FastSoftMaxOperation
功能描述
训练算子,与unpadOperation一起使用,将unpad处理后的Q矩阵和K矩阵相乘的结果做高性能的Softmax处理。
softmax数学公式:
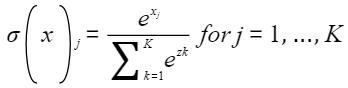
使用场景
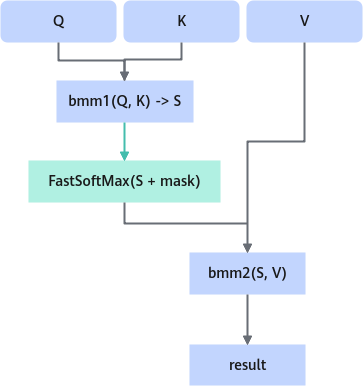
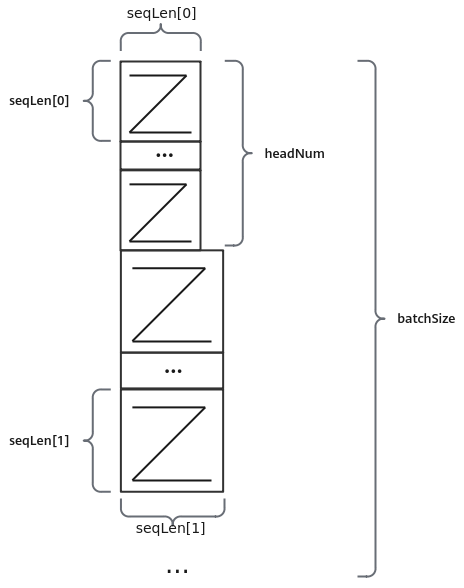
Multi-Head Attention计算过程如图1所示。经过unpad处理后,Q矩阵和K矩阵相乘的结果实际上由batchSize个大小为(seqLen[i], seqLen[i])的矩阵拼接而成(如图2所示),需要对这个结果的末轴做SoftMax操作。采用FastSoftMax算子,接收seqLen和headNum的信息可以对这种排列方式的数据实现SoftMax操作。
定义
struct FastSoftMaxParam {
int32_t headNum = 0;
std::vector<int32_t> qSeqLen;
};
参数列表
|
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
headNum |
int32_t |
0 |
Attention的head数量。 |
|
qSeqLen |
std::vector<int32_t> |
- |
每个batch的实际输入长度。元素个数为batchSize,最大不超过32。 |
输入
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
inTensor |
[nSquareTokens] |
float16 |
ND |
输入tensor, 是batch个(headNum, qSeqLen[i], qSeqLen[i])大小的矩阵按照ND排布拼接成一维的结果。 |
输出
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
outTensor |
[nSquareTokens] |
float16 |
ND |
输出tensor, 数据范围在[0, 1]之间。 |
规格约束
- qSeqLen数组长度不超过32,且要求各元素大于0。
- 当前只支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 。 - 输入tensor(inTensor)、输出tensor(outTensor)的维度大小nSquareTokens与参数中的headNum和qSeqLen有关。须满足
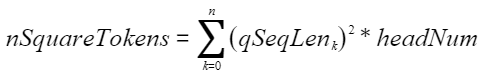
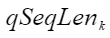 :表示qSeqLen中的第k个元素。
:表示qSeqLen中的第k个元素。
功能列表
当参数列表中
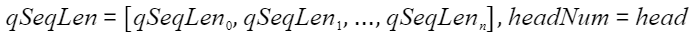 时,
时,
其对应的输入tensor的shape大小为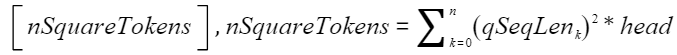 。
。
例如参数中设置
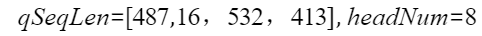
此时的输入tensor的shape大小为
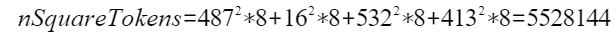
输入和输出tensor的shape为[5528144]。