迁移操作
迁移步骤
- 通过以下任一方式启动脚本迁移。
- 单击工具栏中
 图标。
图标。 - 在菜单栏选择。
- 右键单击工程目录中的文件夹,选择“X2MindSpore”。
- 单击工具栏中
- 参数配置。
X2MindSpore启动后界面如图1所示,用户自行根据实际情况配置参数。
图2 X2MindSpore参数配置界面(开启Graph)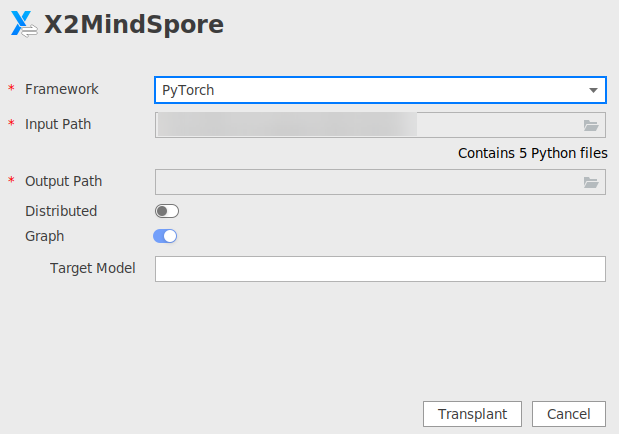
表1 X2MindSpore参数说明 参数
参数说明
Framework
要进行迁移的原始脚本的框架,必选。
取值如下。
- PyTorch(默认)
- TensorFlow 1
- TensorFlow 2
Input Path
要进行迁移的原始工程目录。必选。
Output Path
脚本迁移结果文件输出路径。必选。
- 不开启“Distributed”即迁移至单卡脚本场景下,输出目录名为xxx_x2ms。
- 开启“Distributed”即迁移至多卡脚本场景下,输出目录名为xxx_x2ms_multi。
xxx为原始脚本所在文件夹名称。
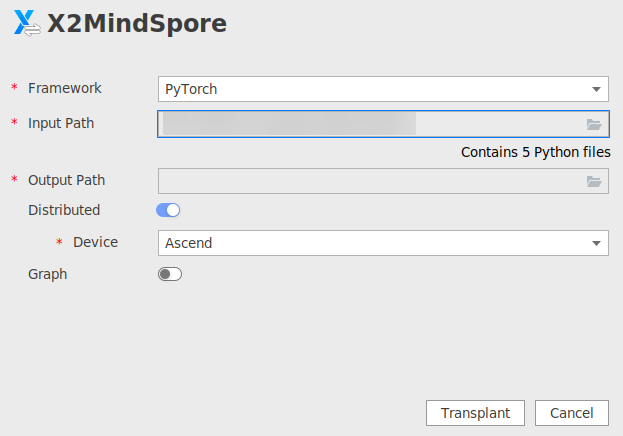
Distributed
将GPU单卡脚本迁移为多卡脚本,仅支持“PyTorch”和“TensorFlow 2”框架。可选。默认关闭。
开启此参数后,需配置“Device”参数,将GPU单卡脚本迁移为指定设备的多卡脚本,取值如下:
- Ascend(默认)
- GPU
Graph
迁移后的脚本支持在MindSpore 1.8-1.10版本的Graph模式下运行。可选。默认关闭(即默认迁移至PyNative模式)。
目前该参数仅支持模型列表中ResNet、BiT系列和UNet的模型迁移至Graph模式,且不能与“Distributed”同时使用。
开启此参数后,可配置“Target Model”参数,即目标模型变量名,默认为“model”。
- 单击“Transplant”,执行迁移任务。
完成后,Output Path输出目录下查看结果文件。
├── xxx_x2ms/xxx_x2ms_multi // 脚本迁移结果输出目录 │ ├── 迁移后的脚本文件 // 与迁移前的脚本文件目录结构一致。 │ ├── x2ms_adapter // 适配层文件。 │ ├── unsupported_api.csv // 不支持API列表文件。 │ ├── custom_supported_api.csv // 工具自定义适配API列表文件(目前仅支持PyTorch框架的训练脚本)。 │ ├── supported_api.csv // 支持API列表文件。 │ ├── deleted_api.csv // 删除API列表文件。 │ ├── x2mindspore.log // 迁移日志,日志文件限制大小为1M,若超过限制将分多个文件进行存储,最多不会超过10个。 │ ├── run_distributed_ascend.sh // 启用Distributed参数,且Device指定Ascend设备时,会生成该多卡启动shell脚本。 │ ├── rank_table_2pcs.json // 启用Distributed参数,且Device指定Ascend设备时,会生成该2卡环境组网信息样例文件。 │ ├── rank_table_8pcs.json // 启用Distributed参数,且Device指定Ascend设备时,会生成该8卡环境组网信息样例文件。
- 在执行迁移后的模型文件前,请先将输出的工程路径加入环境变量PYTHONPATH中,示例如下。
export PYTHONPATH=${HOME}/output/xxx_x2ms:$PYTHONPATH
后续操作
- 如果启用了Distributed参数,迁移后需要根据Device指定的设备完成运行多卡脚本的特定操作。
- Device指定Ascend设备。
- 参见配置分布式环境变量配置生成的多卡环境的组网信息json文件。
- 将run_distributed_ascend.sh文件中的“please input your shell script here”语句替换为模型原训练脚本执行命令。
#!/bin/bash echo "==============================================================================================================" echo "Please run the script as: " echo "bash run_distributed_ascend.sh RANK_TABLE_FILE RANK_SIZE RANK_START DEVICE_START" echo "For example: bash run_distributed_ascend.sh /path/rank_table.json 8 0 0" echo "It is better to use the absolute path." echo "==============================================================================================================" execute_path=$(pwd) echo "${execute_path}" export RANK_TABLE_FILE=$1 export RANK_SIZE=$2 RANK_START=$3 DEVICE_START=$4 for((i=0;i<RANK_SIZE;i++)); do export RANK_ID=$((i+RANK_START)) export DEVICE_ID=$((i+DEVICE_START)) rm -rf "${execute_path}"/device_$RANK_ID mkdir "${execute_path}"/device_$RANK_ID cd "${execute_path}"/device_$RANK_ID || exit "please input your shell script here" > train$RANK_ID.log 2>&1 & done
该脚本会在工程路径下创建device_{RANK_ID}目录,在该目录内去执行网络脚本,所以替换训练Python脚本执行命令时要注意训练Python脚本相对路径的变化。
- 执行run_distributed_ascend.sh脚本以启动用户原工程。以8卡环境为例,命令如下。
bash run_distributed_ascend.sh RANK_TABLE_FILE RANK_SIZE RANK_START DEVICE_START
- RANK_TABLE_FILE:多卡环境的组网信息json文件。
- RANK_SIZE:指定调用卡的数量。
- RANK_START:指定调用卡的逻辑起始ID,当前仅支持单机多卡,填0即可。
- DEVICE_START:指定调用卡的物理起始ID。
- Device指定Ascend设备。
- 如果启用了Graph参数,需要把训练脚本中WithLossCell类的construct函数修改为只包括模型的前向计算和loss计算,具体修改请参见迁移后脚本中的Transplant advice。
- 由于转换后的脚本与原始脚本框架不一致,迁移后的脚本在调试运行过程中可能会由于MindSpore框架的某些限制而抛出异常,导致进程终止,该类异常需要用户根据异常信息进一步调试解决。
- 分析迁移后可以参考模型训练进行训练。
父主题: X2MindSpore