通过流水图优化算子
展示如何通过msProf工具的流水图特性,分析算子的瓶颈点,并实现vector算子的性能优化。
操作步骤
- 参考msprof op simulator节点,将算子仿真性能数据采集得到的visualize_data.bin文件导入MindStudio Insight,具体导入操作请参考《MindStudio Insight 用户指南》的“导入性能数据”章节。
- 查看算子指令热点图。
可以发现MTE2流水在VADD计算时,没有执行搬运指令,且MTE2流水为该算子的性能瓶颈,需提高MTE2的搬运效率以实现算子性能优化。
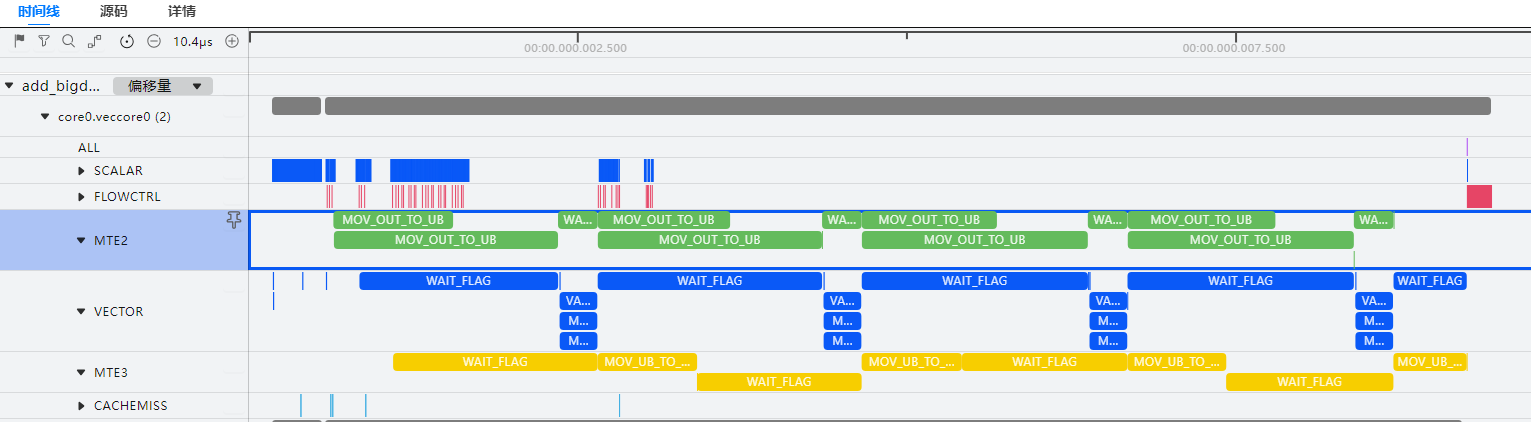
- 对于MTE2搬运效率的提升有多种方式,此处以开启AscendC算子的double buffer机制为例。
- 重新执行步骤1,查看优化后的性能流水图。
在VADD指令计算时,MTE2上的搬运指令也同步执行,实现了更高效的数据搬运。

父主题: 典型案例