 部署内容 |
|---|---|---|---|
NPU-Exporter、Node-Exporter节点 | 集群管理的所有服务器 | ≥1(以实际业务需求为准) | 集群中所有服务器以二进制方式部署NPU-Exporter、Node-Exporter。 (注意:没有NPU卡的服务器则不需要部署NPU-Exporter)。 |
Prometheus节点 | 1、混合部署场景,选一台服务器做管理节点,同时部署NPU-Exporter、Node-Exporter节点与Prometheus节点、Grafana节点。 2、分离部署场景,Prometheus节点和Grafana节点部署到独立的通算服务器上。 | 1 | Docker容器部署Prometheus,配置告警规则。 容器资源配置推荐如下: CPU:4核或以上 内存:8GB或以上 存储:以实际业务需求为准(建议预留充足的磁盘存储空间,用于存放Prometheus落盘数据文件。Prometheus数据量参考:纳管3台服务器时,1周数据量约100MB) |
Grafana节点 | 1、混合部署场景,选一台服务器做管理节点,同时部署NPU-Exporter、Node-Exporter节点与Prometheus节点、Grafana节点。 2、分离部署场景,Prometheus节点和Grafana节点部署到独立的通算服务器上。 | 1 | Docker容器部署Grafana,导入监控面板。 容器资源配置推荐如下: CPU:4核或以上 内存:8GB或以上 存储:以实际业务需求为准 |
1.5.2 软件版本
本参考实践使用的软件配套版本如下(实际使用版本建议不低于表1中的软件版本):
表1 软件配套版本表
软件/镜像 | 版本 | 说明 |
|---|---|---|
NPU-Exporter | 7.1.RC1 | 采集昇腾NPU指标的核心组件 |
Node-Exporter | 1.7.0 | 采集鲲鹏服务器指标的核心组件 |
prom/prometheus | 3.7.3 | 指标存储、告警管理 |
grafana/grafana | 12.3.0 | 可视化展示工具 |
Ascend HDK | 25.5.0 | NPU驱动固件,物理机上安装 |
Docker | 18.09.0 | 物理机上安装 |
Docker Compose | 2.33.1 | 运行多容器Docker |
OS | openEuler release 22.03 (LTS-SP4) | 物理机OS |
1.5.3 混合部署
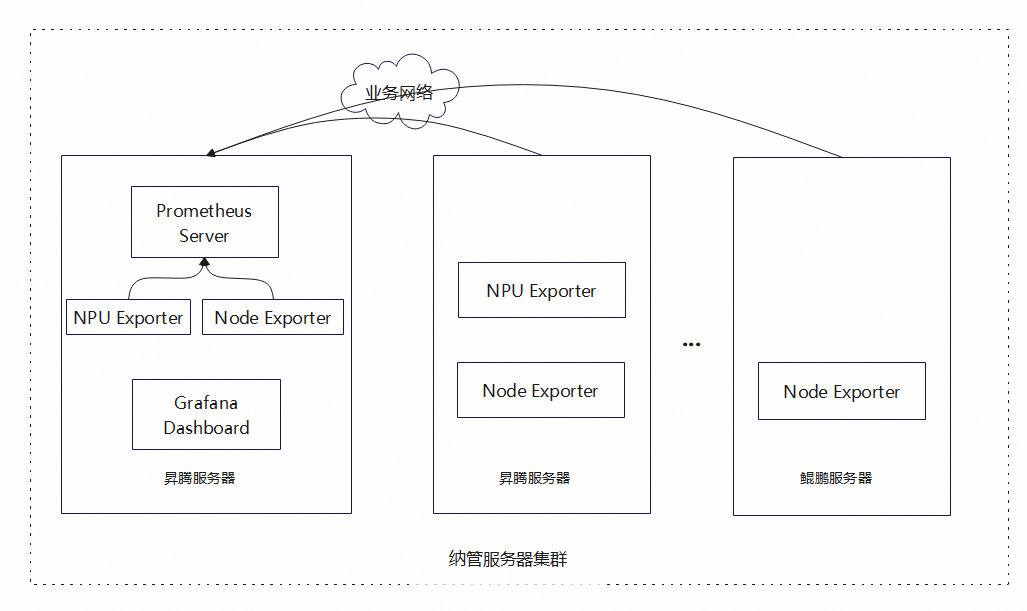
当管理小于8台推理服务器时,推荐使用混合部署,即Prometheus和Grafana部署在推理服务器上,如下图所示。
图1 混合部署方案图
1.5.4 分离部署
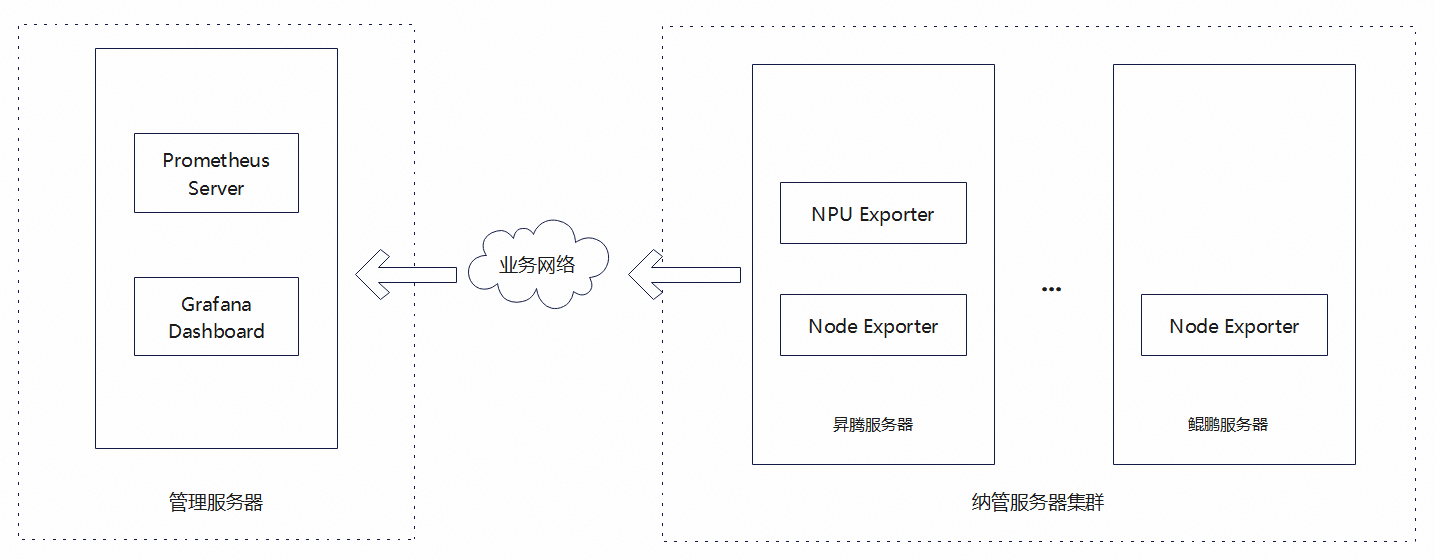
当管理8~16台推理服务器时,建议使用分离部署,即使用单独的管理服务器来部署Prometheus和Grafana,如下图所示。
图1 分离部署方案图
2 部署指导
2.1 前置条件
- 已完成OS和Docker安装;
- 参考对应昇腾版本和设备的《昇腾软件安装指南》,推理服务器完成昇腾驱动和固件安装,参考 链接 ;
2.2 安装部署
用户可从以下两种部署方式中选择一种进行安装部署。
2.2.1(可选)手动部署
2.2.1.1 Node-Exporter安装
注意:Node-Exporter需要安装到每台服务器上,用于采集服务器CPU、内存、磁盘、文件系统、网络等基础资源指标。
1、下载地址:Node-Exporter官方github网站,选择1.7.0版本的软件包下载并上传至服务器。
wget --no-check-certificate https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-arm64.tar.gz .2、当前目录下进行解压:
tar -zxvf node_exporter-1.7.0.linux-arm64.tar.gz3、执行以下命令,创建Node-Exporter运行用户:
useradd -M -s /sbin/nologin node_exporter4、将解压后的二进制文件复制到/usr/local/bin目录下,并修改权限:
cp node_exporter-1.7.0.linux-arm64/node_exporter /usr/local/bin/
chmod 755 /usr/local/bin/node_exporter
chown root:root /usr/local/bin/node_exporter5、执行以下命令,创建node-exporter.service文件:
cat > /etc/systemd/system/node-exporter.service << EOF
[Unit]
Description=Prometheus Node-Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=node_exporter
Group=node_exporter
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=:9100
Restart=always
RestartSec=2
[Install]
WantedBy=multi-user.target
EOF说明:
--web.listen-address=:9100 代表Node-Exporter默认监听 9100 端口。
6、执行以下命令,重新加载systemd配置,并启动Node-Exporter服务:
systemctl daemon-reload
systemctl enable node-exportersy
stemctl start node-exporter7、查看Node-Exporter服务状态:
systemctl status node-exporter若服务状态为active (running),表示Node-Exporter已正常启动。
8、服务启动后,确保可访问如下地址获取Node-Exporter的输出信息:
http://$ip:9100/metrics其中,$ip以当前鲲鹏服务器IP地址为准。若无法访问,请确认服务器防火墙已放通9100端口,或根据现场安全要求配置对应访问策略。
2.2.1.2 NPU Exporter安装
注意:NPU Exporter需要安装到每台推理服务器上。
1. 下载地址:链接,选择对应版本的软件包下载并上传至服务器:
2. 当前目录下进行解压:
unzip Ascend-mindxdl-npu-exporter_7.1.RC1_linux-aarch64.zip3. 执行以下命令,创建npu-exporter.service文件:
cat > /etc/systemd/system/npu-exporter.service << EOF
[Unit]
Description=Ascend npu exporter
Documentation=hiascend.com
[Service]
ExecStart=/bin/bash -c "/usr/local/bin/npu-exporter -ip=$IP -port=8082 -logFile=/var/log/mindx-dl/npu-exporter/npu-exporter.log>/dev/null 2>&1 &"
Restart=always
RestartSec=2
KillMode=process
Environment="GOGC=50"
Environment="GOMAXPROCS=2"
Environment="GODEBUG=madvdontneed=1"
Type=forking
User=hwMindX
Group=hwMindX
[Install]
WantedBy=multi-user.target
EOF说明:
$IP以当前服务器IP为准
4. 事先准备:
a) 执行以下命令,创建用户
useradd -d /home/hwMindX -u 9000 -m -s /sbin/nologin hwMindX
usermod -a -G HwHiAiUser hwMindXb) 创建组件日志父节点
mkdir -m 755 /var/log/mindx-dl
chown root:root /var/log/mindx-dl若目录已经存在,请确认该目录权限是否正确。
c) 执行以下命令,创建 npu-exporter 日志目录
mkdir -m 755 /var/log/mindx-dl/npu-exporter
chown hwMindX:hwMindX /var/log/mindx-dl/npu-exporter若已经存在该目录,执行以下命令,确保文件夹权限正确
chmod -R 755 /var/log/mindx-dl/npu-exporter
chown -R hwMindX:hwMindX /var/log/mindx-dl/npu-exporter5. 创建npu-exporter.timer文件。通过配置timer延时启动,可保证NPU Exporter启动时NPU卡已就位。
vim /etc/systemd/system/npu-exporter.timer内容参考如下:
[Unit]
Description=Timer for NPU Exporter Service
[Timer]
OnBootSec=60s
Unit=npu-exporter.service
[Install]
WantedBy=timers.target6. 将解压后的二进制包复制到下/usr/local/bin目录下,并修改权限:
cp npu-exporter /usr/local/bin
chmod 500 /usr/local/bin/npu-exporter
chown hwMindX:hwMindX /usr/local/bin/npu-exporter7. 启动NPU Exporter服务
systemctl enable npu-exporter.timer
systemctl start npu-exporter
systemctl start npu-exporter.timer8. (可选)裸机上通过命令行启动NPU Exporter服务:
npu-exporter -ip $ip -port $port -containerd /var/run/docker/containerd/containerd.sock -endpoint /var/run/docker.sock9. 服务启动后,确保可访问网址 http://$ip:$port/metrics (注意关闭防火墙)获取NPU Exporter的输出信息。
2.2.1.3 Prometheus、Grafana安装
1. 从docker拉取Prometheus、Grafana镜像
docker pull prom/prometheus:v3.7.3
docker pull grafana/grafana:12.3.02. 下载所需资源:resource-monitor,进入网页后,点击右上角的“下载当前目录”进行下载,得到名为ascend-deployer-appliance_deployer-ascend_deployer-conf-monitor_plat_config-resource-monitor.zip的压缩包。
3. 解压压缩包,逐级点击目录,进入到ascend-deployer-appliance_deployer-ascend_deployer-conf-monitor_plat_config-resource-monitor\ascend_deployer\conf\monitor_plat_config\resource-monitor下可得到所有的配置文件。
unzip ascend-deployer-appliance_deployer-ascend_deployer-conf-monitor_plat_config-resource-monitor.zip
cd ascend-deployer-appliance_deployer-ascend_deployer-conf-monitor_plat_config-resource-monitor/ascend_deployer/conf/monitor_plat_config/resource-monitor配置文件清单见下表。
表1 配置文件清单
文件名称 | 文件作用 | 说明 |
|---|---|---|
npu_exporter.yml | Prometheus 的主配置文件,定义采集指标方式;关联告警规则文件 | 配置文件参数说明: scrape_interval:Prometheus采集指标数据的频率。 evaluation_interval:Prometheus对告警规则的检测频率。 job_name:npu-exporter和node-exporter。 targets:Prometheus抓取数据的IP+端口、 server:服务器别名,面板中用于表格行标识。 server_ip:服务器IP,面板中用于显示和筛选。 |
rules.yml | 定义 Prometheus 告警规则(触发条件、级别、描述) | 告警规则对应监控指标清单中出现的推荐告警阈值 |
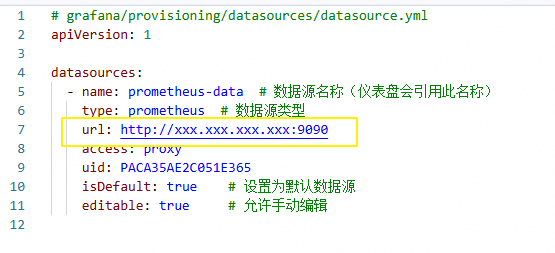
datasource.yml | 数据源配置 | 注意配置数据源名称为prometheus-data(不建议修改,后续的仪表盘会引用此名称)和Prometheus数据源地址 |
docker-compose.yml | 编排 Prometheus、Grafana 服务;管理容器端口、目录挂载、网络、权限; 定义服务依赖和启动规则 | 容器内的端口配置不要修改,Prometheus默认监听9090端口,Grafana默认监听3000端口号。对外暴露的端口可以修改 |
dashboard.yml | 定义仪表盘加载规则 | NA |
Alarm_Details.json | 告警界面 | NA |
NPU_Card_Details.json | NPU卡详情界面 | NA |
NPU_Card_List.json | NPU卡列表界面 | NA |
Overview_Page.json | 概览界面 | NA |
Server_List.json | 服务器列表界面 | NA |
all_monitoring_metrics_NPU.md | 全部监控指标清单 | 包括所有监控指标 |
important_monitoring_metrics_NPU.md | 重要监控指标清单 | 包含推荐使用的监控指标 |
文件夹结构图如下:
resource-monitor
├── docker-compose.yml
├── grafana
│ ├── dashboards
│ │ ├── Alarm_Details.json
│ │ ├── NPU_Card_Details.json
│ │ ├── NPU_Card_List.json
│ │ ├── Overview_Page.json
│ │ ├── Server_Details.json
│ │ └── Server_List.json
│ │
│ ├── data
│ └── provisioning
│ ├── dashboards
│ │ └── dashboard.yml
│ └── datasources
│ └── datasource.yml
├── prometheus
│ ├── data
│ ├── prometheus.yml
│ └── rules.yml
│
└── metrics_list
├── all_monitoring_metrics_NPU.md
└── important_monitoring_metrics_NPU.md4、创建grafana和prometheus组件的data文件夹
cd resource-monitor
mkdir -p grafana/data prometheus/data5. 修改prometheus和grafana相应文件夹权限,获取正确的读写权限
sudo chown -R 65534:65534 ./prometheus/
sudo chown -R 472:472 ./grafana/6. 修改prometheus/prometheus.yml中的node-exporter和npu-exporter两部分内容,填写实际的服务器ip、端口号、名称。prometheus.yml中默认配置为三组服务器,若纳管服务器数量小于3台的话,请删除多余的配置部分。

7、修改./grafana/provisioning/datasource/datasource.yml的url部分为Prometheus的endpoint。
8、启动所有容器
docker-compose up -d(可选)如启动容器时出现端口冲突,可修改docker-compose.yml中对应端口映射。
a) Prometheus默认端口9090冲突时,可将"9090:9090" 修改为"9390:9090",并同步修改./grafana/provisioning/datasource/datasource.yml中Prometheus访问地址;
b) Grafana默认端口3000冲突时,可将"3000:3000"修改为"3030:3000"。
如出现容器名称冲突,可修改docker-compose.yml中Prometheus或Grafana对应的container_name。
常用命令如下:
# 查看容器状态
docker-compose ps
# 修改 Grafana 登录密码
docker exec -it grafana-resource-monitor grafana-cli admin reset-admin-password $新密码
# 停止所有容器
docker-compose down9、通过以下地址访问:
a) Prometheus:http://$ip:9090
b) Grafana:http://$ip:3000
2.2.2(可选)自动化部署工具
自动化部署工具参考实践链接:参考实践
1、参考链接的2.1节【获取Ascend Deployer工具】获取自动化部署工具。
#clone代码仓的appliance_deployer分支
git clone https://gitcode.com/Ascend/ascend-deployer.git -b appliance_deployer2、参考2.2节【下载待安装软件包】下载监控平台相关软件包。
cd ascend-deployer/ascend-deployer
#下载所需软件,如服务器上没有安装docker-compose,可在下方命令行的--download后加上DockerCompose
bash start_download.sh --os-list=<OS> --download NpuExporter,NodeExporter,MonitorPlat说明:
可通过执行which docker-compose确认环境上是否已安装docker-compose。
未安装:

已安装:

3、按如下步骤完成软件安装。
步骤一:参考2.4.3.4节【资源监控平台】配置配置文件。
vim conf/monitor_plat_config/npu_monitor_config.json请根据实际情况修改port和password的值,password的长度需大于4。
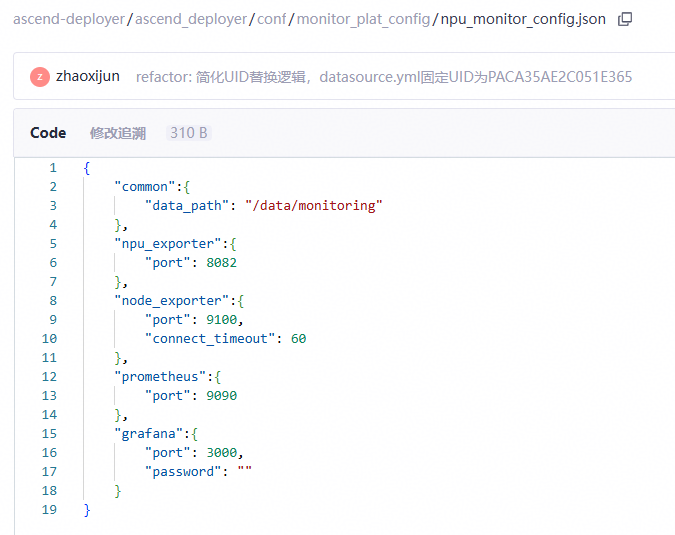
类别 | 参数 | 含义 |
|---|---|---|
common | data_path | 存储grafana和prometheus相关数据及配置文件的目录,请确保master节点上不存在该目录或该目录为空。 |
npu_exporter | port | npu-exporter的端口号 |
node_exporter | port | node-exporter的端口号 |
connect_timeout | 安装完毕后等待node-exporter服务就绪的最大时长 | |
prometheus | port | prometheus的端口号 |
grafana | port | grafana的端口号 |
password | grafana的登陆密码,登录账户默认为admin |
步骤二:在多机批量安装场景时,参考2.4.1节【配置服务器信息】进行配置。
登录Ascend Deployer执行机。在执行机上配置待安装的其他设备的IP地址、用户名。
进入ascend-deployer/ascend_deployer目录,编辑inventory_file文件。如下所示:
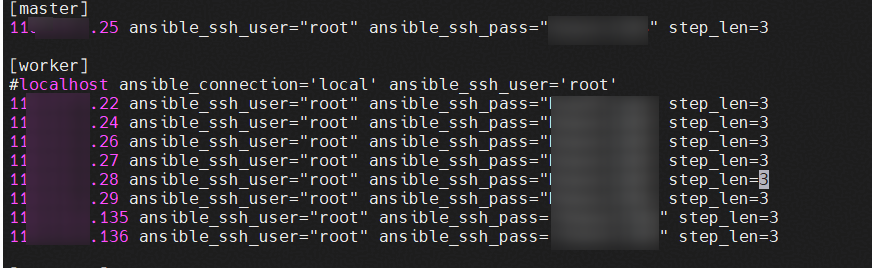
按照下表,完成[master]、[worker]相关参数的配置,填写完成后执行:wq保存退出。批量待安装场景下请明确配置IP地址,不建议使用localhost。
参数 | 是否可选 | 说明 |
|---|---|---|
IP | 必选 | 待安装服务器的IP地址。 |
ansible_ssh_user | 必选 | SSH登录远程服务器的账号,需要为root账号。 |
ansible_ssh_pass | 可选 | SSH登录远程服务器账号的密码。 如果配置了SSH密钥认证方式且root用户可以登录,则无需配置。 |
步骤三:参考2.4.4 【执行安装命令】的监控平台相关内容,使用自动化部署工具完成监控平台的安装部署。
#如需安装docker-compose,可在下方命令行的--install后加上docker_compose
bash install.sh --install npu_exporter_binary,node_exporter_binary,monitor_plat说明:
执行install.sh时,会在master节点的执行机上安装Prometheus和Grafana,worker节点的服务器安装部署node-exporter和npu-exporter(安装过程中,没有昇腾NPU设备的服务器将跳过npu-exporter安装)。
混合部署方式说明:把master节点信息复制到worker节点里,此时master节点也会安装node-exporter和npu-exporter。
3 平台使用指导与示例
3.1 界面介绍
3.1.1 概览
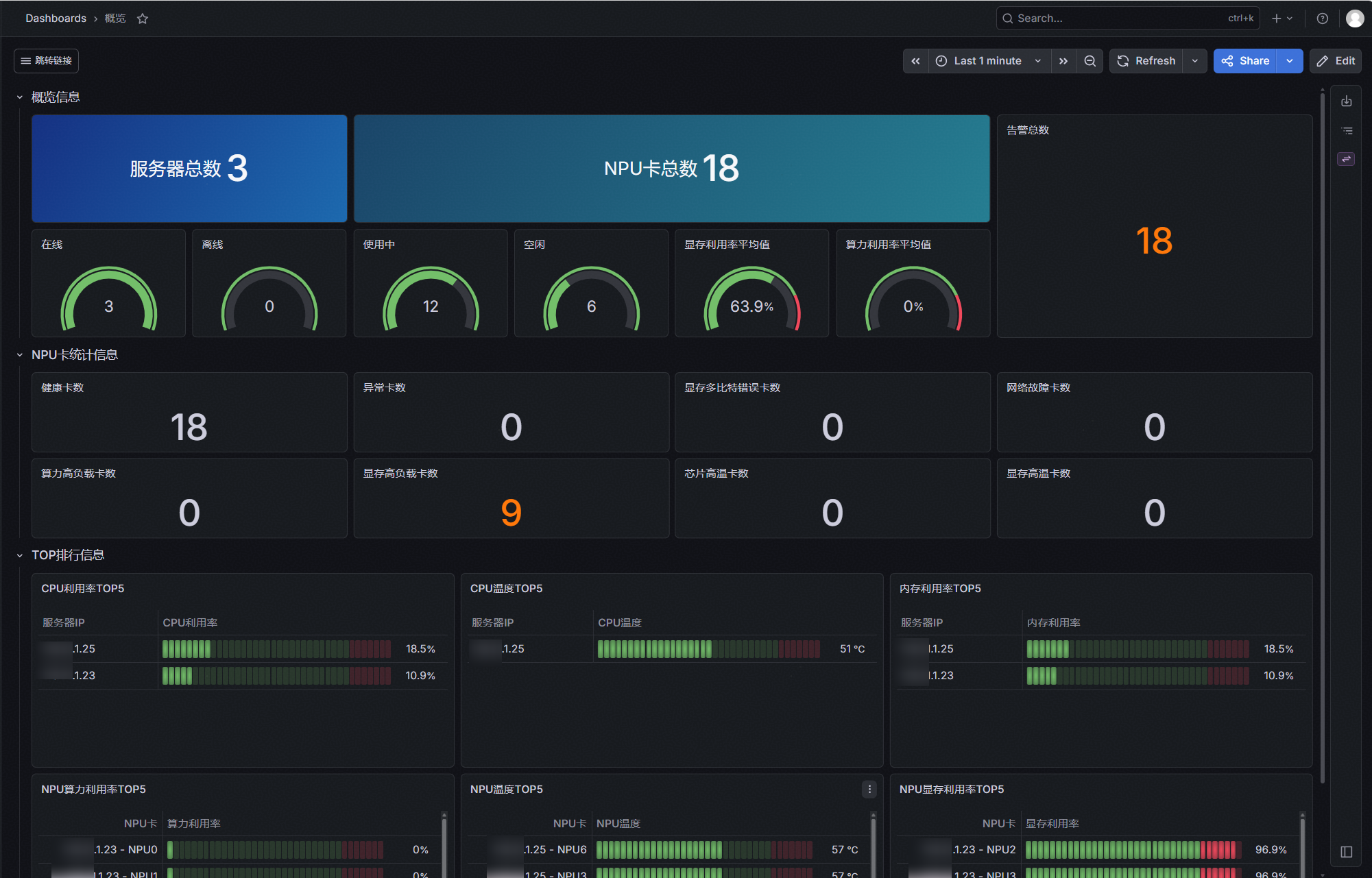
该界面主要用于集中展示服务器集群的整体运行状态与核心资源健康概况,为运维人员提供一站式的集群状态总览入口。具体包括:
- 告警总数:展示当前集群出现的告警总数,运维人员可及时感知到并点击跳转到告警详情页查看;
- 资源总量统计:推理服务器总数、NPU卡总数、健康卡数、已使用卡数,直观呈现集群的资源规模;
- 硬件健康状态:根据处理器运行状态、网络连通性、处理器核心温度等指标,分别统计各类状态的NPU卡数量;
- 算力负载统计:从算力与显存两大核心维度,统计不同负载区间的NPU卡数量,为集群资源调度与任务负载均衡提供数据支撑。
- TOP排行信息:根据采集到的各服务器上的CPU利用率、内存利用率、NPU算力利用率等基础资源指标,对服务器资源使用情况进行TOP5排序展示,帮助运维人员快速识别高负载节点、资源紧张节点和潜在异常节点,为资源调度、容量规划和故障排查提供参考。
通过上述多维度指标的整合展示,运维人员可快速掌握集群的告警情况,整体健康水平、资源使用分布及特殊机型的运行状态,为故障预警、资源优化和运维决策提供全面的数据依据。
图1 概览页示意图
3.1.2 服务器列表
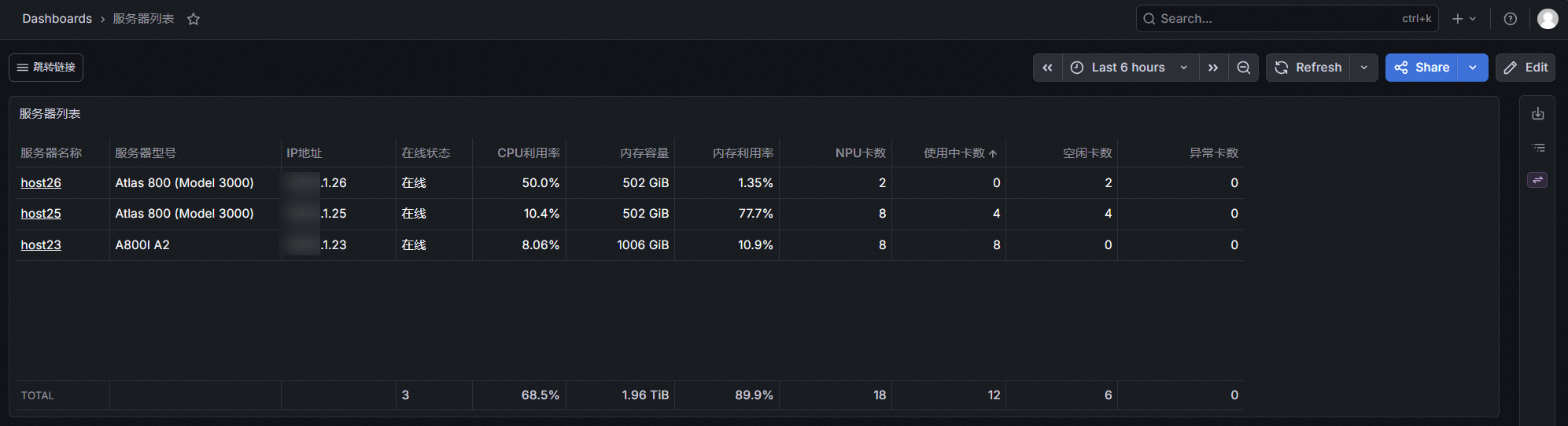
该界面主要用于集中展示昇腾 NPU 服务器集群的节点级精细化信息,为运维人员提供每台服务器的全方位运行详情与资源占用明细,便于快速定位单节点的异常状态与资源瓶颈。界面涵盖的核心信息如下:
- 服务器基础标识信息:清晰列出每台服务器的名称(可在Prometheus配置文件里修改)与服务器地址,作为节点唯一识别依据,方便快速关联物理设备;
- 服务器运行状态监测:明确标注服务器在线状态,通过 “在线 / 离线” 等状态分类,直观呈现节点的运行状态;
- NPU 卡资源维度统计:分别统计每台服务器上 NPU 卡总数、已使用卡数、未使用卡数,清晰反映单节点的算力资源占用比例与闲置情况,为任务调度与资源扩容提供数据支撑;
- 硬件健康状态细分指标:精准统计处理器不健康卡数,定位单服务器内存在处理器故障或性能异常的 NPU 卡,辅助运维人员快速开展故障排查工作。
通过该界面的节点级信息整合,运维人员可实现从集群总览到单节点详情的快速下探,掌握整体资源分布,大幅提升 NPU 集群的运维管理效率。
图1 服务器列表页示意图
3.1.3 服务器详情
该界面主要用于展示当前选择服务器的详细运行状态,为运维人员提供单节点维度的资源监控视图,便于快速了解服务器健康情况并定位异常问题。界面涵盖的核心信息如下:
1. 服务器基础标识信息:清晰列出服务器名称、服务器IP、服务器型号等基础信息,作为识别当前监控节点的基础依据,便于运维人员在多服务器场景下快速定位目标节点。
2. 服务器运行状态监测:明确展示服务器在线状态,通过“在线 / 离线”等状态分类,直观呈现节点当前是否可正常采集和访问,帮助运维人员及时发现节点不可达、采集异常或服务中断等问题。
3. 资源维度统计:分别统计该服务器的磁盘使用情况、磁盘读写速率、网络接收速率、网络发送速率等基础资源指标,清晰反映服务器存储资源、I/O性能和网络传输状态,为资源瓶颈分析、容量评估和异常排查提供数据支撑。
4. NPU资源监控:统计该服务器上的NPU卡总数、NPU卡状态(健康、异常)、NPU算力利用率、显存利用率、算力高负载卡数、显存高负载卡数、高温卡数等指标,提供服务器内NPU设备的整体运行视图,帮助运维人员及时掌握NPU资源使用情况和设备健康状态。
通过该界面的集中展示,运维人员可实现从服务器基础信息、在线状态、主机资源到NPU资源的逐层查看,快速判断单台服务器是否存在资源压力、采集异常或硬件风险,从而提升故障定位效率和日常运维管理能力。
图1 服务器详情页1
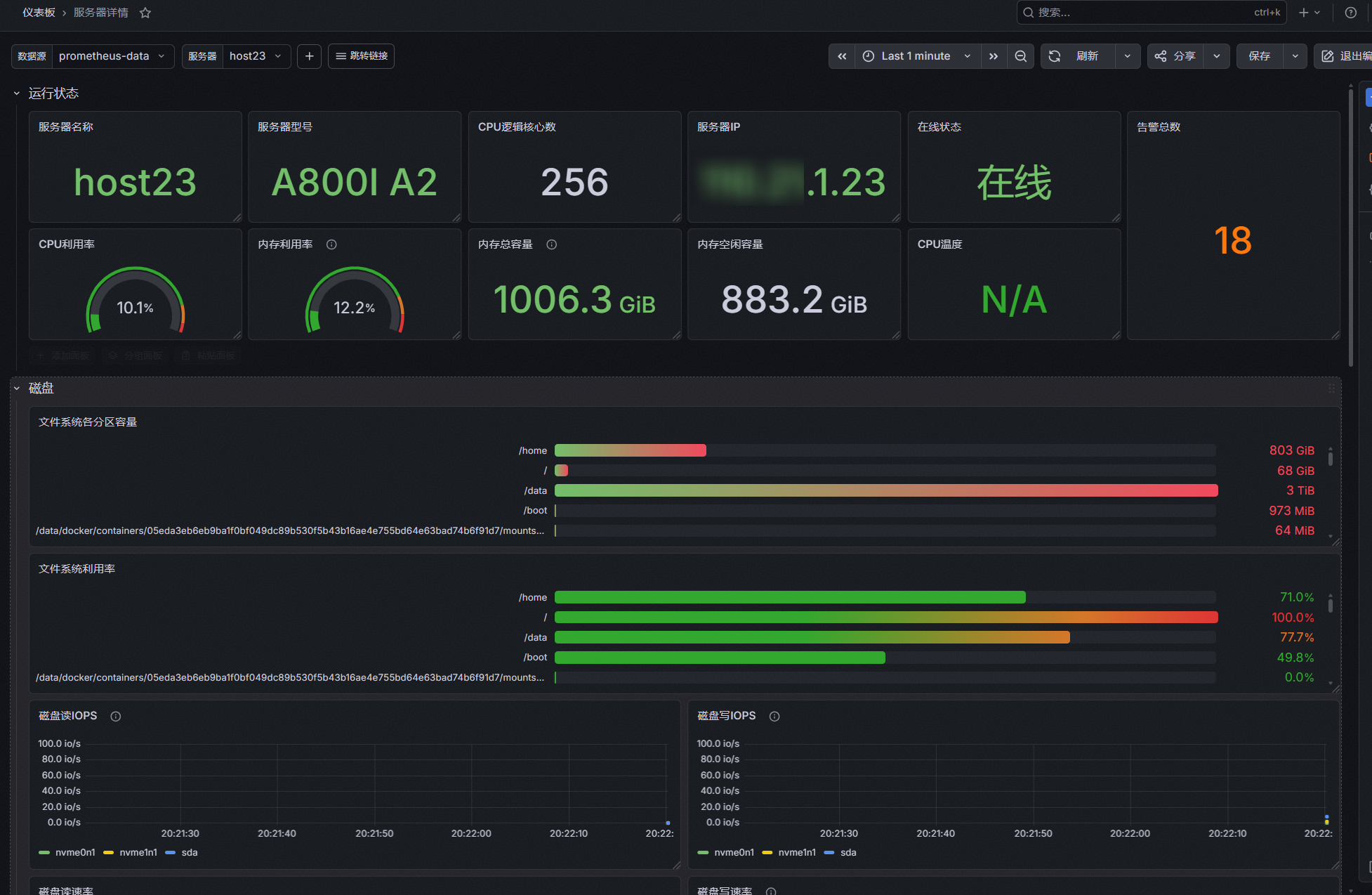
图2 服务器详情页2
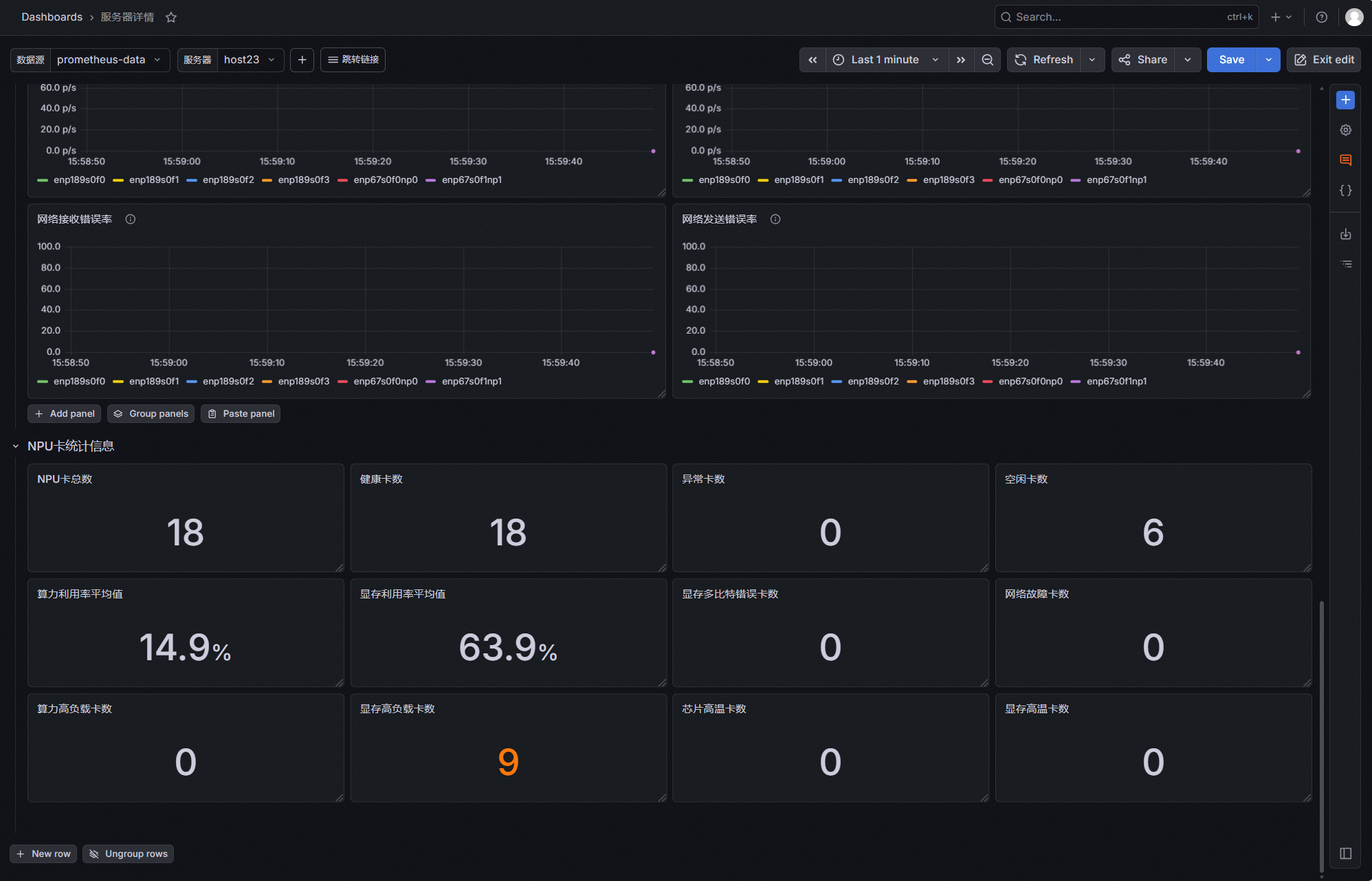
3.1.4 NPU卡列表
该界面主要用于展示昇腾 NPU 集群的单卡级监控,展示每张 NPU 卡的硬件信息、运行状态与性能负载详情,为运维人员提供全维度数据支撑,便于精准定位单卡故障、优化算力资源分配。界面核心信息如下:
- 基础身份标识信息:清晰标注每张 NPU 卡的卡号与所属服务器名称,建立 “服务器 - 单卡” 的层级关联关系,方便运维人员快速定位物理设备位置;
- 硬件健康核心状态:实时监测处理器健康状态;同步采集处理器温度、显存温度,预防因过温导致硬件出现降频或损坏;
- 算力与显存性能负载:统计单卡当前运行进程数,反映业务承载情况;实时展示NPU利用率与显存利用率两大核心性能指标,为任务调度与负载均衡提供决策依据。
通过该界面,运维人员可实现从集群总览到单卡详情的精准下探,全面掌握每张 NPU 卡的运行状态,快速识别异常卡的故障类型,提升昇腾 NPU 集群运维管理效率。
图1 NPU卡列表页示意图
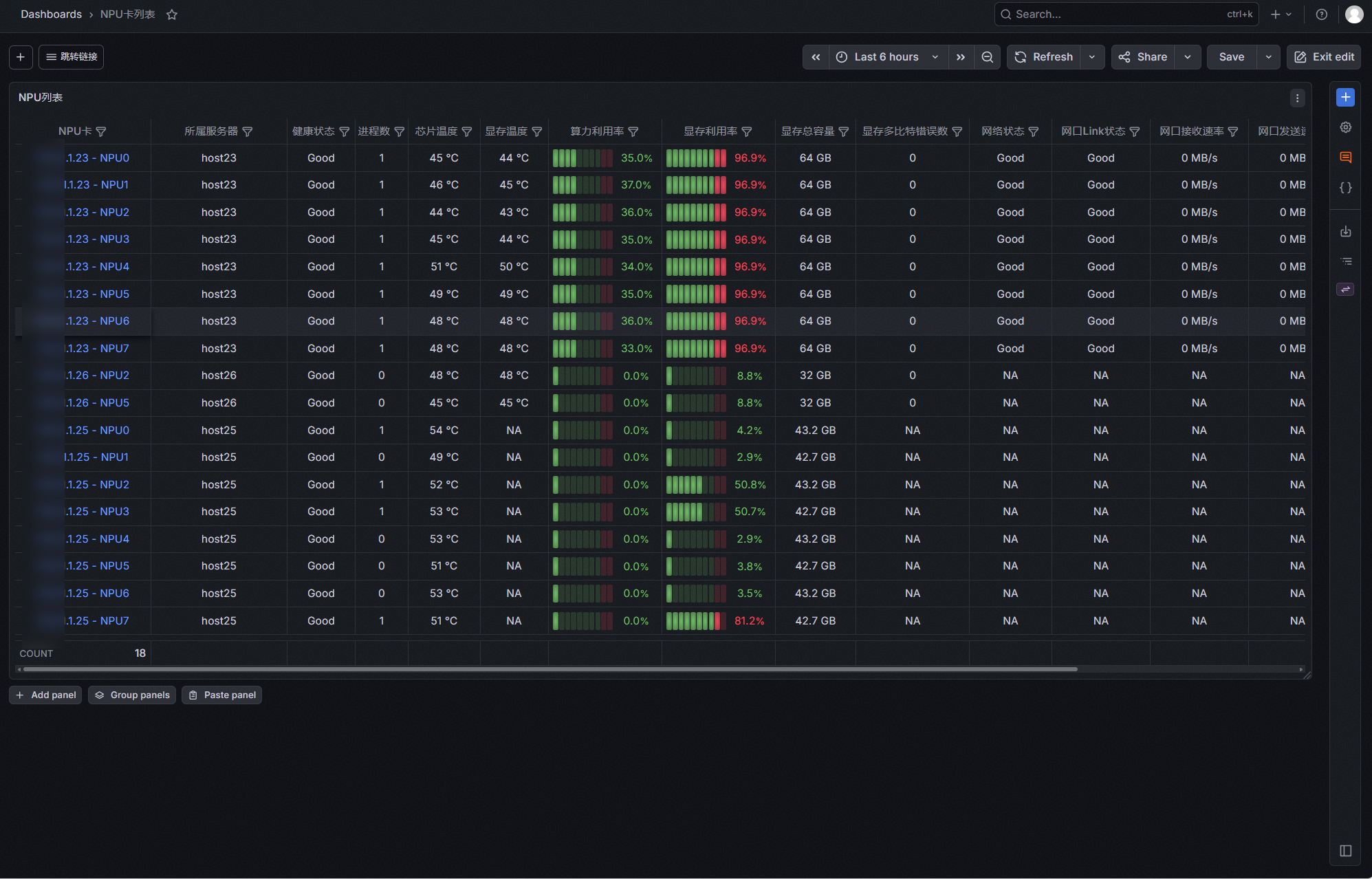
3.1.5 NPU详情
该界面主要用于展示单张 NPU 卡的全维度监控,清晰呈现卡级硬件状态,为运维人员定位单卡故障、分析性能瓶颈提供数据支撑,具体内容如下:
- NPU 卡状态信息区:全面展示当前选中 NPU 卡的核心硬件运行状态与性能负载趋势。
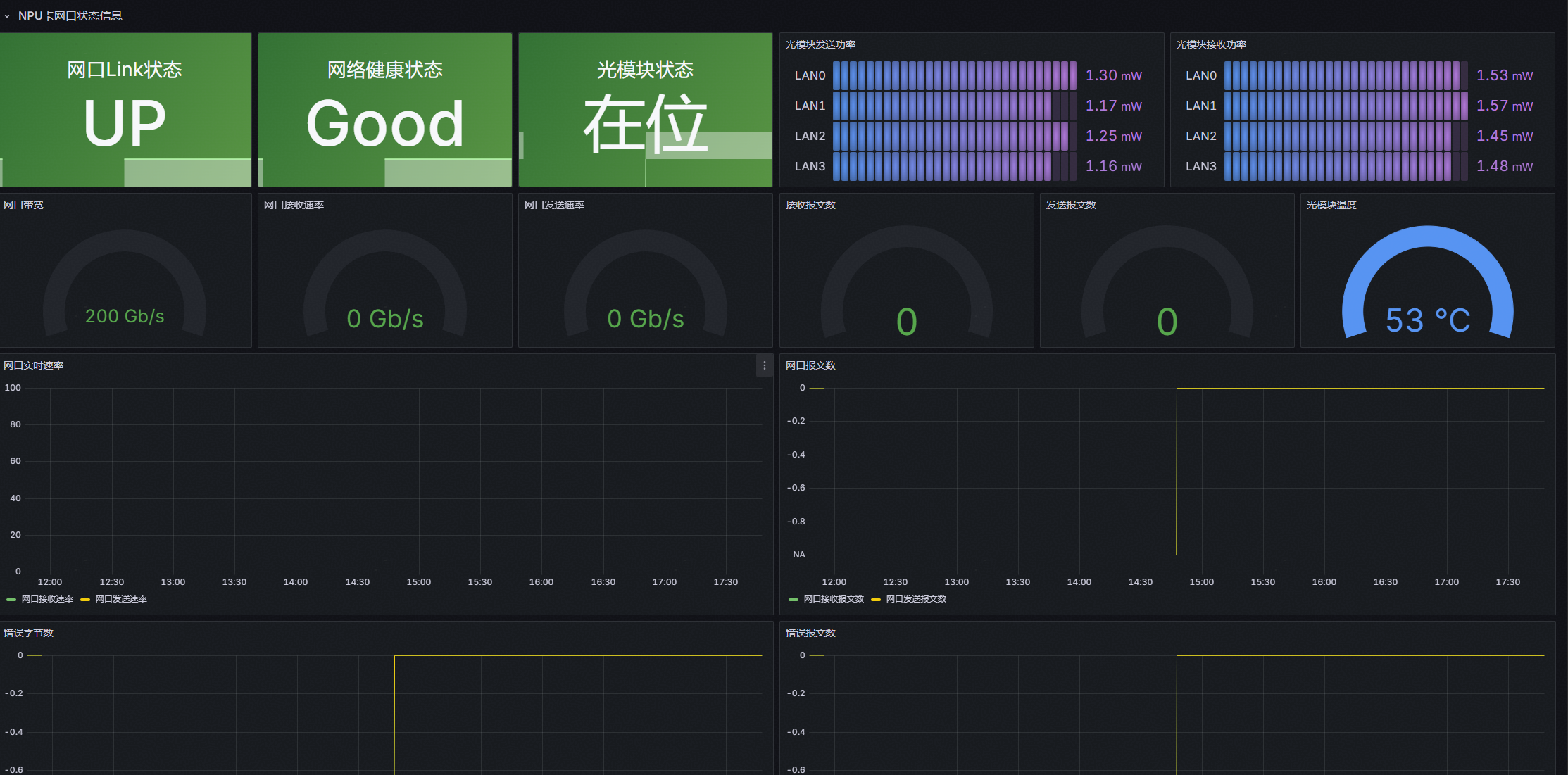
- NPU 卡网口状态信息区(800I A2 机型支持):针对 800I A2 机型的网络硬件特性,定制化展示网口与光模块状态数据。
图1 NPU详情页1
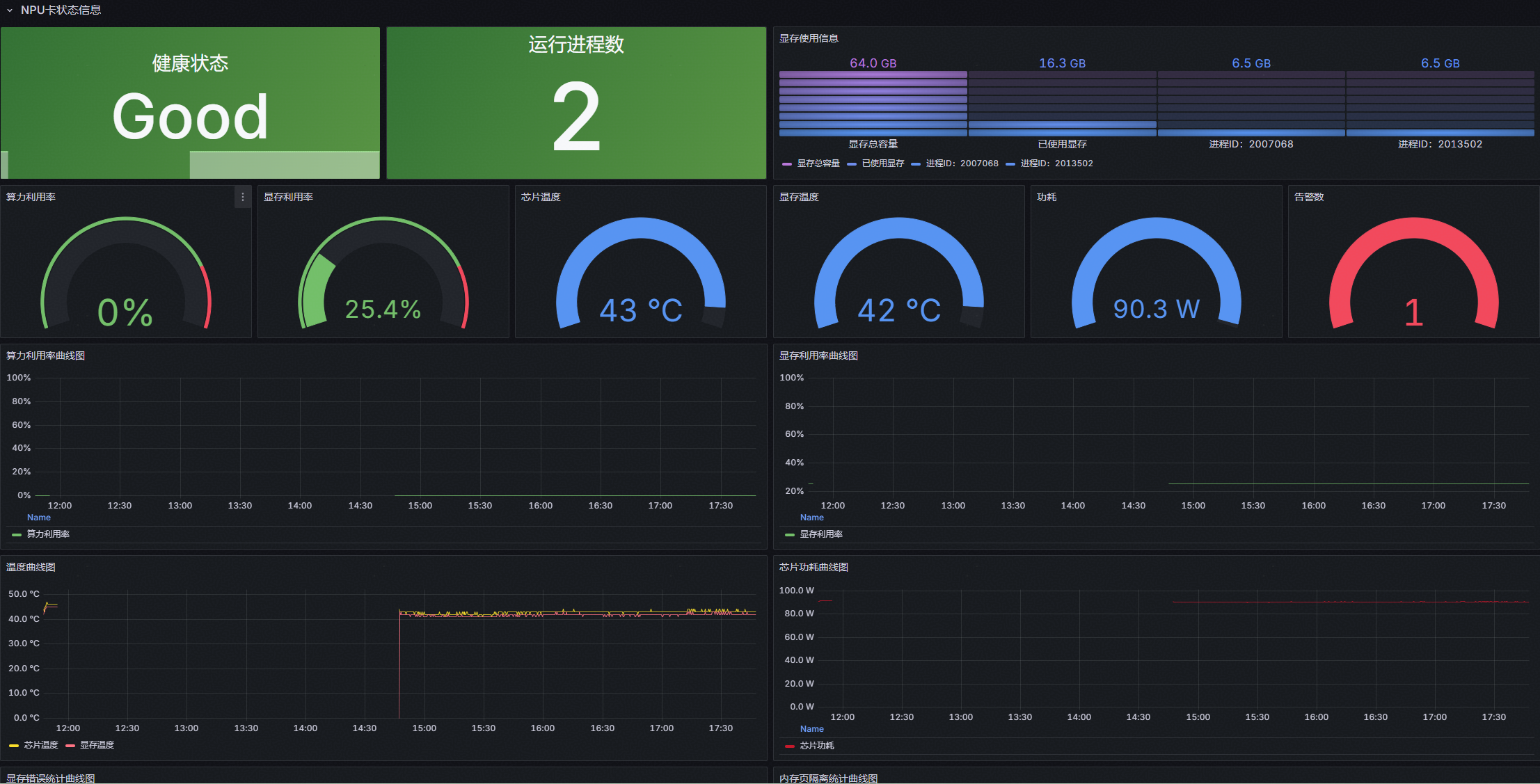
图2 NPU详情页2
3.1.6 告警详情
该界面主要用于展示集群的所有告警内容,具体内容如下:
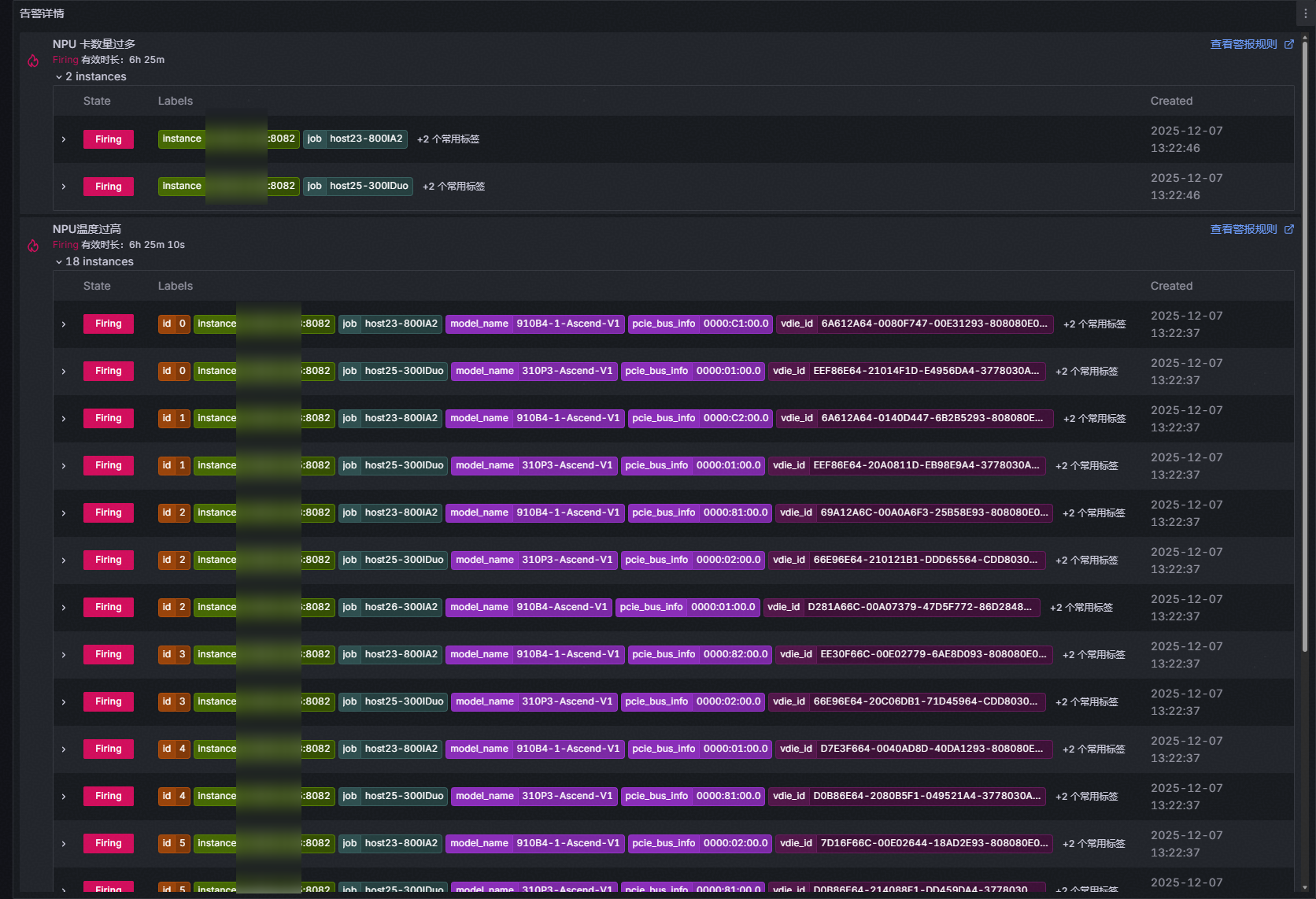
告警等级共三级:

3.2 添加指标
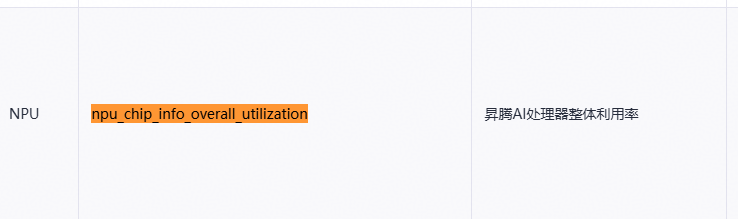
用户可查阅all_monitoring_metrics_NPU.md | GitCode按需选择并添加指标到面板中。
例如:在概览页中添加一个“npu_chip_info_overall_utilization”昇腾AI处理器整体利用率的指标监控。
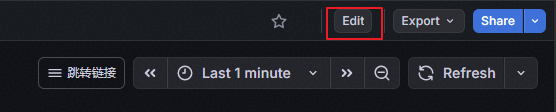
1、点击右上角“Edit”
2、点击“Add” -> “Visualization”
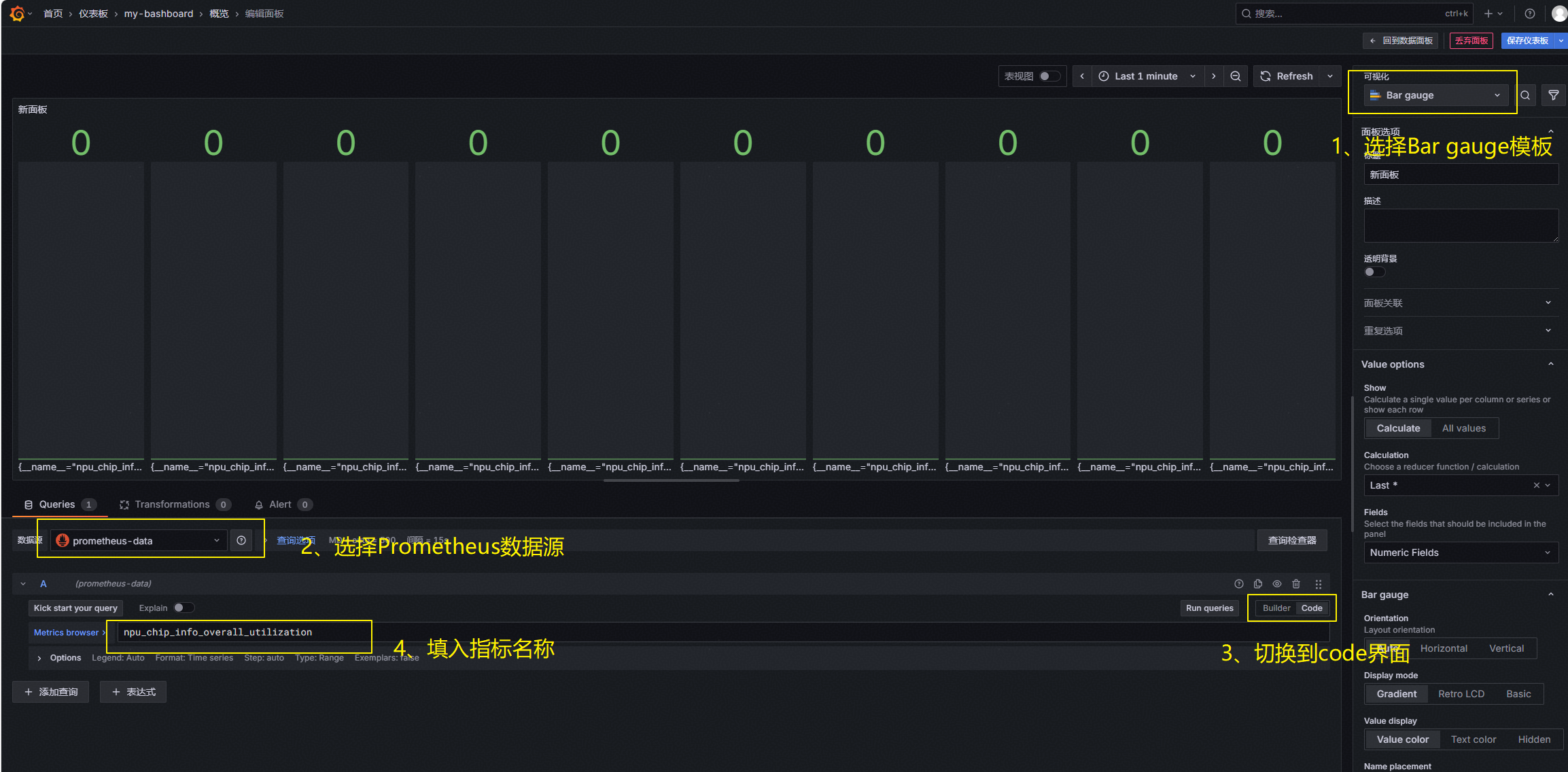
3、编辑页面,具体指标名称从all_monitoring_metrics_NPU.md | GitCode处查阅获取。
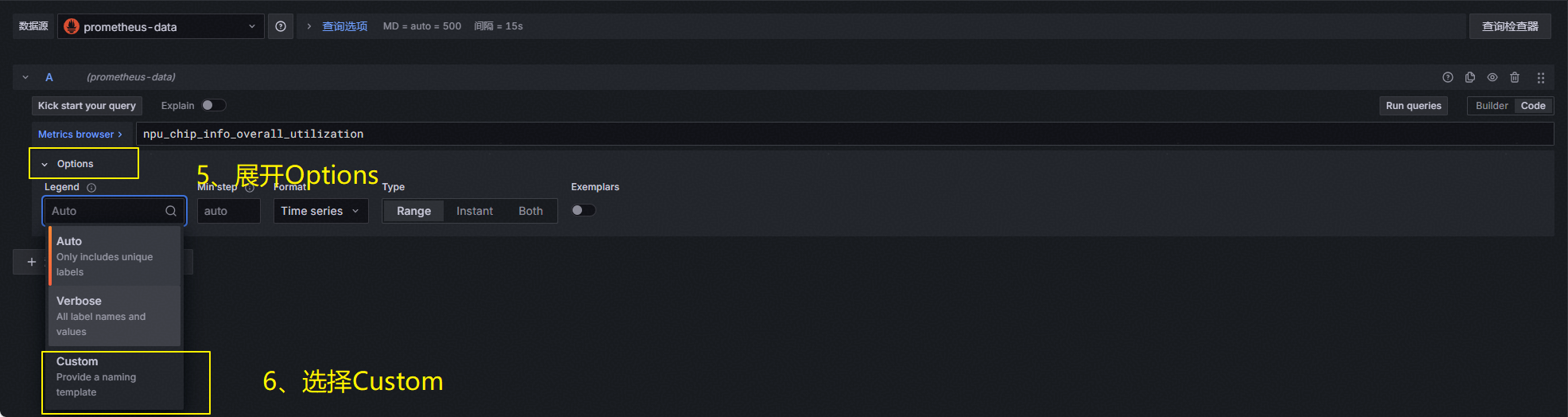
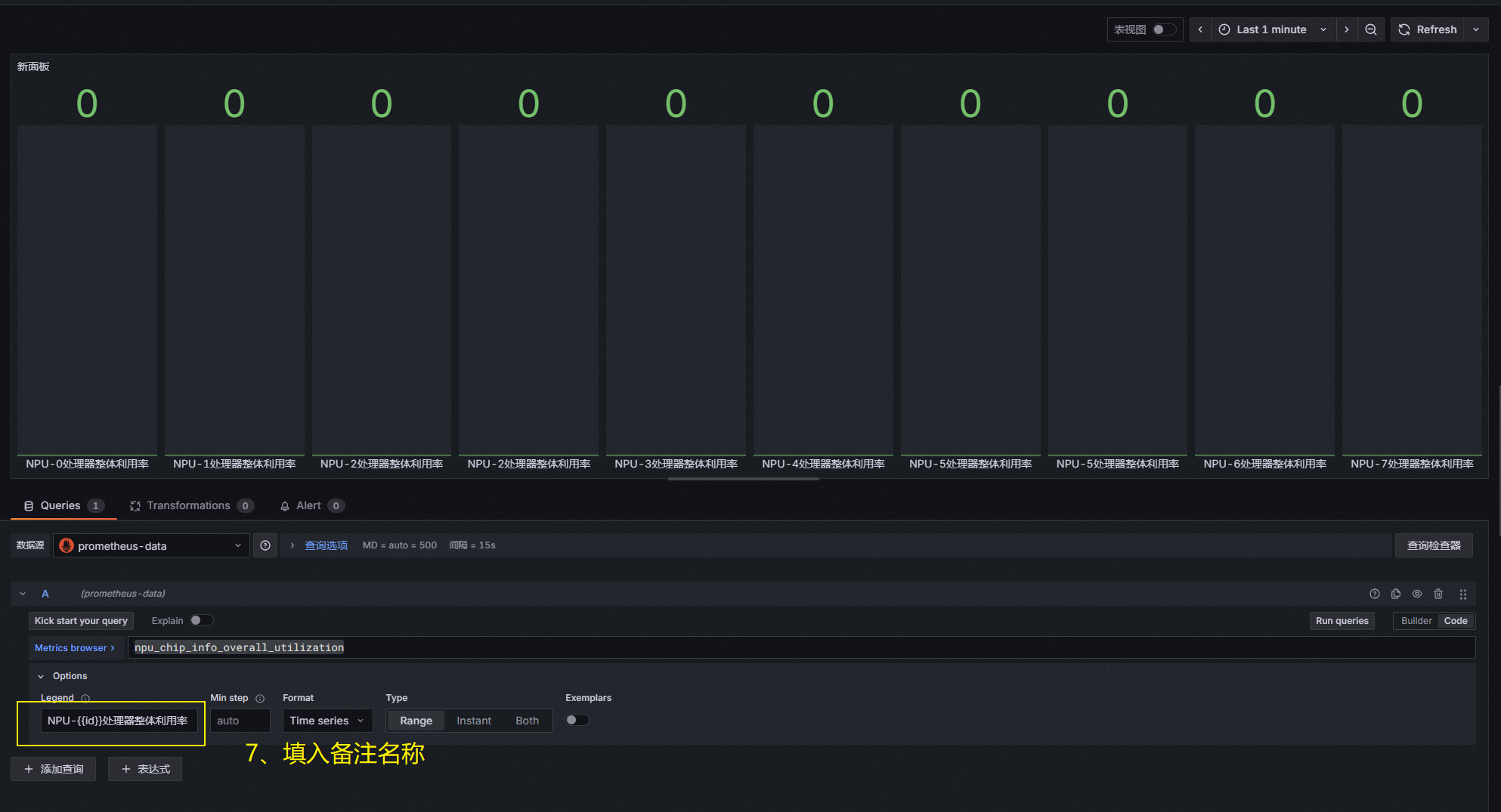
填入指标备注:NPU-{{id}}处理器整体利用率
4、点击右上角的“Save dashboards”保存退出,完成监控界面添加
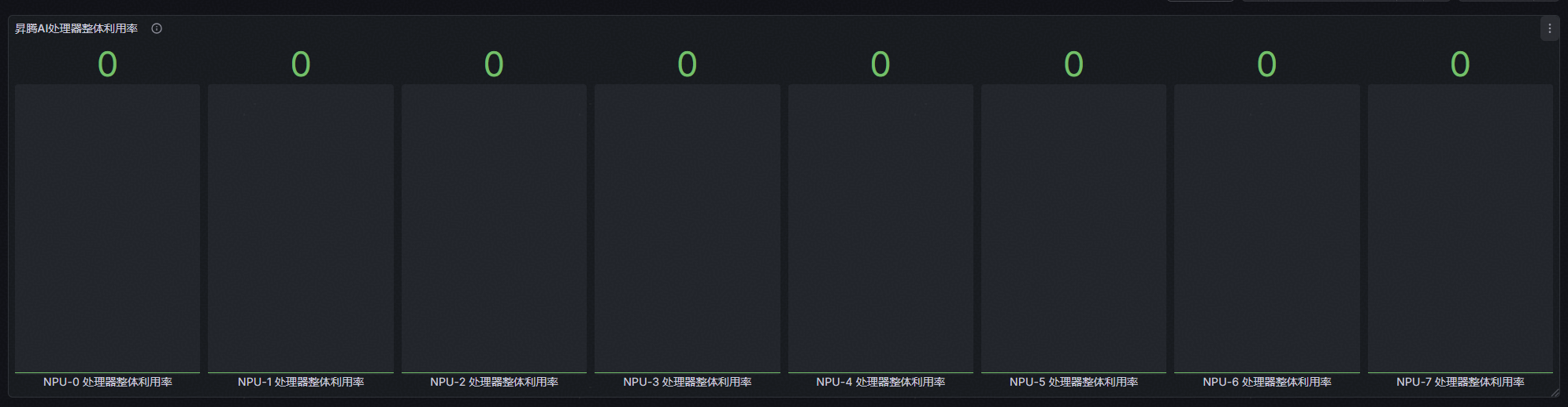
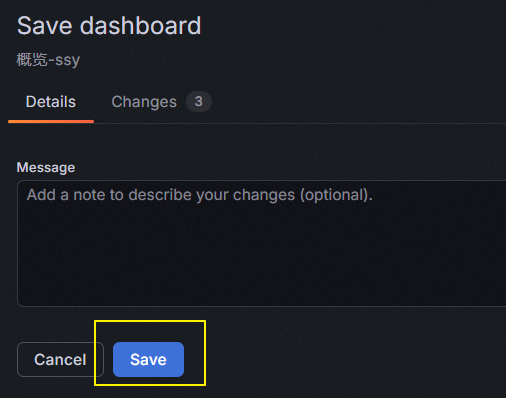
如果在保存面板时如下情况,说明当前监控面板文件保存在服务器上,我们无法直接保存。需要先点击“Copy JSON to clipboard”保存json代码到剪切板。
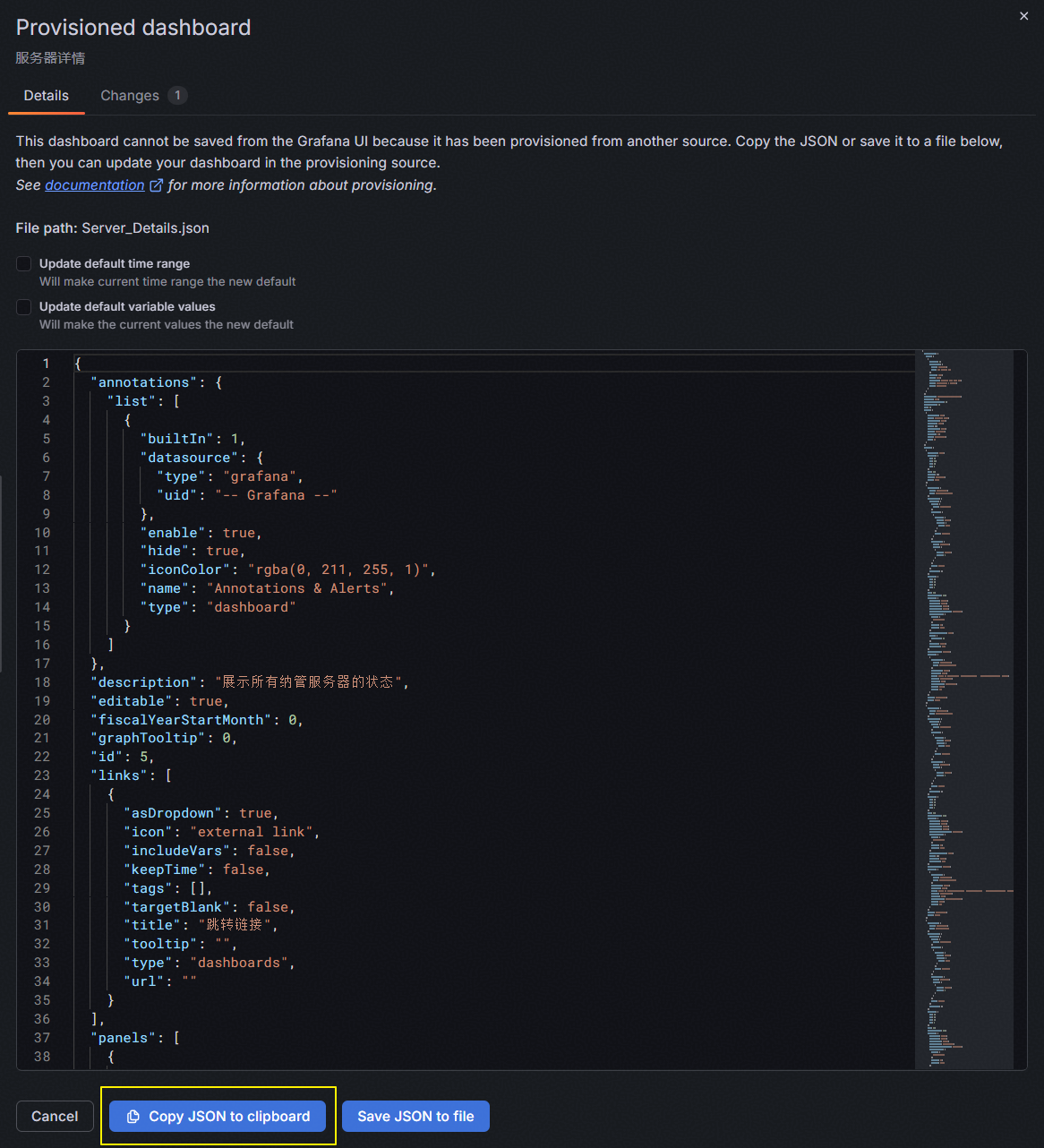
回到Dashboards主界面,点击“Import”进到导入界面。
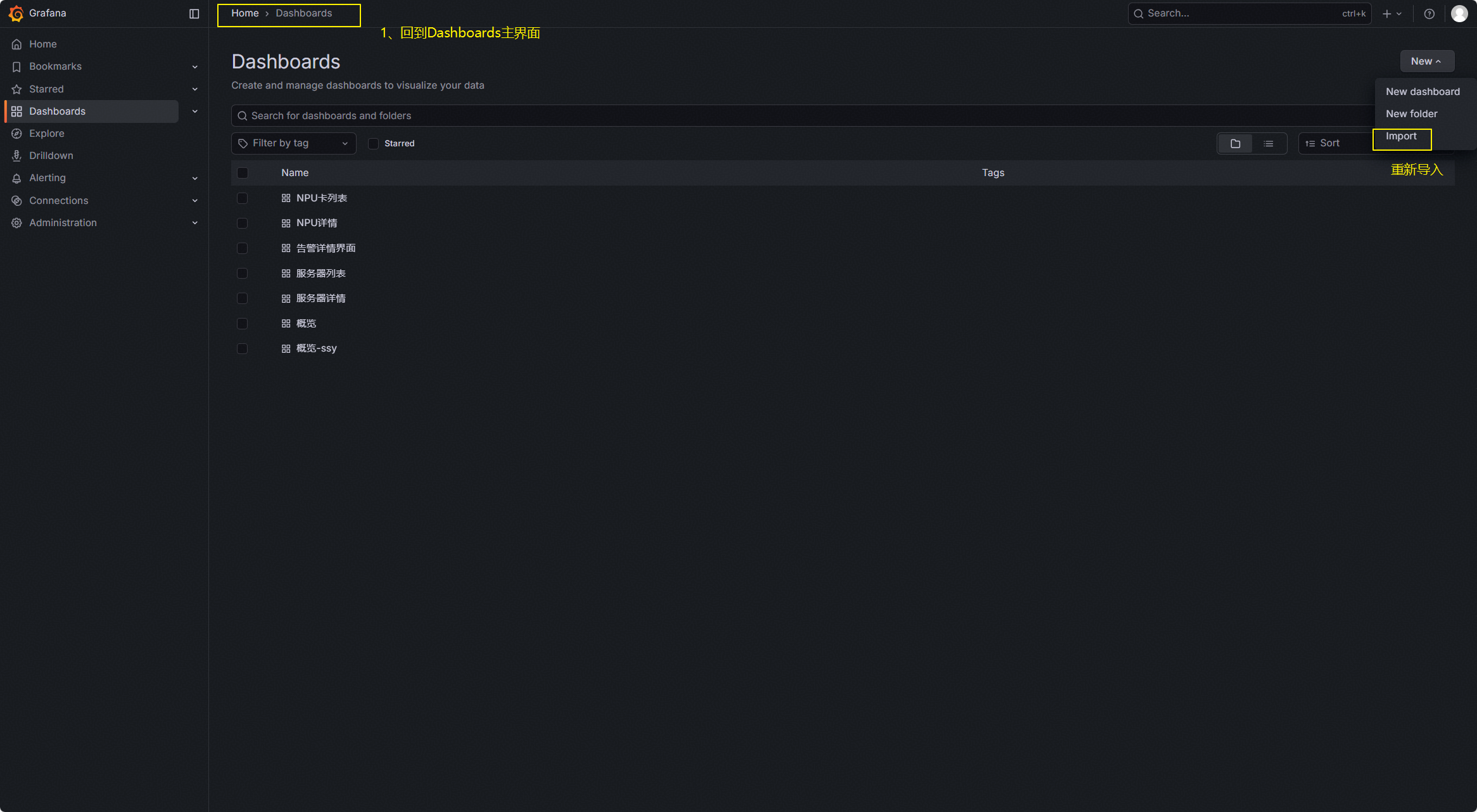
将刚才复制的json代码粘贴到下方的框中,点击“Load”键导入。
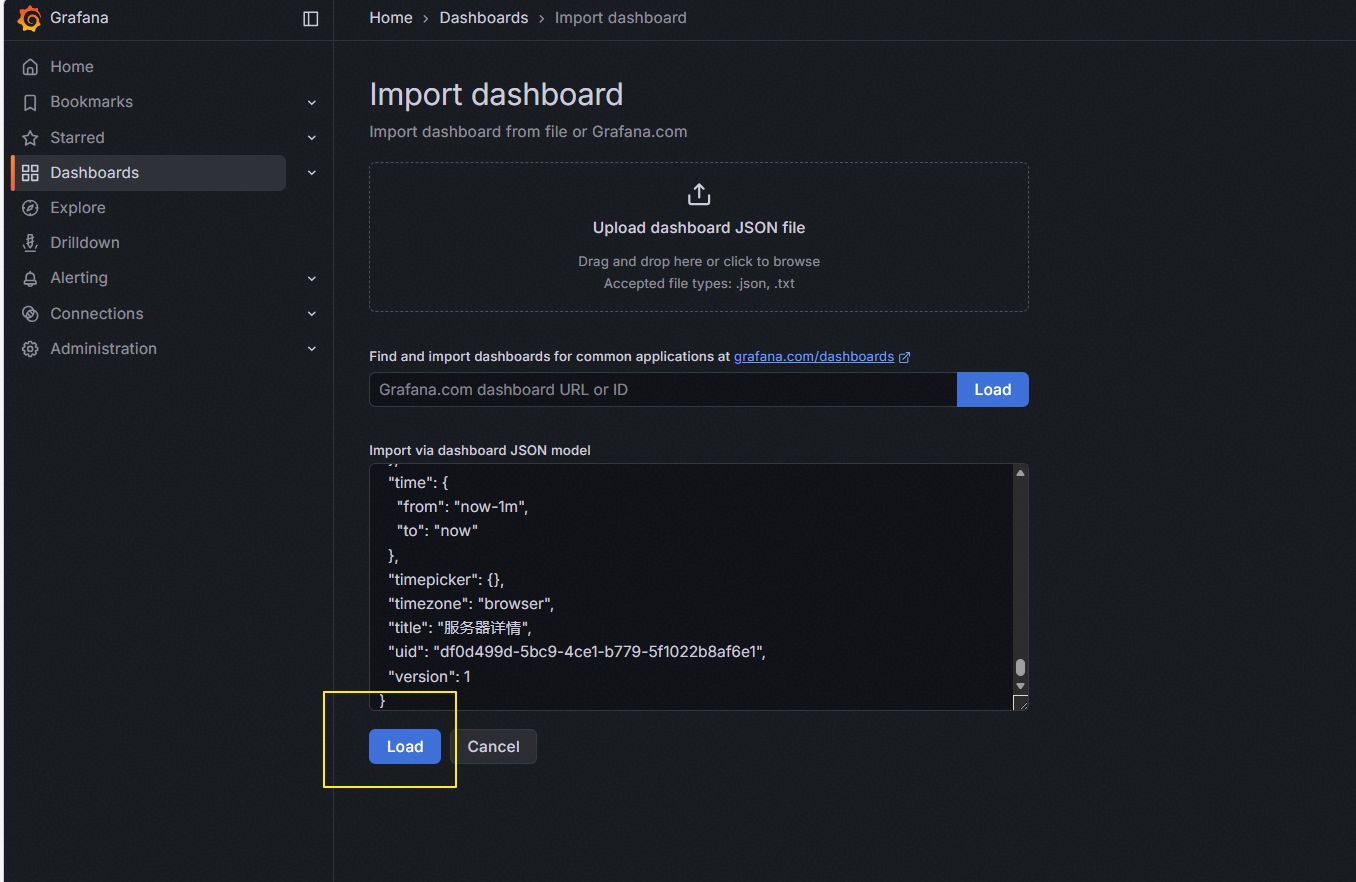
不能出现重复的面板名称和面板uid,需要修改。
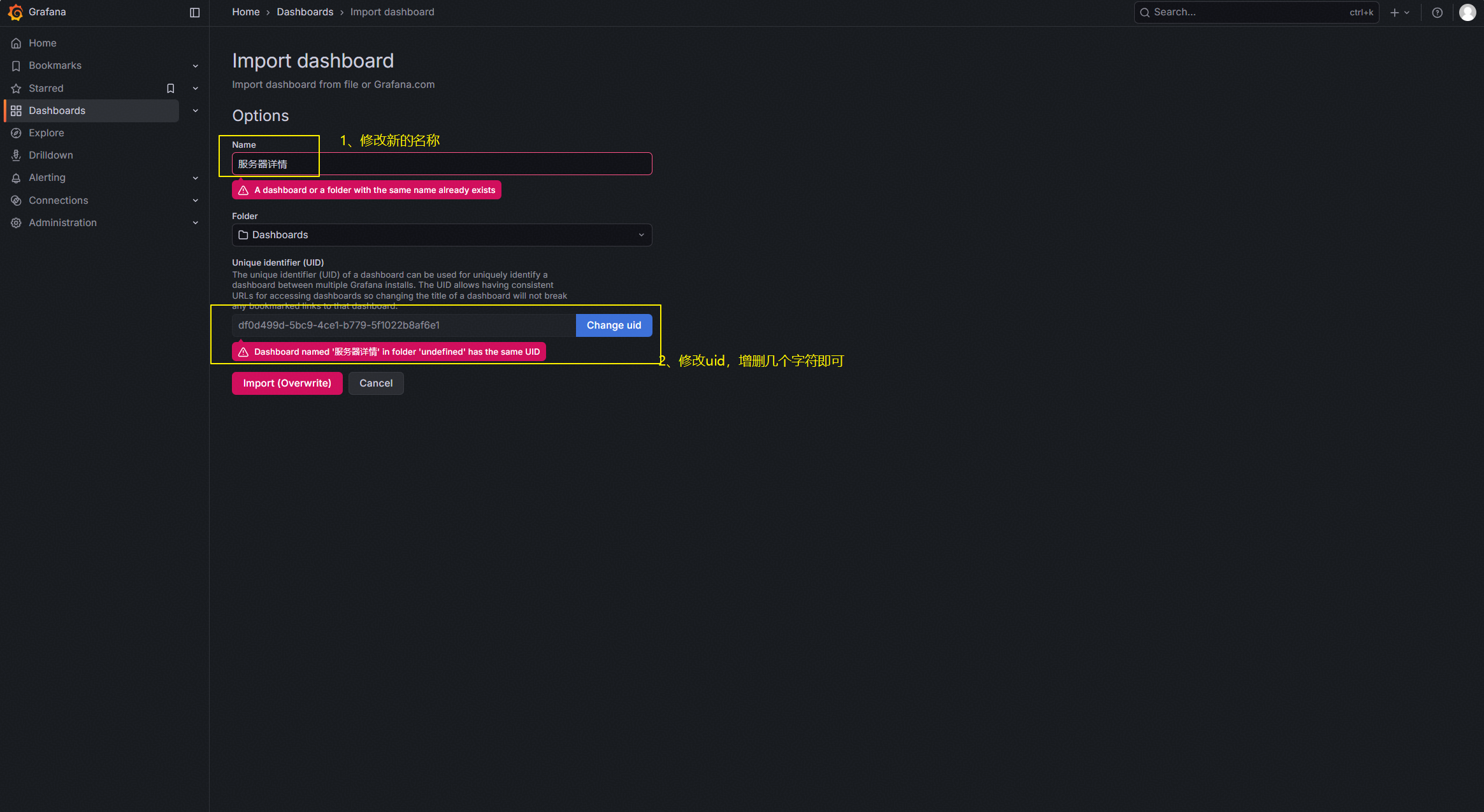
修改完成后点击“Import”。
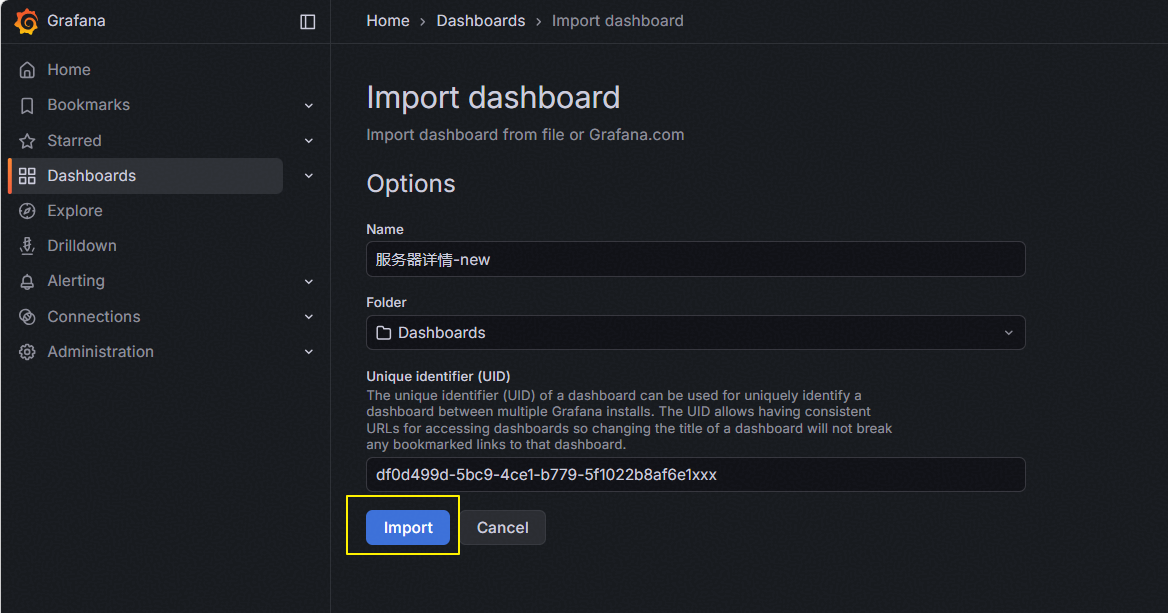
导入成功,面板正常。
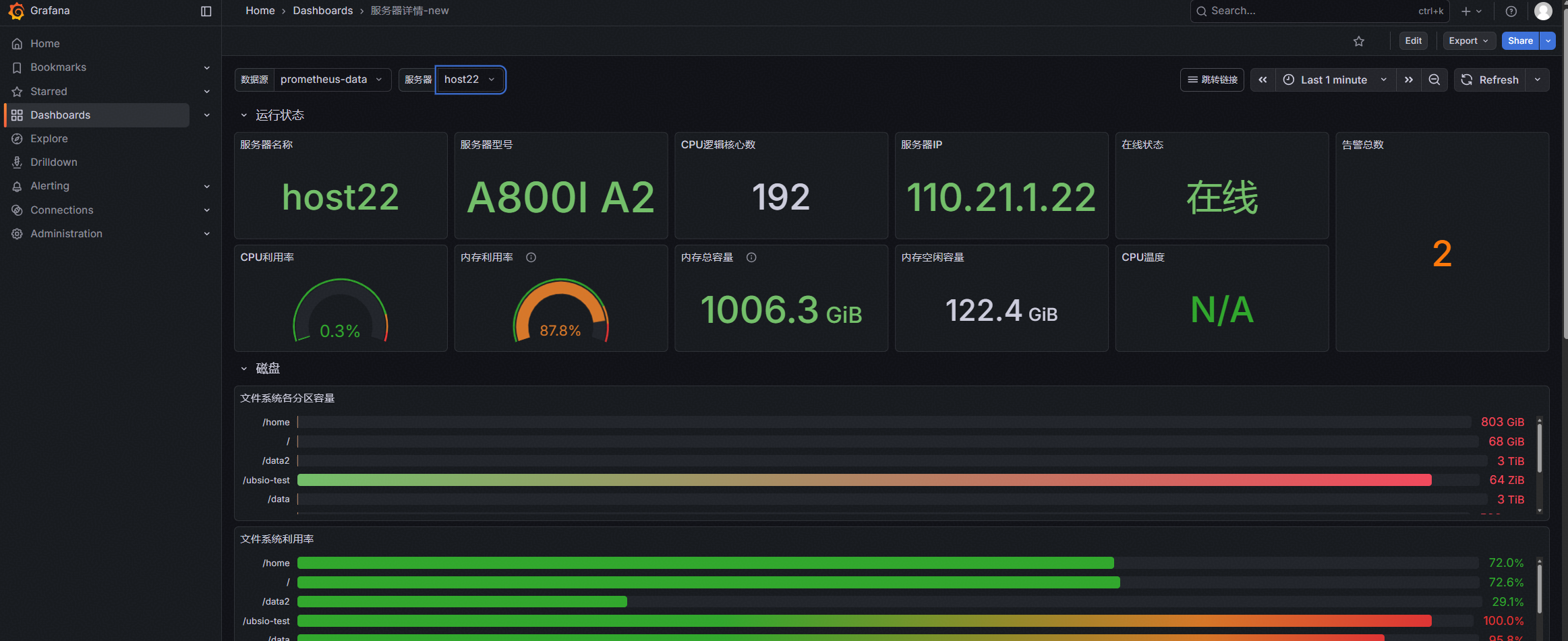
同时Dashboards主界面可看到我们刚刚导入的面板,后续可基于新导入的面板进行开发。
5、用户可参考示例用法来完成更多告警界面自定义开发
3.3 配置告警
可根据下面的方法查找告警规则配置文件rules.yml,并通过修改该配置文件来完成告警规则的增删。
1、查找告警规则配置文件位置,如下面截图的/data/monitoring8/prometheus/rules.yml。
docker inspect prometheus-resource-monitor | grep rules
2、添加告警规则,例如:(1)当NPU利用率持续10分钟超过80%时,发出告警信息;(2)显存利用率持续10分钟超过95%时,发出告警信息。并提示发送告警的NPU详细信息(NPU所属服务器IP,NPU卡序号)。
a)修改第1步找到的rules.yml文件,在末尾添加下面的代码
- name: NPU利用率监控
rules:
- alert: NPU利用率过高
expr: npu_chip_info_utilization > 0.8
for: 10m
labels:
severity: warning
annotations:
summary: "NPU 利用率过高( 实例 {{ $labels.instance }} - NPU {{ $labels.id }} )"
description: "利用率 = {{ $value }} ( > 0.8),超过 10 分钟。"
- alert: 显存利用率过高
expr: (npu_chip_info_used_memory / npu_chip_info_total_memory * 100) > 95
OR (npu_chip_info_hbm_used_memory / npu_chip_info_hbm_total_memory * 100) > 95
for: 10m
labels:
severity: warning
annotations:
summary: "显存利用率过高( 实例 {{ $labels.instance }} - NPU {{ $labels.id }} )"
description: "显存利用率 = {{ $value }} (>95%),超过 10 分钟。"b)修改完成后,保存配置文件,重启Prometheus容器使新规则配置生效。
c)访问Prometheus的Alerts界面,确认新配置的告警规则是否已生效。
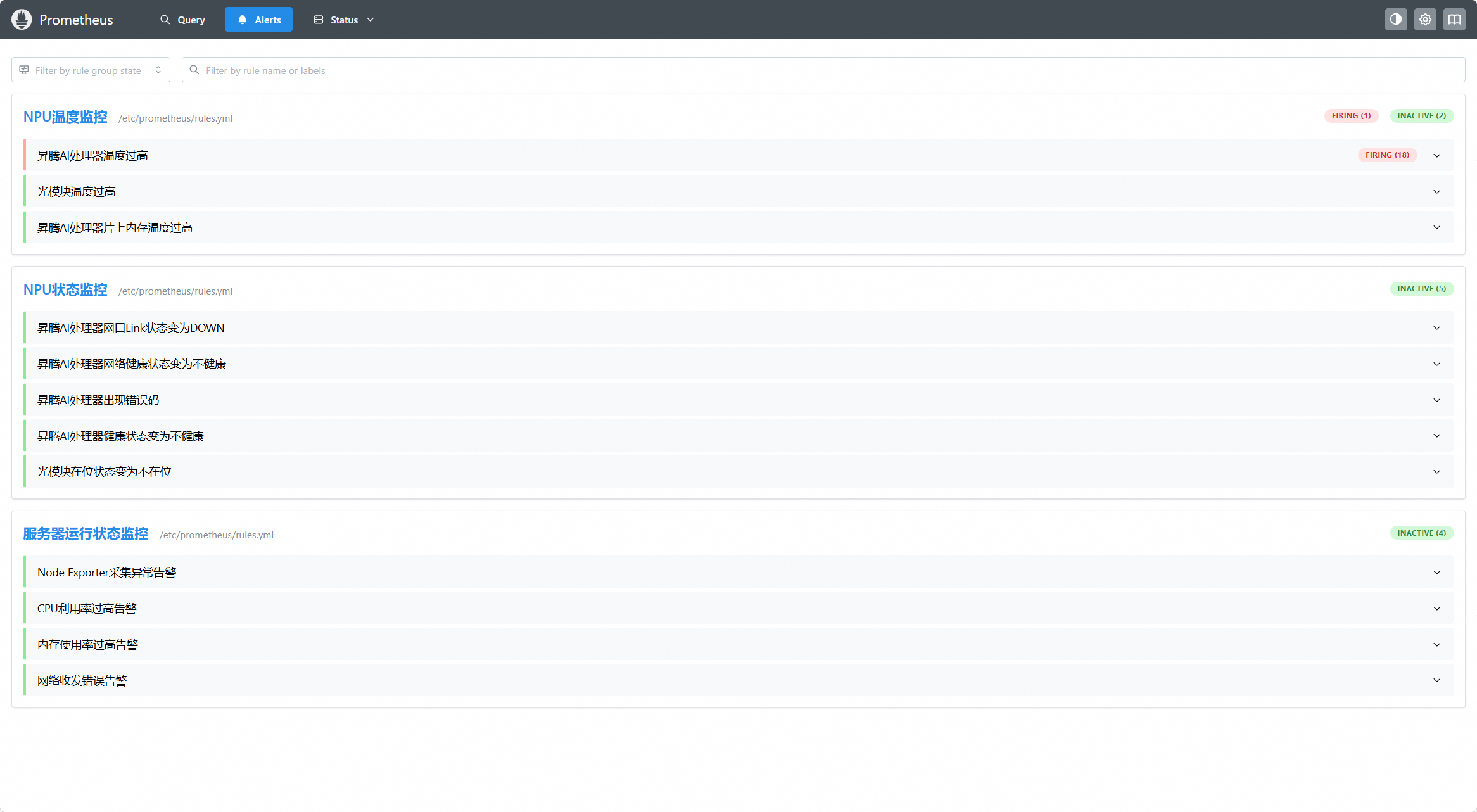
3、用户可参考示例写法来完成更多告警规则自定义开发。
附录-监控指标清单
(这里展示本参考实践推荐指标)
用户在监控系统部署、指标配置、告警规则编写的过程中,可按需查阅清单中的指标项,快速完成 Prometheus 采集规则、Grafana 面板可视化的配置工作。清单内容如下图所示:
类别 | 数据信息名称 | 数据信息说明 | 单位 | 支持的产品形态 | 优先级 | 是否告警 | 告警阈值 | 备注 |
|---|---|---|---|---|---|---|---|---|
Network | npu_chip_link_speed | 网口默认速率 | 单位:MB/s | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
Network | npu_chip_info_bandwidth_rx | 昇腾AI处理器网口实时接收速率 | 单位:MB/s | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
Network | npu_chip_info_bandwidth_tx | 昇腾AI处理器网口实时发送速率 | 单位:MB/s | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
Network | npu_chip_info_link_status | 昇腾AI处理器网口Link状态 | 取值为0或1 1:UP 0:DOWN | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | 由1变0时:告警 由0变1时:取消告警 | 800I A2支持 |
NPU | machine_npu_nums | 昇腾AI处理器数目 | 单位:个 | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 均支持 | ||
NPU | npu_chip_info_network_status | 昇腾AI处理器网络健康状态 | 取值为0或1 1:健康,可以连通 0:不健康,无法连通 | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | 0:告警 1:取消告警 | 800I A2支持 |
NPU | 第一个错误码为:npu_chip_info_error_code 其他错误码:npu_chip_info_error_code_X | 昇腾AI处理器错误码,X表示错误码的索引。 当昇腾AI处理器上没有错误码时,不会上报该字段。 说明: Prometheus场景:若该昇腾AI处理器上同时存在多个错误码,由于Prometheus格式限制,当前只支持上报前十个出现的错误码。X范围:1~9 Telegraf场景:最多支持上报128个错误码。 错误码的详细说明可以通过芯片故障码参考文档获取。 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | 错误码数量为非0时:告警 错误码数量为0时:取消告警 | 均支持 |
NPU | npu_chip_info_health_status | 昇腾AI处理器健康状态 | 取值为0或1 1:健康 0:不健康 | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | 0:告警 1:取消告警 | 均支持 |
NPU | npu_chip_info_power | 昇腾AI处理器功耗 | 单位:瓦特(W) | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 说明: 只有Atlas 推理系列产品为板卡功耗,其余产品为昇腾AI处理器功耗。 | 高 | 均支持 | ||
NPU | npu_chip_info_temperature | 昇腾AI处理器温度 | 单位:摄氏度(℃) | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | ≥105℃:告警 <103℃:取消告警 | 均支持 |
NPU | npu_chip_info_process_info | 占用昇腾AI处理器的进程的信息。 Prometheus场景:取值为进程使用的内存。 Telegraf场景:仅当没有进程占用昇腾AI处理器时上报,值为0。 | 单位:MB | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 均支持 | ||
NPU | npu_chip_info_process_info_num | 占用昇腾AI处理器的进程数量。 | 单位:MB | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 均支持 | ||
NPU | npu_chip_info_utilization | 昇腾AI处理器AI Core利用率 | 单位:% | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 均支持 | ||
DDR | npu_chip_info_used_memory | 昇腾AI处理器DDR内存已使用量 | 单位:MB | Atlas 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 | 高 | 300I Duo支持 | ||
DDR | npu_chip_info_total_memory | 昇腾AI处理器DDR内存总量 | 单位:MB | Atlas 训练系列产品 推理服务器(插Atlas 300I 推理卡) Atlas 推理系列产品 | 高 | 300I Duo支持 | ||
片上内存 | npu_chip_info_hbm_used_memory | 昇腾AI处理器片上内存已使用量 | 单位:MB | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_total_memory | 昇腾AI处理器片上总内存 | 单位:MB | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_ecc_single_bit_error_cnt | 昇腾AI处理器片上内存单比特当前错误计数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_ecc_double_bit_error_cnt | 昇腾AI处理器片上内存多比特当前错误计数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_ecc_single_bit_isolated_pages_cnt | 昇腾AI处理器片上内存单比特错误隔离内存页数量 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_ecc_double_bit_isolated_pages_cnt | 昇腾AI处理器片上内存多比特错误隔离内存页数量 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
RoCE | npu_chip_mac_rx_bad_pkt_num | MAC接收的坏包总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_mac_tx_bad_pkt_num | MAC发送的坏包总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_mac_tx_bad_oct_num | MAC发送的坏包总报文字节数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_mac_rx_bad_oct_num | MAC接收的坏包总报文字节数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_roce_rx_all_pkt_num | RoCE接收的总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_roce_tx_all_pkt_num | RoCE发送的总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_roce_rx_err_pkt_num | RoCE接收的坏包总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
RoCE | npu_chip_roce_tx_err_pkt_num | RoCE发送的坏包总报文数 | - | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
光模块 | npu_chip_optical_state | 光模块在位状态 | 取值为0或1 0:不在位 1:在位 | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas 900 A3 SuperPoD 超节点 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 由1变0时:告警 由0变1时:取消告警 | 800I A2支持 | |
光模块 | npu_chip_optical_tx_power_X (X范围为0~3) | 光模块发送功率 | 单位:mW | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas 900 A3 SuperPoD 超节点 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
光模块 | npu_chip_optical_rx_power_X (X范围为0~3) | 光模块接收功率 | 单位:mW | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas 900 A3 SuperPoD 超节点 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 800I A2支持 | ||
光模块 | npu_chip_optical_temp | 光模块温度 | 单位:℃ | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas 900 A3 SuperPoD 超节点 Atlas 800I A2 推理服务器 A200I A2 Box 异构组件 | 高 | 是 | ≥75℃:告警 <73℃:取消告警 | 800I A2支持 |
片上内存 | npu_chip_info_hbm_utilization | 昇腾AI处理器的片上内存利用率。 | 单位:% | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | A2 机型支持 | ||
片上内存 | npu_chip_info_hbm_temperature | 昇腾AI处理器片上内存的温度。 | 单位:°C | Atlas 训练系列产品 Atlas A2 训练系列产品 Atlas A3 训练系列产品 A200I A2 Box 异构组件 Atlas 800I A2 推理服务器 | 高 | 是 | ≥95℃:告警 <93℃:取消告警 | A2 机型支持 |