




一、概述
图像消消消应用中提供了两种目标消除的方法,逻辑结构如下所示。
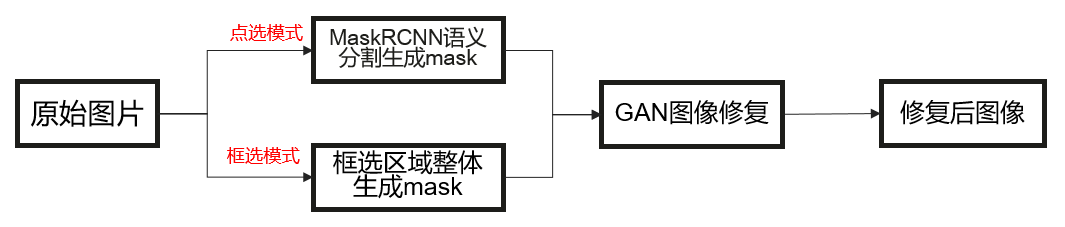
由上图可知,不管哪种模式,都需要生成需要消除区域的mask后,再调用GAN图像修复模型进行图像修复。但是这两种模式也都各有优劣,以下做一个简单的优势介绍。
点选模式:
优势:mask区域不包含其它背景,图像修复准确度高,对画面的割裂效果产生的影响最小。
劣势:mask区域依赖于MaskRCNN识别的物体种类,当前可以识别80种物体。从而导致部分区域无法选择修复。
框选模式:
优势:不需要多调用一个模型,整体生成时间较快。所有图像内容均可选择。
劣势:mask区域会选择到目标区域周边环境,对生成后的画面可能会造成一定的画面割裂。
对于GAN图像修复部分,由于内存限制,基于数据驱动的图像修复方法通常只能处理小于1k(1920 X 1080)的低分辨率输入,而目前主流相机拍照几乎都已经超过了4K,单纯对低分辨率修复后的结果进行上采样,只会产生较大但是模糊的结果,根本无法达到高清修复的结果。
Qiang Tang等人提出的算法Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting另辟蹊径,由生成器得到低分辨率的修复好的图像,然后通过残差聚合模块得到高频残差,最后合并高频残差合低分辨率修复结果得到高分辨率修复图像,最终的效果也相当惊艳。
本应用在Ascend310上基于CANN AscendCL实现,指定修复区域,可以对超高像素图像进行修复,特别是通过将残差聚合模块转化为大矩阵乘以后充分利用了Ascend的算力优势, 即使对于4K图像也能达到秒级修复。
综上所述,在不同场景下可以选择不同的模式以达到快速图像消消消的体验目的。如针对路人消除等可以直接点选消除,省时省力的同时还可以获取到精准的修复效果图。在破损图像修复或图像干扰信息消除时可以进行框选消除,即时获取修复后的图片。
二、模型介绍
本应用共使用到两个模型,分别为maskrcnn模型和GAN图像修复模型,模型理解分别如下所示。
1、GAN图像修复模型
下图为高清图像修复方法的整体框架,其中,顶部图为CRA机制流程,底部图为生成器的架构:
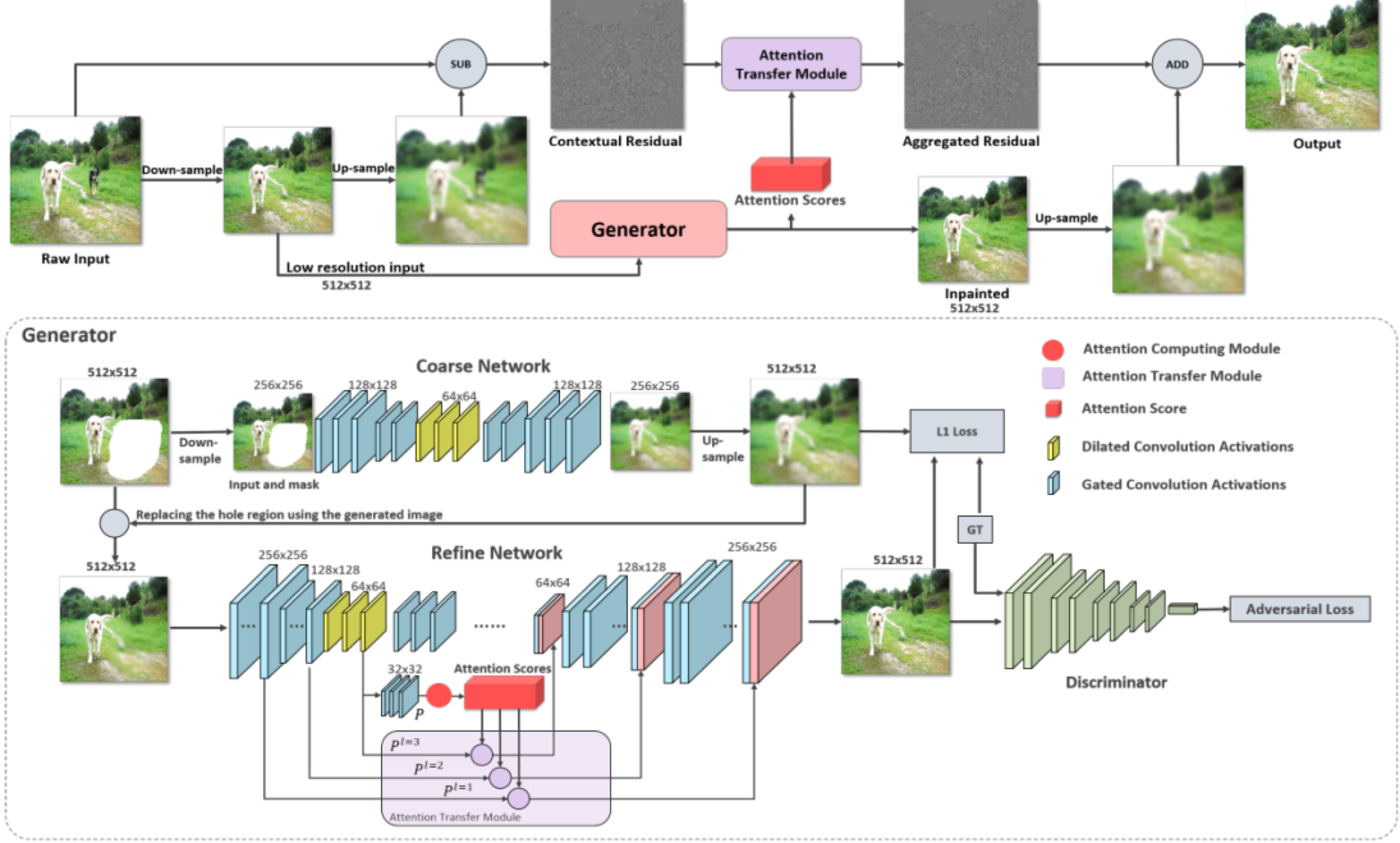
生成器结构:
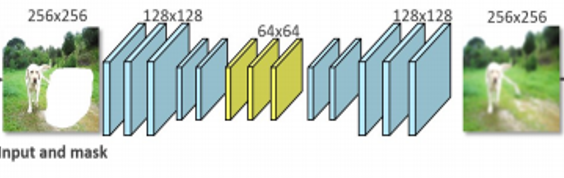
生成器包括粗(Coarse network)到精(Refine network)两个自编码器网络架构。第一阶的自编码器是一个粗糙的自编码器,用来生成待修复部分的图像的大体轮廓,自编码器在训练时记录了大量的图像信息,即使图像部分缺失,也具有重建图像的能力。但自编码器生成的图像会模糊,这是自编码器的固有缺陷。假定擦除区域的图像是Mask内的图像,此时自编码器修复出来的Mask内的图像会非常的模糊,之后再将该图像送入到第二阶的自编码器。
对于生成器,希望它尽可能生成真实清晰的图像,而判别器则希望尽可能的区分真实样本与生成样本,以促使生成器尽可能生成更真实清晰的图像。
由于处理的是高分辨率的图像,修补的图像可能还不那么清晰,接下来要用图像锐化的原理将图像修补的区域进行增强,锐化需要获取图片的细节,细节是由原图减去下采样再上采样生成的模糊图片得到的,此时得到的细节图片的Mask区域需要再进一步增强,增强的原理是把细节图片也分成32*32个Patch再利用上面得到的注意力矩阵,加权求和Mask外的细节特征到Mask内,对增强的Mask内细节区域的图片再加到修复后图像对应的Mask内的区域,使得修复后的图像更加清晰自然。
基于GAN的对抗性训练方式,我们列出生成器和判别器的损失函数。如下是判别器损失函数,就是要让生成的图片分布的期望尽可能小,真实图片分布的期望尽可能大。
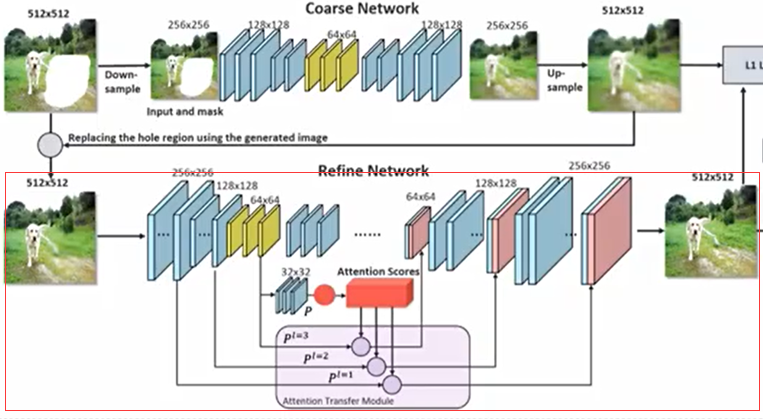
第二阶自编码器是一个精细的自编码器,会对上阶生成的修复的Mask内的图像进行精细加工,使得该区域图像变得清晰。该阶自编码器的原理是将图像切成指定数量的Patch,比如对大小为512*512的原始图像切成32*32个相同大小的Patch,那么每个Patch大小是16*16。在该阶的编码器高层将特征图也切成32*32个Patch,比如在高层的特征图大小是96*96,Channel数为256,此时在高层用3*3的卷积核对每个Patch内进行特征提取,这样每个Patch会生成一个256维的向量,这256维的向量记录了原图对应Patch的特征。当两个Patch的特征相似时它们对应的256维向量的余弦相似度就会较大,用这个原理可以生成Patch之间的相关性,这个两两之间的相关性可以用注意力矩阵来表示,反应了图片内所有Patch之间的相似程度,相似度越大注意力分数越高。
修复Mask内的图像就是要利用相似度从Mask外找到与Mask内待修复Patch相似性高的Patch,在编码器的低层将Mask外的Patch与以对应的注意力分数作为权值相乘后再相加得到待修补Patch内的特征值。
对于生成器,希望它尽可能生成真实清晰的图像,而判别器则希望尽可能的区分真实样本与生成样本,以促使生成器尽可能生成更真实清晰的图像。
注意,生成器除了生成了一张512x512的修复后他图像,还输出了一个注意力矩阵(1024 x 1024),CRA矩阵就是利用该注意力矩阵实现了进一步的精修。
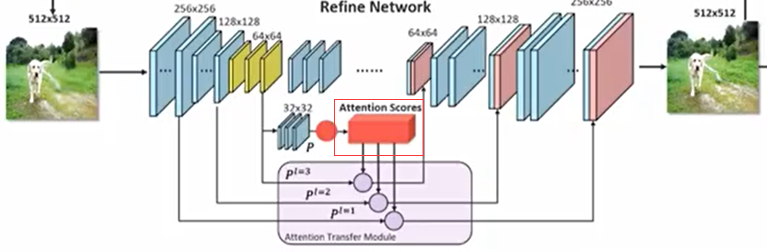
接下来看CRA如何利用注意力矩阵进一步精修图像。
CRA机制精修图像:
1、锐化处理需要获取图片的细节,由原图和修复后的图片缩放到同样大小后相减得到细节图片;
2、得到细节图后需要利用mask区域外的上下文信息再进一步生成细节图片的mask内区域图片,具体为:把细节图片分成32 X 32个patch,再利用上面得到的注意力矩阵,加权求和mask外的细节特征得到mask内的细节,修复后的mask内细节区域的图片再加到修复后图像对应的mask内的区域,得到清晰的修复区域的图片,最后再将经过以上处理修复后的图片的mask内区域与原图mask外的区域合并组成一张完整的清晰自然的图像。
关联矩阵生成高清细节图具体实现方法:
针对每个需要修复的像素,都要取1024个patch中的对应像素值与1024个概率值乘加得到,计算量是非常大的;我们可以估算一下,如果是图像尺寸是(3072,3072,3);
那么计算量:1024 * 3072 * 3072 * 3 = 28991029248 = 0.28T
就算是只计算mask内的必要元素,但却需要多次判断该像素是否在mask内;所以在CPU上计算将非常慢;大家可以试一下。
这里我们却可以将这个计算转换为矩阵乘,针对每一个像素都去计算,不用去考虑是否在mask内,利用Ascend310的强大的矩阵乘能力去计算。
将关联矩阵作为左矩阵(1024 x 1024),将32 * 32个patch中的第一个像素取出来作为一列,因为每个patch是96行96列(3072 / 32=96)3通道,所以总共是96 * 96 * 3=27648列,所以最终是27648列的一个矩阵作为右矩阵(1024 x 27648)。
右矩阵如何从3072 x 3072 x 3的矩阵变换成1024 x 27648的过程,可以用reshape + transpose就可以了。
2、MaskRCNN实例分割模型
本应用中MaskRCNN主要做的是将原图做实例分割,从而自动生成mask图像以提供给GAN网络进行模型推理。由于使用的是COCO数据集,所以支持80类物体的检测。
MaskRCNN是一种概念简单、灵活、通用的目标实例分割框架,在检测出图像中目标的同时,还为每一个实例生成高质量掩码。这种称为Mask R-CNN的方法,通过添加与现有边框识别分支平行的预测目标掩码分支,达到扩展Faster R-CNN的目的。Mask R-CNN训练简单,运行速度达5fps,与Faster R-CNN相比,开销只有小幅上涨。此外,Mask R-CNN易于推广到其他任务。例如,允许在同一框架中预测人体姿势。 Mask R-CNN在COCO挑战赛的三个关键难点上都表现不俗,包括实例分割、边框目标检测和人物关键点检测。Mask R-CNN没有什么华而不实的附加功能,各任务的表现都优于现存所有单模型,包括COCO 2016挑战赛的胜出模型。
MaskRCNN是一个两级目标检测网络,作为FasterRCNN的扩展模型,在现有的边框识别分支的基础上增加了一个预测目标掩码的分支。该网络采用区域候选网络(RPN),可与检测网络共享整个图像的卷积特征,无需任何代价就可轻松计算候选区域。整个网络通过共享卷积特征,将RPN和掩码分支合并为一个网络。
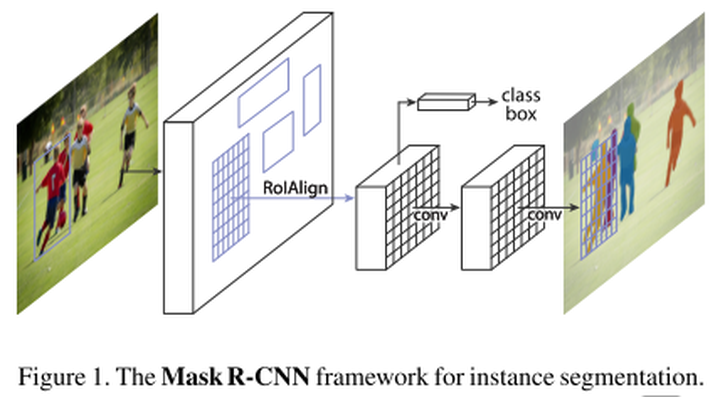
整个的网络结构包含两部分,一部分是backbone用来提取特征,另一部分是head用来对每一个ROI进行分类、框回归和mask预测。
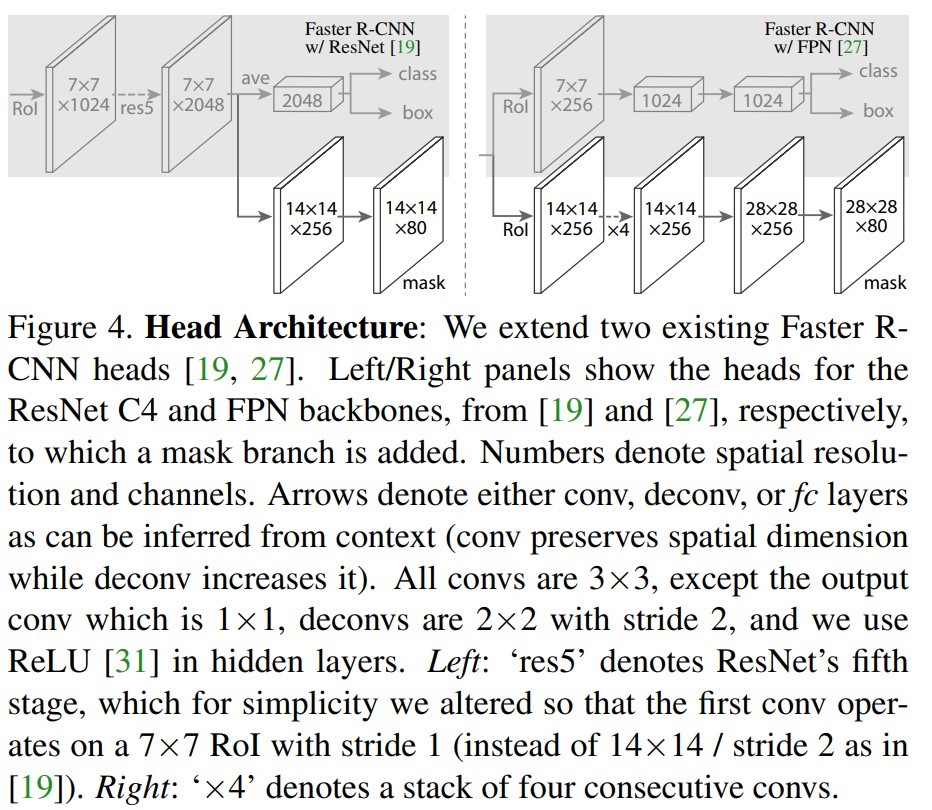
为了产生对应的Mask,文中提出了两种架构,即左边的Faster R-CNN/ResNet和右边的Faster R-CNN/FPN,如下图所示。我们这里采用的是右边的架构。
对于左边的架构,我们的backbone使用的是预训练好的ResNet,使用ResNet倒数第4层的网络。输入的ROI首先获得7x7x1024的ROI feature,然后将其升维到2048个通道(这里修改了原始的ResNet网络架构),然后有两个分支,上面的分支负责分类和回归,下面的分支负责生成对应的mask。由于前面进行了多次卷积和池化,减小了对应的分辨率,mask分支开始利用反卷积进行分辨率的提升,同时减少通道的个数,变为14x14x256,最后输出了14x14x80的mask模板。
而右边使用到的backbone是FPN网络,这是一个新的网络,通过输入单一尺度的图片,最后可以对应的特征金字塔,如果想要了解它的细节,请参考该链接。得到证实的是,该网络可以在一定程度上面提高检测的精度,当前很多的方法都用到了它。由于FPN网络已经包含了res5,可以更加高效的使用特征,因此这里使用了较少的filters。该架构也分为两个分支,作用于前者相同,但是分类分支和mask分支和前者相比有很大的区别。可能是因为FPN网络可以在不同尺度的特征上面获得许多有用信息,因此分类时使用了更少的滤波器。而mask分支中进行了多次卷积操作,首先将ROI变化为14x14x256的feature,然后进行了5次相同的操作(不清楚这里的原理,期待着你的解释),然后进行反卷积操作,最后输出28x28x80的mask。即输出了更大的mask,与前者相比可以获得更细致的mask。
图片摘自论文:https://arxiv.org/pdf/1703.06870.pdf
三、应用开发
本应用采用了下图所示的模块化设计,通过各模块之间的协调配合完成一张图片的推理输出。
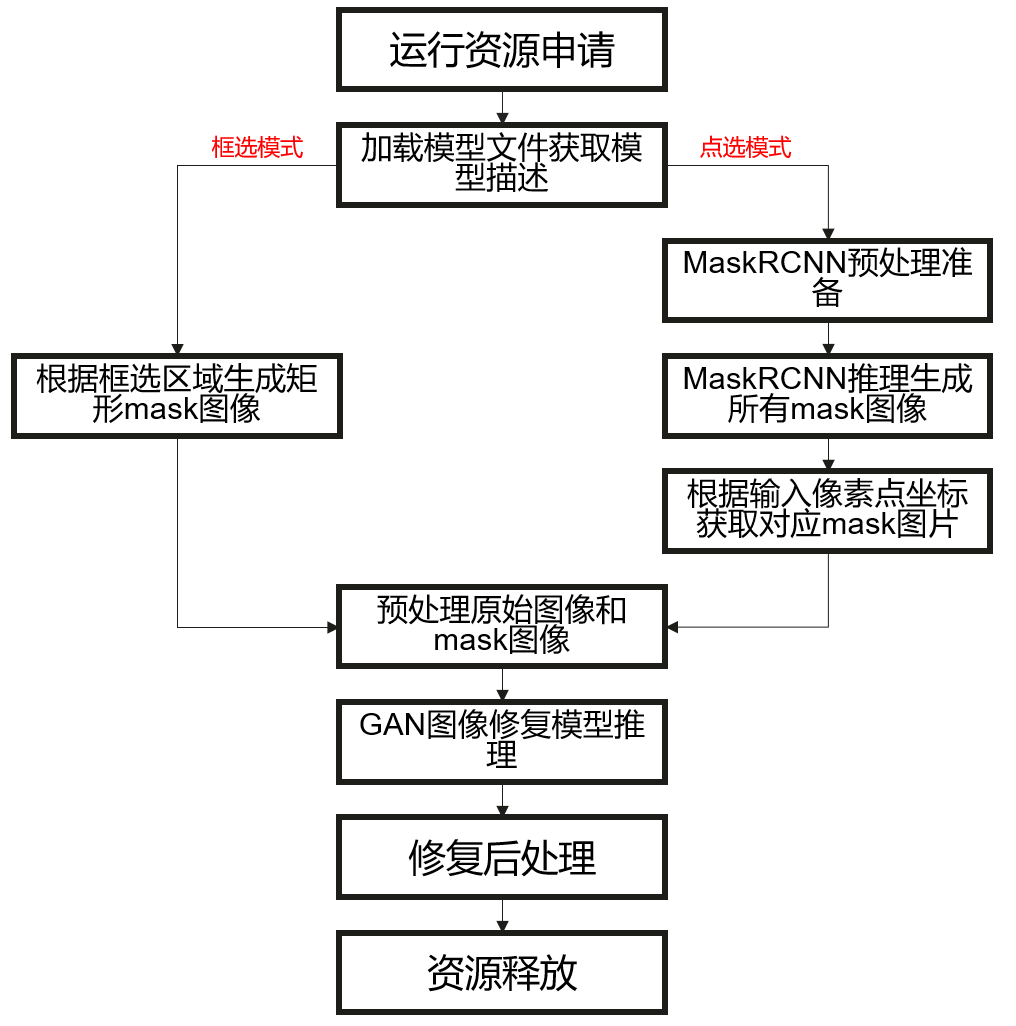
其中各个模块的主要功能点如下所示:
1.运行管理资源申请;
2.加载模型文件,构建模型输出内存;
3.框选模式数据获取,获取要进行推理的原始图像和Mask图像;
4.点选模式MaskRCNN图像预处理,主要是进行resize;
5.点选模式MaskRCNN推理,生成目标mask;
6.点选模式数据获取,根据输出像素点坐标将对应区域的mask获取出来;
7.GAN图像修复数据预处理,模型的输入图像进行预处理;
8.GAN图像修复模型推理,将数据输入到模型进行推理;
9.解析模型推理结果,得到修复后的图像和注意力矩阵进行后处理,利用注意力矩阵对图像的细节的Mask内区域进行增强,将增强的细节叠加到修复的图像的Mask内区域即对修复的区域进行锐化,再把锐化Mask内区域的图像与原图Mask外区域合并得到修复后的高清图像。
AI图像修复预处理部分首先使用OpenCV读取原图和Mask图,将原图和Mask图进行大小缩放,缩放至3072*3072大小,之后再将原图像和Mask图像缩小到512*512用于送入模型进行推理,之所以将图片缩小后送入模型推理是为了节省算力和内存空间,加速推理时间;将读取到的图像数据拷贝至设备侧申请的内存空间中,为接下来构建模型输入数据做好准备。最后分别得到3072*3072和512*512的原图和Mask图。
而后处理是整个应用中最复杂的部分,主要是对模型生成器修复的图像对修复区域进行增强,增强方式是采用了图像锐化的原理,将修复图像的修复区域与原图细节抽取的图片对应的区域相加,另外本应用中利用注意力矩阵对原图细节图片也做了进一步加工,使得细节图片包含更丰富的信息,以此得到锐化后的修复区域图像更清晰。
相关链接:
GAN图像修复模型论文参考链接如下:
Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
GAN图像修复原始模型部署链接如下:
Image Inpainting Project based on CVPR 2020 Oral Paper on HiFill
MaskRCNN实例分割相关参考链接如下:
https://arxiv.org/pdf/1703.06870.pdf
https://blog.csdn.net/wangdongwei0/article/details/83110305/
https://blog.csdn.net/qq_37392244/article/details/88844681
相关源码可以在Ascend开源仓库中获取:
https://gitee.com/ascend/samples/tree/master/python/level2_simple_inference/6_other/imageinpainting_hifill
优点:
AI图像修复存在很多优点,以下简单介绍:
1. 图片处理速度快
基于昇腾专门针对AI的NPU进行推理,图像的修复速度可以达到毫秒级。快速修复,无需等待。
2. 缩减工作量
而对于动辄几千帧图像的视频,如果单纯使用人工修补,耗费的人力是不可想象的,而AI图像修复可以大大缩减工作量,让大量的修复工作变得简单。
3. 可不断优化,质量高
AI图像修复是基于GAN网络训练的模型,针对于不同场景,可以采集不同的数据集,进行加强训练。在数据集的扩充下,模型的精准度及处理效果越来越强,甚至可以超出人工修补的质量。
四、效果展示


