数据对齐
功能介绍
了解数据对齐之前,需要先了解什么是数据对。
图1 数据对示意图
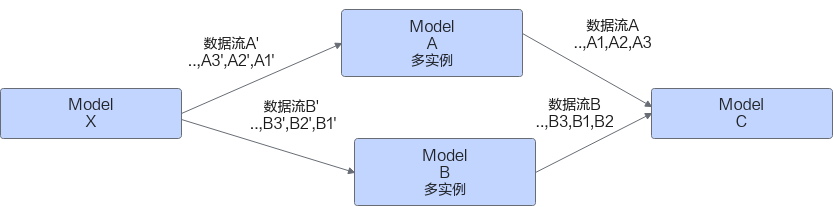
- 定义Model X为数据最早的来源,输出有两个队列,输出的多组数据[A1',B1']、[A2',B2']、[A3',B3'],每组数据是有关联的。
- 定义Model A和Model B为数据处理节点,多实例部署在多张卡上,Model A负责处理数据流A',Model B负责处理数据流B',由于是多实例部署,处理完之后会乱序,无法按照Model X输出的原始顺序输出。
- 定义Model C为数据汇聚节点,从数据流A和数据流B中一组一组的取数据进行处理,必须[A1, B1],[A2, B2],[A3, B3]这样的配对关系才能正常处理。
数据对齐是指udf节点要求输入数据是数据对。
按照示意图的数据流,如果不做数据配对,按照框架默认的接收顺序,Model C收到的数据顺序是[A3, B2],[A2, B1],[A1, B3]。由于数据混乱,无法直接处理的,udf节点收到[A3, B2]之后需要自己先缓存,然后等待收到[A2, B1]后,才可以正常处理[A2, B2]。收到[A1, B3]之后,才能处理[A1, B1]和[A3, B3]。
使用约束
框架数据对齐依赖transId和dataLabel作为判断对齐依据,如果一个数据被复制多份输出,无法保证配对。
使用方法
1 2 | dag = df.FlowGraph([flow_node_out]) dag.set_inputs_align_attrs(align_max_cache_num=256, align_timeout=60 * 1000, dropout_when_not_align=True) # 最大缓存256组数据,超时时间1分钟,超时未对齐则数据丢弃 |
父主题: 专题