SplitFuse性能调优
概述
MindIE支持SplitFuse特性,当MindIE在默认情况下使用PD竞争策略,Prefill和Decode阶段请求不会同时被组合成一个batch。打开SplitFuse特性后,MindIE会在优先处理Decode请求的基础上,且batch小于maxBatchSize的情况下在同一批次中加入Prefill请求。
当该次处理的feedforward大于splitchunk tokens时,SplitFuse会对其进行切分,解释如下所示:
- 每一推理轮次中:
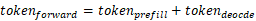 ,其中:
,其中: 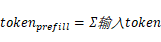
- Prefill阶段的tokens为输入token数量,Decode阶段每个请求的为1token:
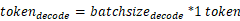
该特性可以通过{MindIE安装目录}/latest/mindie-service/conf/config.json配置文件中通过以下参数打开。
- plugin_params:需配置为"{\"plugin_type\":\"splitfuse\"}";
- templateType:需配置为"Mix";
- enableSplit:需配置为"true"。
优势
- 高响应性:由于Prefill阶段和Decode阶段的请求可以同时进行批处理,减少了空泡。
- 高效率:该特性优先处理Decode请求,提供了更大的系统吞吐和更好的Decode时延。
- 低的波动和高一致性:由于feedforward(前向传播)的大小一致,因此相比PD混部,可以提供更稳定的生成频率。
约束
- 仅
Atlas A2 推理系列产品 支持SplitFuse性能调优。 - 支持对接SplitFuse性能调优的模型为llama3.1-70b。
配置说明
|
配置项 |
取值类型 |
说明 |
|---|---|---|
|
ModelDeployConfig |
||
|
plugin_params |
std::string |
必选;
|
|
ScheduleConfig |
||
|
templateType |
std::string |
必选;
|
|
policyType |
Enum |
可选;
|
|
enableSplit |
bool |
必选;
|
|
splitType |
bool |
可选;
建议值:false;默认值:false |
|
splitStartType |
bool |
可选;
建议值:false;默认值:false |
|
splitChunkTokens |
uint32_t |
可选; 当前参与组batch的总token个数。 取值范围:[1,8192];建议值:16的整数倍;默认值:512 |
|
splitStartBatchSize |
uint32_t |
可选; 当batch数达到该值时开启切分。 取值范围:[0,maxBatchSize];建议值:16;默认值:16 |
原理
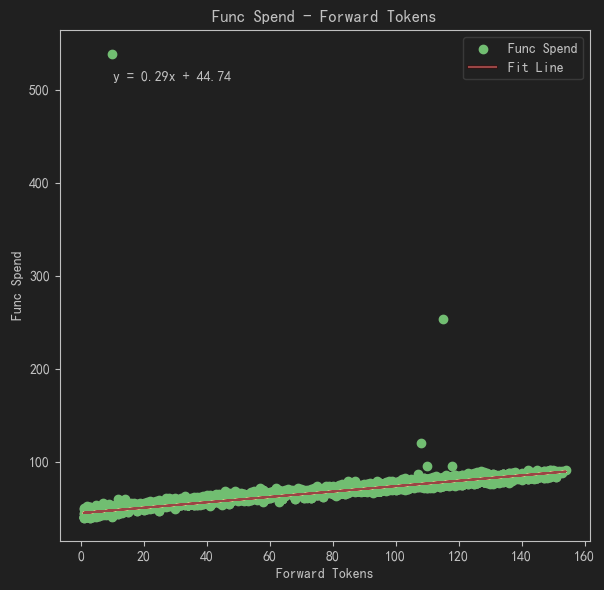
大模型推理过程中,推理性能主要受访存速度限制,在此种条件下可见模型推理耗时主要与Forward Tokens的数量呈线性关系,如图1所示。因此,打开SplitFuse时,当需要增量推理时延满足特定控制服务级别目标(SLO),如90%轮次的增量推理时延(SLO_P90 decode时延)小于50ms时,可以通过控制SplitFuse特性的ChunkSize进行控制。需要说明的是减少ChunkSize在约束SLO指标的同时,可能会增加推理轮次,从而产生额外的开销导致总体吞吐的下降。
操作步骤
- 访问MindIE Service配置文件config.json,路径如下所示。
{MindIE安装目录}/latest/mindie-service/conf/config.json - 请参见表1中“plugin_params”、“templateType”和“enableSplit”参数开启Splitfuse特性。对于性能调优,需要编辑config.json配置文件中的ScheduleConfig部分,建议将“maxBatchSize”与“splitChunkTokens”参数配置为相同大小,并通过调整这两个参数的值来控制SLO的Decode时延指标。请参见以下配置样例,SplitFuse的相关配置已加粗显示,参数具体解释请参见表1。
"ModelDeployConfig": { "maxSeqLen" : 65536, "maxInputTokenLen" : 65536, "truncation" : false, "ModelConfig" : [ { "modelInstanceType": "Standard", "modelName" : "LLaMA3-70B", "modelWeightPath" : "/home/models/LLaMA3-70B/", "worldSize" : 8, "cpuMemSize" : 5, "npuMemSize" : -1, "backendType": "atb", "plugin_params": "{\"plugin_type\":\"splitfuse\"}" } ] }, "ScheduleConfig": { "templateType": "Mix", "templateName" : "Standard_LLM", "cacheBlockSize" : 128, "maxPrefillBatchSize" : 40, "maxPrefillTokens" : 65536, "prefillTimeMsPerReq" : 600, "prefillPolicyType" : 0, "decodeTimeMsPerReq" : 50, "decodePolicyType" : 0, "policyType": 0, "maxBatchSize" : 256, "maxIterTimes" : 512, "maxPreemptCount" : 0, "supportSelectBatch" : false, "maxQueueDelayMicroseconds" : 5000, "enableSplit": true, "splitType": false, "splitStartType": false, "splitChunkTokens": 256, "splitStartBatchSize": 16 } - 本样例以MindIE Benchmark方式展示调优方式。config.json配置完成后,执行如下MindIE Benchmark启动命令。
benchmark \ --DatasetPath "/{数据集路径}/GSM8K" \ --DatasetType "gsm8k" \ --ModelName LLaMa3-70B \ --ModelPath "/{模型权重路径}/LLaMa3-70B" \ --TestType client \ --Http https://{ipAddress}:{port} \ --ManagementHttp https://{managementIpAddress}:{managementPort} \ --Concurrency 1000 \ --RequestRate 5 \ --TaskKind stream \ --Tokenizer True \ --MaxOutputLen 512 - 根据首Token时延和Decode时延的实际数据调整参数。
- 首Token时延和Decode时延(均值,P90)都满足约束阈值,则加大“RequestRate”的值。
- Decode时延均值位于约束阈值以内,而首Token时延均值大于约束阈值。则“RequestRate”已大于系统吞吐GenerateSpeed,为满足约束需降低“RequestRate”的值。
- 当首Token时延均值和Decode时延均值满足阈值约束,而Decodes时延P90不满足均值时,则考虑降低ChunkSize减小切分,但该操作可能影响吞吐。
- 在输入问题长度不一的场景下,SplitFuse相对于基线SelectBatch场景通常拥有更好的首Token时延。
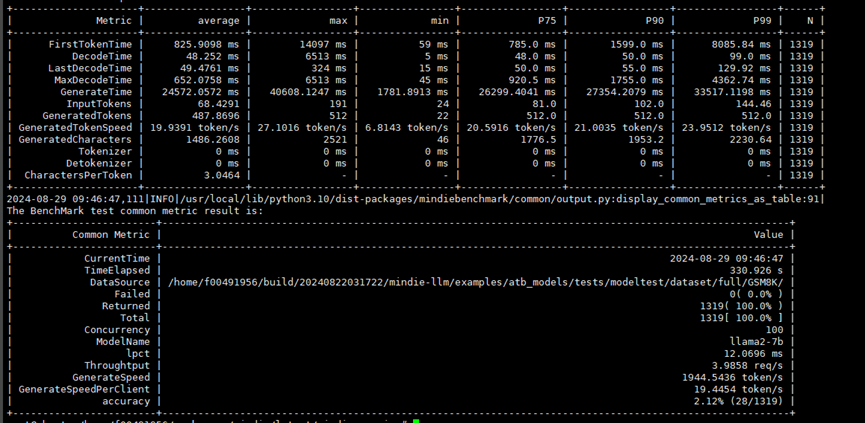
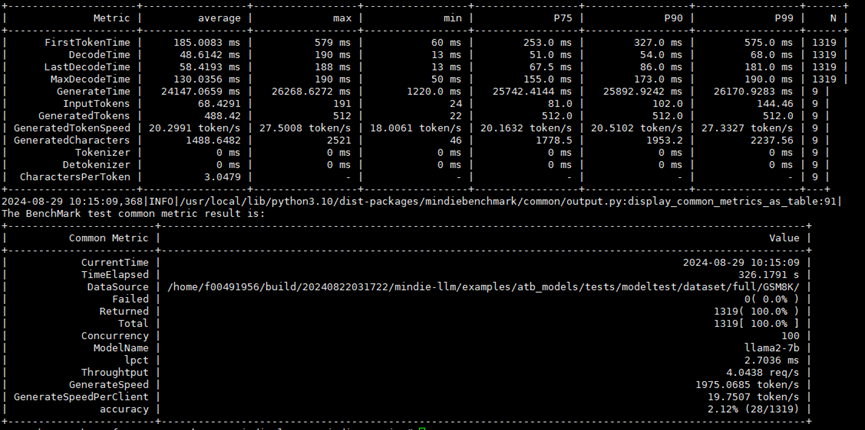
使用MindIE Benchmark对GSM8K数据集进行测试的结果如下:- 打开SplitFuse时:
测试数据集:GSM8K;并发数:100;相对基线吞吐:101.59%;相对基线首Token时延:22.42%;
- 关闭SplitFuse,打开SelectBatch时:
测试集:GSM8K;并发数:100。