功能列表
各功能共存情况
Y表示两功能不冲突,N表示两功能冲突。
|
控制可计算batch |
全量/增量分离 |
高精度 |
clamp缩放 |
压缩mask |
kv-bypass |
logN缩放 |
qkv全量化 |
BNSD维度输入 |
kv tensorlist格式输入 |
|
|---|---|---|---|---|---|---|---|---|---|---|
|
控制可计算batch |
- |
Y |
Y |
Y |
Y |
Y |
Y |
N |
Y |
Y |
|
全量/增量分离 |
- |
- |
Y |
Y |
Y |
Y |
Y |
N |
Y |
Y |
|
高精度 |
- |
- |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
|
clamp缩放 |
- |
- |
- |
- |
Y |
Y |
Y |
Y |
Y |
Y |
|
压缩mask |
- |
- |
- |
- |
- |
Y |
Y |
Y |
Y |
Y |
|
kv-bypass |
- |
- |
- |
- |
- |
- |
Y |
N |
Y |
Y |
|
logN缩放 |
- |
- |
- |
- |
- |
- |
- |
N |
N |
N |
|
qkv全量化 |
- |
- |
- |
- |
- |
- |
- |
- |
N |
N |
|
BNSD维度输入 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
N |
|
kv tensorlist格式输入 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
控制可计算batch
- 功能
指定某几个batch参与attention计算。
- 开启方式
参数“batchRunStatusEnable”置为true,并传入batchRunStatus作为输入tensor。
batchRunStatus为0,1组成的tensor。0代表该位置的batch不参与计算,1代表参与计算。
- 特殊约束
- 不支持
Atlas 推理系列产品 。 - 开启此功能时输入的cacheK, cacheV的维度为[batch, maxSeqLen, hiddenSize]。
- 不支持PA_ENCODER。
- 不支持
全量/增量分离
- 功能
当模型接入paged attention时,全量阶段选用SelfAttention且“calcType”置为PA_ENCODER,增量阶段选用PagedAttention。而当模型使用传统flash attention时,增量与全量阶段都使用SelfAttention;此时为提高计算效率,可在全量与增量阶段选用不同的calcType。
- 开启方式
全量阶段:参数“calcType”置为ENCODER。
增量阶段:参数“calcType”置为DECODER。
- 特殊约束
无。
高精度
- 功能
在进行attention计算时,Q∙KT的结果有可能溢出float16,导致算子输出tensor中间出现NAN值;此时可开启此功能,算子内部使用float32承载中间结果。
- 开启方式
参数“kernelType”置为KERNELTYPE_HIGH_PRECISION。
- 特殊约束
开启此功能时,传入的mask中需把-inf换成1。
高精度功能只在
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上才能生效。
clamp缩放
- 功能
相当于对传入的q做torch.clamp。
- 开启方式
参数“clampType”置为CLAMP_TYPE_MIN_MAX。
传入参数“clampMin”与参数“clampMax”以给出clamp的上下界。
- 特殊约束
不支持
Atlas 推理系列产品 。
压缩mask
- 功能
又名mask-free。
在长序列场景下,由于seqLen较大,需要的mask的大小也会变大。此时可开启此功能,传入压缩后的mask,以减小显存占用。
- 开启方式
参数“isTriuMask”置为1。
- 在rope场景下:将变量“maskType”置为MASK_TYPE_NORM_COMPRESS。
- 在alibi场景下:依据具体需要,将变量“maskType”置为MASK_TYPE_ALIBI_COMPRESS或MASK_TYPE_ALIBI_COMPRESS_SQRT或MASK_TYPE_ALIBI_COMPRESS_LEFT_ALIGN。
alibi压缩mask场景需传入slopes。
- 特殊约束
此功能只有“calcType”置为PA_ENCODER时生效。
- “maskType”为MASK_TYPE_ALIBI_COMPRESS或MASK_TYPE_ALIBI_COMPRESS_SQRT时,mask的维度:在
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上为[head_num, seqlen, 128]或[256, 256];Atlas 推理系列产品 上为[head_num,128//16,maxSeqlen,16]或[1,256//16,256,16]。 - “maskType”为MASK_TYPE_NORM_COMPRESS时,mask的维度:在
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上为[128,128];Atlas 推理系列产品 上为[1,128//16,128,16]。
MASK_TYPE_ALIBI_COMPRESS_LEFT_ALIGN仅支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 。此时mask的维度为[head_num, seqlen, 128]或[256, 256]。不同压缩mask的构造方法:
- 对于norm场景:
对应maskType为MASK_TYPE_NORM_COMPRESS。
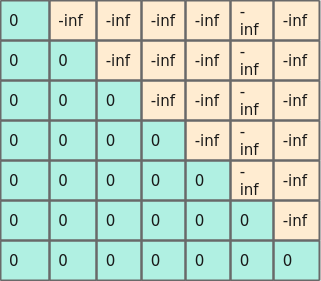
mask为128 * 128的倒三角,其中:
- 当为fp16场景时,mask如下图所示。
图1 fp16场景下的压缩norm mask
- 当为bf16/fp16高精度场景时,mask如下图所示。
图2 bf16/fp16场景下的压缩norm mask
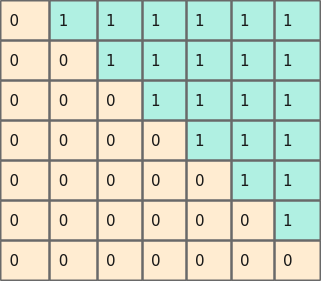
- 当为fp16场景时,mask如下图所示。
- 对于alibi场景:
alibi mask可以拆解为

其中,alibi coefficient为每个head各不相同的系数,triangularMask代表倒三角mask。压缩mask的场景下,输入tensor中的mask即为压缩后的alibi bias,slopes即为alibi coefficient。针对alibi bias的压缩有如下三种情况:
- 右对齐alibi bias
对应“maskType”为MASK_TYPE_ALIBI_COMPRESS。
如下图所示,为512 * 512的压缩前的alibi bias。
图3 512 * 512压缩前的alibi bias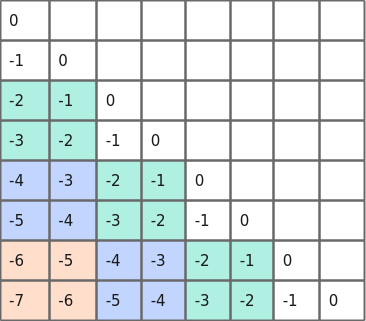
对应的压缩后的256 * 256的压缩后的alibi bias如下图所示。
图4 256 * 256压缩后的alibi bias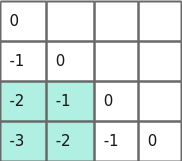
- 开平方的右对齐alibi bias
对应“maskType”为MASK_TYPE_ALIBI_COMPRESS_SQRT。
- 左对齐的alibi bias
对应“maskType”为MASK_TYPE_ALIBI_COMPRESS_LEFT_ALIGN。
压缩前的alibi bias如下图所示。
图5 压缩前的alibi bias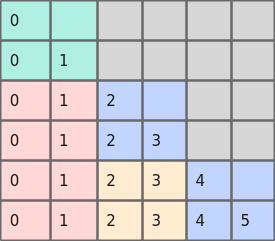
压缩后的alibi bias如下图所示。
图6 压缩后的alibi bias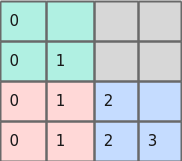
注意:左对齐的压缩mask只支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 。
- 右对齐alibi bias
- “maskType”为MASK_TYPE_ALIBI_COMPRESS或MASK_TYPE_ALIBI_COMPRESS_SQRT时,mask的维度:在
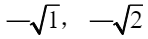
kv-bypass
- 功能
在某些场景下,客户想自行管理kvcache的过程,不想使用加速库做把kv刷新到kvcache的动作。
- 开启方式
参数“kvCacheCfg”置为K_BYPASS_V_BYPASS。同时输入tensor不传k, v。
- 特殊约束
此功能只有“calcType”为非PA_ENCODER时生效。
logN缩放
- 功能
在一般的情况下,上文计算公式中的Zoom函数,其缩放系数由参数qkScale给出。当用户想要使用logN形式的缩放函数时,可开启此功能。
- 开启方式
参数“scaleType”置为SCALE_TYPE_LOGN。
传入logN作为输入tensor。
“kernelType”置为KERNELTYPE_HIGH_PRECISION。
- 特殊约束
- 开启logN功能,“scaleType”需为SCALE_TYPE_LOGN,“calcType”需为DECODER或PA_ENCODER,分别对应增量阶段和全量阶段;
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上“calcType”为PA_ENCODER时额外需要“kernelType”为KERNELTYPE_HIGH_PRECISION。 - logN功能与量化场景不支持同时开启。
- 当“inputLayout”为TYPE_BNSD时,“ScaleType”必须为SCALE_TYPE_TOR(不支持LogN缩放)。
- 开启logN功能,“scaleType”需为SCALE_TYPE_LOGN,“calcType”需为DECODER或PA_ENCODER,分别对应增量阶段和全量阶段;
qkv全量化
- 功能
支持量化好的q, k, v传入,降低显存占用。
- 开启方式
参数“quantType”置为TYPE_QUANT_QKV_OFFLINE或TYPE_QUANT_QKV_ONLINE, 分别为离线量化与在线量化。
在线全量化需要添加四个输入tensor,分别是qkDescale、qkOffset、vpvDescale、vpvOffset,当采用离线量化时,需要在在线全量化新增的输入tensor的基础上额外传入pScale作为输入tensor。
若干输入tensor需要传入指定的维度,如下表所示:
参数
维度
数据类型
格式
npu or cpu
描述
query
[nTokens, head_num, head_size]
int8
ND
npu
query矩阵。
key
[nTokens, head_num, head_size]
int8
ND
npu
key矩阵。
value
[nTokens, head_num, head_size]
int8
ND
npu
value矩阵。
mask
float16/bf16
ND/NZ
npu
四种shape分别对应:
1.所有batch相同,方阵。
2. batch不同时的方阵。
3. batch不同时的向量。
4. alibi场景。
当maskType为undefined时不传此tensor。
seqLen
[batch]
int32
ND
cpu
等于1时,为增量或全量;大于1时,为全量。
slopes
[head_num]
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 : float16ND
npu
当maskType为alibi压缩,且mask为[256,256]时需传入此tensor,为alibi mask每个head的系数。
qkDescale
[head_num]
float
ND
npu
为Q*K^T的反量化scale参数。
qkOffset
[head_num]
int32
ND
npu
作为Q*K^T的反量化offset参数。预留tensor,需传任意非空tensor,实际暂未使用。
vpvDescale
[head_num]
float
ND
npu
quantType=2时,为P*V的反量化scale参数;quantType=3时,为V的反量化scale参数。
vpvOffset
[head_num]
int32
ND
npu
仅全量化场景传此tensor(即quantType=2或3)。quantType=2时,为P*V的反量化offset参数;quantType=3时,为V的反量化offset参数。
预留tensor,需传任意非空tensor,实际暂未使用。
pScale
[head_num]
float
ND
npu
P的离线量化scale参数,当开启离线全量化时需要传此tensor(即quantType=2)。当开启在线全量化时不传此tensor(即quantType=3)。
output
[nTokens, head_num, head_size]
float16/bf16
ND
npu
输出。
其中pScale仅在离线量化场景传入,在线量化场景则不传此输入tensor。
- 特殊约束
使用全量化时需要指定输出tensor的数据类型,具体为使用参数outDataType,该参数只能是ACL_FLOAT16或ACL_BF16。
“calctype”须为PA_ENCODER。
不支持
Atlas 推理系列产品 。
BNSD维度输入
- 功能
一般的,传入SelfAttention算子的q,k,v的维度为[batch, seqLen, head_num, head_dim],即[b, s, n, d],或者是它合轴后的变种。在某些场景下,传入[b, n, s, d]性能更好。
- 开启方式
参数“inputLayout”置为TYPE_BNSD。
输入tensor的维度如下:
- 当在
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上运行时:输入tensor
维度
query
[batch, head_num, seq_len, head_size]
cacheK
[layer, batch, head_num, seq_len, head_size]
cacheV
[layer, batch, head_num, seq_len, head_size]
- 当在
Atlas 推理系列产品 上运行时:输入tensor
维度
query
[batch, head_num, seq_len, head_size]
cacheK
[layer, batch*head_num, head_size / 16, kv_max_seq, 16]
cacheV
[layer, batch*head_num, head_size / 16, kv_max_seq, 16]
- 当在
- 特殊约束
- 此功能只有开启kv-bypass功能,即参数“kvcacheCfg”置为K_BYPASS_V_BYPASS时才可用。
- 使用BNSD维度输入时,“maskType”不能为MASK_TYPE_UNDEFINED。
kv tensorlist格式输入
- 功能
支持以tensorlist,即二级指针结构的形式而非整个tensor作为cacheK与cacheV的输入。
- 开启方式
如何构造该场景中的variantPack:
atb Tensor定义:
struct Tensor { //! \brief Tensor描述信息 TensorDesc desc; //! \brief TensorNPU内存地址。 void *deviceData = nullptr; //! \brief TensorCPU内存地址。 void *hostData = nullptr; //! \brief “deviceData”或“hostData”指向内容的内存大小。 uint64_t dataSize = 0; };variantPack中的输入tensors,在需要使能tensor list时,将对应tensor的deviceData置为nullptr,将hostData指向构造的tensorList即可。
- 特殊约束
此功能只在开启kv-bypass功能(即参数“kvcacheCfg”置为K_BYPASS_V_BYPASS),且“calcType”为DECODER时生效。