




网络概述
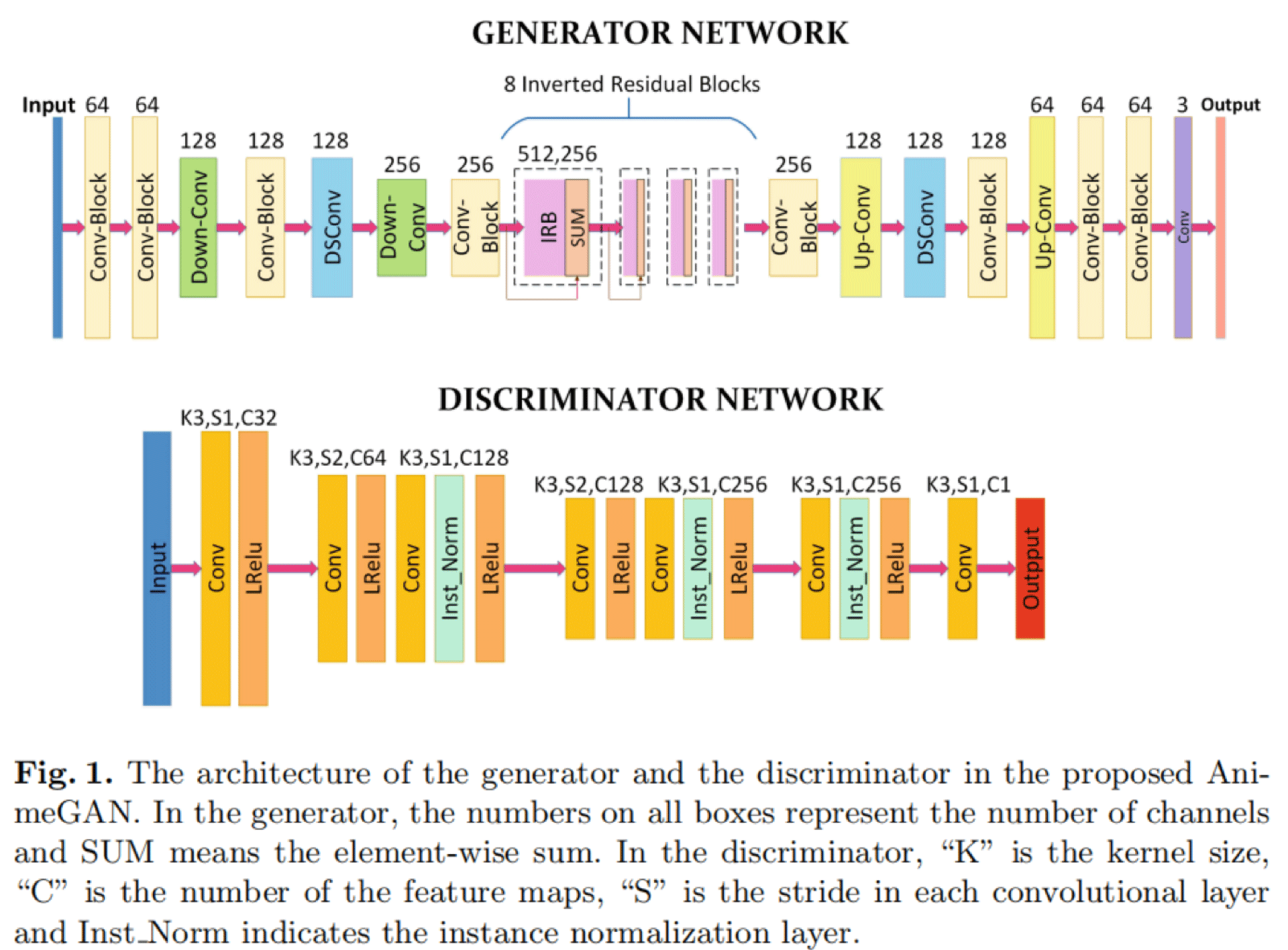
AnimeGAN生成网络结构如下,以Generative Adversarial Networks(GAN)为基础,其架构包括一个生成器(Generator)用于将现实世界场景的照片转换为动漫图像,和一个判别器(Discriminator)区分图像是来自真实目标域还是来自生成器产生的输出,通过迭代训练两个网络(即生成器和判别器),由判别器提供的对抗性损失可以生成卡通化的结果。同时将生成器替换为自编码结构,使得生成器具有更强的生成能力。对于生成器,它希望生成样本尽可能符合真实样本的分布,而判别器则希望尽可能的区分真实样本与生成样本。具体来说,判别器将真实样本判断为正确,记为1;而将生成结果判断为错误,记为0。
参考实现: https://github.com/TachibanaYoshino/AnimeGAN
参考论文: https://link.springer.com/chapter/10.1007/978-981-15-5577-0_18
AnimeGAN 的生成器可以被认为是一个对称的编码器-解码器网络。主要由标准卷积、深度可分离卷积、反向残差块(IRB),上采样和下采样模块组成。 在生成器中,最后一个具有 1×1 卷积核的卷积层不使用归一化层,后面是 tanh 非线性激活函数。Conv-Block 由具有 3×3 卷积核的标准卷积、实例归一化层和 LRelu 激活函数组成。 DSConv 由具有 3 × 3 卷积核的深度可分离卷积、实例归一化层和 LRelu 激活函数组成。反转的残差块包含 Conv-Block、深度卷积、点卷积和实例归一化层。
为了避免最大池化导致的特征信息丢失,使用Down-Conv作为下采样模块来降低特征图的分辨率。它包含步长为 2 的 DSConv 模块和步长为 1 的 DSConv 模块。在 Down-Conv 中,特征图的大小被调整为输入特征图大小的一半。 Down-Conv 模块的输出是步长为 2 的 DSConv 模块和步长为 1 的 DSConv 模块的输出之和。使用Up-Conv 用作上采样模块以提高特征图的分辨率。
为了有效减少生成器的参数数量,网络中间使用了 8 个连续且相同的 IRB。与标准残差块 相比,IRB 可以显着减少网络的参数数量和计算工作量。生成器中使用的 IRB 包括具有 512 个内核的逐点卷积、具有 512 个内核的深度卷积和具有 256 个内核的逐点卷积。值得注意的是,最后一个卷积层没有使用激活函数。
为了辅助生成器生成更好的结果,判别器需要判断输出图像是否是真实的卡通图片。因为判断是否真实依赖于图片本身特征,不需要抽取最高层的图片特征信息,所以可以设计成较为浅层的框架。首先对输入进行卷积核为3 x 3的卷积,然后紧接两个步长为2的卷积块来降低分辨率,并且提取重要的特征信息。最后使用一个3 × 3的卷积层得到最终提取的特征,再与真实标签进行损失计算。如果输入为256 × 256,则输出为64 × 64的PatchGAN形式。这里将Leaky ReLU的参数设置为0.2。
模型转换
获取到原始模型后,需要使用昇腾CANN所提供的ATC模型转换工具,将第三方框架的模型转换为昇腾推理芯片所支持的om模型。模型转换步骤可参考昇腾文档中开发者文档->应用开发->将已有模型通过ATC工具转换(命令行)的指导进行转换。该样例通过不同分辨率的模型支持三种不同的输入图片,直接影响到生成图片的质量。以下为模型转换过程。

样例介绍
本样例使用了3个AnimeGAN模型,支持256*256/512*512/1024*1024三种不同模型输入分辨率。分辨率越高,模型推理时间越长,图片质量越好。
受限于网络传输速度,该爆点应用使用的是256*256的模型,如果要获得更好的效果,请移步 gitee样例 。
本样例采用了下图所示的模块化设计,通过各模块之间的协调配合完成一张图片的推理输出。

其中各个模块的主要功能点如下所示:
1.运行管理资源申请:用于初始化系统内部资源,固定的调用流程。
2.加载模型文件并构建输出内存:从文件加载离线模型AnimeGAN.om数据,需要由用户自行管理模型运行的内存,根据内存中加载的模型获取模型的基本信息包含模型输入、输出数据的数据buffer大小;由模型的基本信息构建模型输出内存,为接下来的模型推理做好准备。
3.数据预处理:对读入的图像数据进行预处理,然后构建模型的输入数据。
4.模型推理:根据构建好的模型输入数据进行模型推理。
5.解析推理结果:根据模型输出,解析模型的推理结果。使用OpenCV将转换后的卡通画数据转化为JPEG。
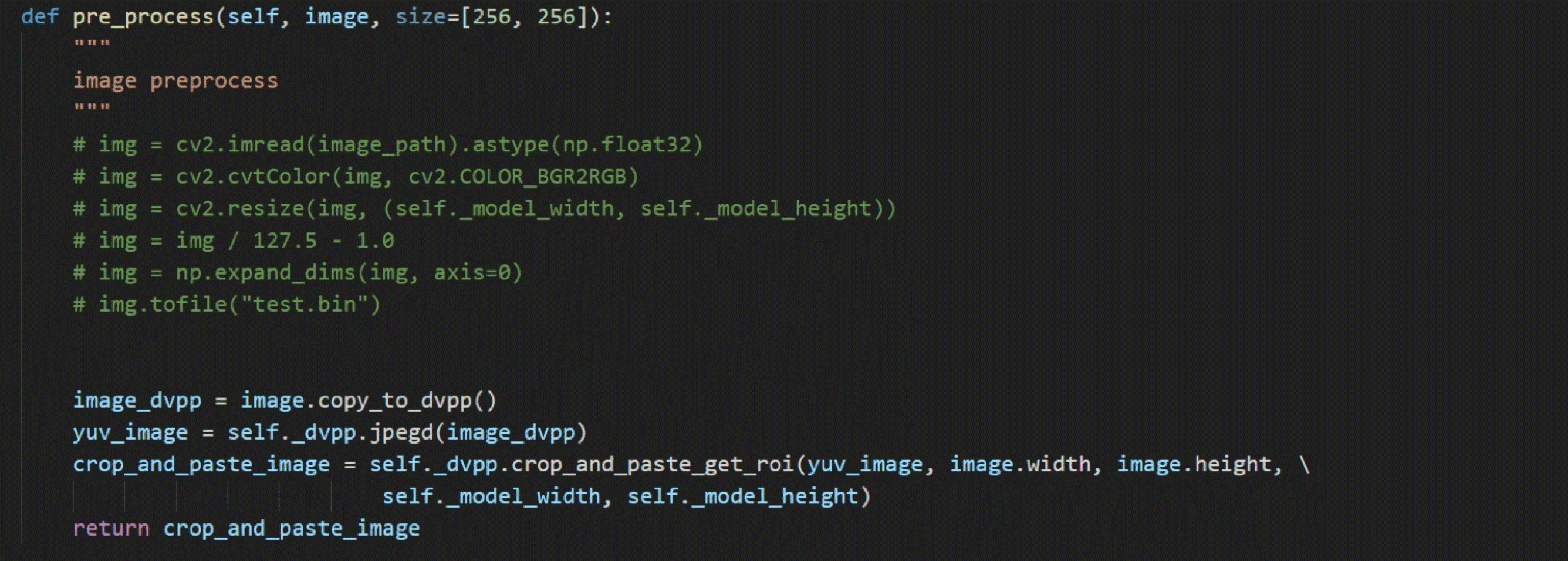
图像预处理
使用DVPP对读入图片进行解码,并缩放至256 × 256分辨率,以符合网络输入大小;在模型转换时,使用AIPP功能,将unit8的数据转换为fp16格式,将0~255的数值归一化到-1~1,将BGR的图片格式转换为RGB格式。
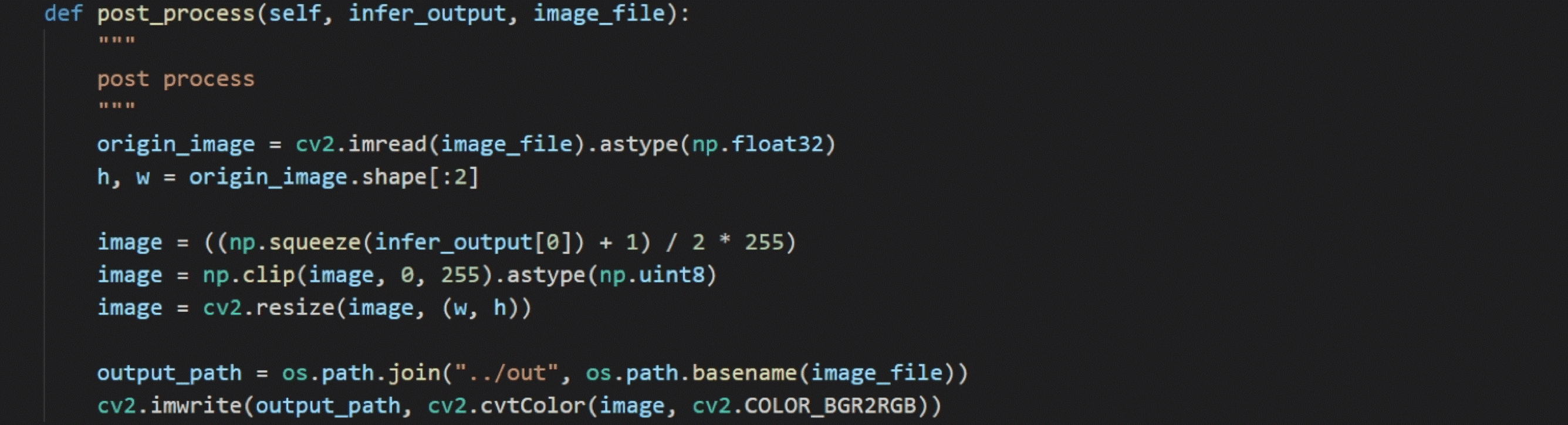
模型推理结果后处理
后处理模块主要是对模型的推理结果进行格式变换,然后将变换结果反馈给用户。主要过程是先将-1~1的值映射回0~255,然后将256 × 256的转换结果缩放回原始图像的尺寸大小。最后进行色域转换将RGB格式的输出转换为BGR格式。
效果展示
| 模型规格 | 原始图片 | 推理结果 |
|---|---|---|
| 256*256 |  |  |
| 512*512 |  |  |
| 1024*1024 |  |  |