集成说明
在进行平台集成操作前,可先参考通过命令行使用断点续训,熟悉下发断点续训任务示例yaml的实现逻辑和参数说明,帮助用户更好地理解接下来的操作。
前提条件
- 仅支持使用集群调度组件的K8s集群,同时需要保证K8s集群中各节点时间一致,避免程序误判。
- 使用前需要检查存储的磁盘空间,确保可以容纳checkpoint。
- 配置存储方案:用户需确保环境中有配置相应的存储方案,比如使用NFS(Network File System),可参考安装NFS进行操作。
NFS需要用户根据使用情况进行目录隔离,NFS的随机读写性能必须能够在15分钟内保存完整的ckpt文件,建议用户使用专业的存储服务器,NFS具体性能要求给出如下参考。
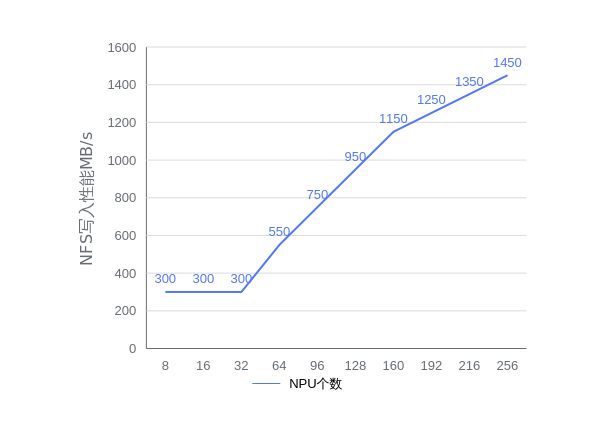
- 安装所需组件:使用断点续训特性需要提前安装如下组件;若没有安装,请参考安装部署章节进行操作。
- Volcano:包括开源Volcano和集群调度组件提供的Volcano;开源Volcano需要集成Ascend-volcano-plugin插件。
- Ascend Operator
- Ascend Device Plugin
- Ascend Docker Runtime
- NodeD
- ClusterD
- (可选)Elastic Agent:若需使用优雅容错或者重调度功能需安装此组件, 部署在训练镜像中。
- 适配整卡调度:请参考集成后使用章节进行操作,确保当前AI平台已经可以实现下发使用整卡资源类型的训练任务。

支持的故障模式
当前已支持20+软件类故障及90+硬件类故障的检测。支持的故障类型请参见表1,详各类典型故障的示例说明可参考典型故障.xlsx。
ConfigMap说明
- 每个计算节点的Ascend Device Plugin均会创建记录本节点NPU和总线设备信息的ConfigMap文件,该ConfigMap文件名称为mindx-dl-deviceinfo-<nodename>(以下简称device-info-cm),通过该ConfigMap进行故障信息的上报。该ConfigMap文件字段说明,请参见表 DeviceInfoCfg。
- 每个计算节点的NodeD均会创建记录本节点设备信息的ConfigMap文件,该ConfigMap文件名称为mindx-dl-nodeinfo-<nodename>(以下简称node-info-cm),通过该ConfigMap进行节点故障的信息上报。该ConfigMap文件字段说明,请参见mindx-dl-nodeinfo-<nodename>。
- ClusterD会创建记录本集群设备信息的ConfigMap文件,该ConfigMap文件名称为cluster-info-<device/node/switch>-<[0-5]>(以下简称cluster-info-cm),通过该ConfigMap进行集群中节点及芯片故障信息上报。该ConfigMap文件字段说明,请参见集群资源章节。
- 创建每个任务时,需要在yaml中配置ConfigMap文件,该ConfigMap文件名称为reset-config-<job-name>(以下简称reset-info-cm),同时将该ConfigMap挂载到容器的“/user/restore/reset/config”路径下。Ascend Device Plugin会自动将Configmap挂载到本节点的“/user/restore/reset/<job-namespace>.<job-name>”路径下。也可以将节点上/user/restore/reset/<job-namespace>.<job-name>替代Configmap挂载到容器的“/user/restore/reset/config”路径下。该ConfigMap文件字段说明,请参见表 reset-config-<job-name>。
父主题: 集成指导