约束条件
- 需要保证K8s集群中各节点时间一致,避免程序误判。
- 对于Resilience-Controller正在重新调度任务的过程中,对该任务新出现的故障不再进行处理。
- 在集群资源有限的场景中,当多个任务同时故障触发重调度可能会出现由于资源不足而pending的情况。
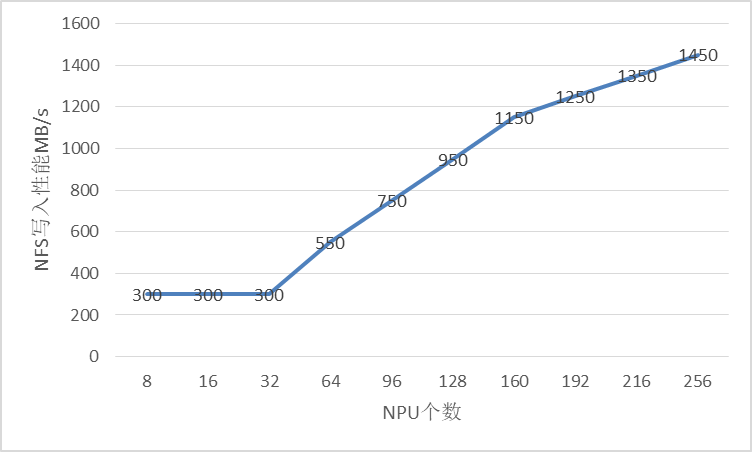
- NFS需要用户根据使用情况进行目录隔离,NFS的随机读写性能必须能够在15分钟内保存完整的ckpt文件,建议用户使用专业的存储服务器,具体性能要求给出如下参考。
配置依赖
- 本特性不适用于虚拟化实例场景。
- 本特性依赖集群调度组件中Resilience-Controller、Volcano、HCCL-Controller、NodeD和Ascend Device Plugin五个组件。如使用断点续训特性中的临终遗言功能,还需要使用mindx_elastic二进制文件。
- 该特性目前只支持服务器间数据并行和混合并行的分布式vcjob类型的训练任务。
- 需要在vcjob类型任务的yaml中增加故障重调度的开关“fault-scheduling”(当前仅支持grace模式)、“elastic-scheduling”以及任务所需的最少节点个数“minReplicas”,其值参考:。任务配置
- “临终遗言”需要在vcjob类型任务的yaml中配置停止优雅时间:“terminationGracePeriodSeconds”,具体请参见:表2。
- 需要在vcjob类型任务的yaml中将字段"maxRetry"的值设置为0。
- 节点故障规则:当NodeD最近一次上报心跳之后一段时间内未再次上报心跳(大于两次心跳上报间隔的阈值)时,Resilience-Controller和Volcano就会认为NodeD所在节点故障,从而触发故障重调度。当后续NodeD两次心跳上报间隔小于等于阈值时,则认为NodeD所在节点恢复正常。
计算公式:两次心跳上报间隔的阈值 = 心跳发送间隔配置 x 3,其中3表示Resilience-Controller和Volcano会重试3次。

- 断点续训特性的临终遗言功能中使用了SigTerm和SigInt的信号量。
- 断点续训特性的临终遗言功能不支持对保存的checkpoint文件加解密。
父主题: 最小业务系统使用示例