KVCacheOperation
功能
KVCache处理。当前仅支持
算子上下文
在selfattention算子内部使用,用于将k,v储存到kcache,vcache中。
图1 kvCache在SelfAttention中的位置
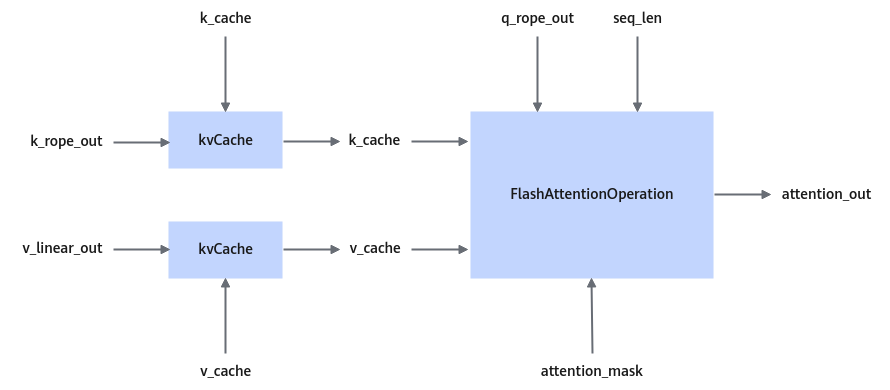
算子功能实现描述
对每一个batch:
图2 kvCache算子功能示意图
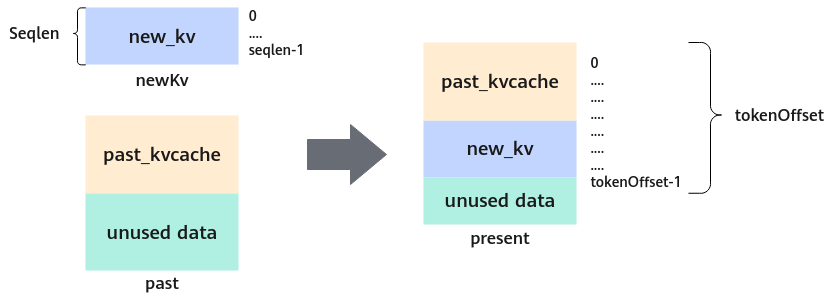
计算逻辑:
prefix_ntokens = 0
for i in range(batch):
for j in range(seqlen[i]):
cache_out[layer_id[0]][i][token_offset[i] - seqlen[i] + j][:] = newkv[prefix_ntokens + j][:] # 只会修改layer_id表示的layer的cache内容
prefix_ntokens += seqlen[i]
使用场景
用于transformer推理阶段。
举个例子,用户输入“世界最高峰”,模型续写得到的输出为“是珠穆朗玛峰”,KV Cache每一步的计算过程如下。
- 第一步生成时,缓存K,V均为空,输入为“世界最高峰”,视为三个单词,模型将按照常规方式并行计算:
- 并行计算得到每个token对应的k,v,以及注意力表示
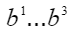 。
。 - 使用
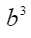 预测下一个token,得到“是”。
预测下一个token,得到“是”。 - 更新缓存,令
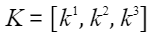 ,
,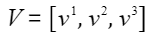 。
。
- 并行计算得到每个token对应的k,v,以及注意力表示
- 第二步生成时,计算流程如下:
- 仅将“是”输入模型,对其词向量进行映射,得到
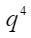 ,
,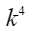 ,
,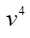 。
。 - 更新缓存,令
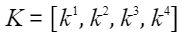 ,
,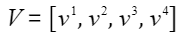 。
。 - 计算
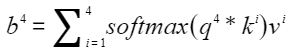 ,预测下一个token,得到“珠”。
,预测下一个token,得到“珠”。
- 仅将“是”输入模型,对其词向量进行映射,得到
定义
struct KVCacheParam {};
输入
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
newKv |
[ntokens, hiddenSize] |
float16/int8 |
ND |
待被cache的key或value。 |
|
layerId |
[1] |
int32 |
ND |
指定要cache的layer。 算子只会修改past中layer_id表示的layer的cache内容。 |
|
past |
[layer, batch, maxSeqLen, hiddenSize] |
float16/int8 与newKv保持一致 |
ND |
已经被cache的历史key或value。 |
|
tokenOffset |
[batch] |
int32 |
ND |
每batch上做完cache后的token偏移。 |
|
seqLen |
[batch] |
int32 |
ND |
每batch上newKv的seqlen。 |
输出
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
present |
[layer, batch, maxSeqLen, hiddenSize] |
float16/int8 |
ND |
cache后的key或value,作为输出。 输出present与输入past指向同一地址,即进行原地修改。 数据类型和格式应该与newkv保持一致。 |
规格约束
- seqLen 数组元素大于0,数组和为nTokens。
- tokenOffset数组元素大于0,小于maxSeqLen。
- layerId要小于past的第一维。
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 上newKv可传四维[batch, seq_len, head_num, head_size],此时head_num * head_size应该等于hiddenSize。