UB Buffer融合
【优先级】高
【描述】算子在进行多次vector计算时,如果前一次计算的结果是后一次计算的输入数据,不需要将前一次的计算结果从UB(Unified Buffer)搬运到GM后再从GM搬运到UB作为下一次计算的输入。前一次计算结果可暂存在UB上直接作为下一次计算的输入,从而减少搬入搬出次数,连续进行vector计算,提升内存使用效率。数据流图对比如下:
图1 数据流图对比
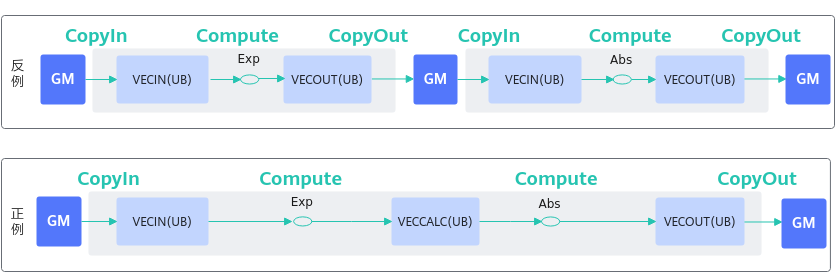
【反例】
该算子的计算逻辑为进行Exp计算后再进行Abs计算。计算过程中先把源操作数从GM搬运到UB进行Exp计算,Exp计算完成后将Exp的结果从UB搬运到GM;再从GM中把Exp的结果搬运到UB上作为Abs计算的输入,Abs计算完成后将目的操作数结果从UB搬运到GM。整个过程从GM搬进搬出共4次。当需要进行的vector计算为n次时,从GM搬进搬出共需要2n次。
class KernelSample {
public:
__aicore__ inline KernelSample() {}
__aicore__ inline void Init(__gm__ uint8_t* src0Gm, __gm__ uint8_t* dstGm)
{
src0Global.SetGlobalBuffer((__gm__ float*)src0Gm);
dstGlobal.SetGlobalBuffer((__gm__ float*)dstGm);
pipe.InitBuffer(inQueueSrc0, 1, 1024 * sizeof(float));
pipe.InitBuffer(outQueueDst, 1, 1024 * sizeof(float));
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
CopyIn1();
Compute1();
CopyOut1();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<float> src0Local = inQueueSrc0.AllocTensor<float>();
DataCopy(src0Local, src0Global, 1024);
inQueueSrc0.EnQue(src0Local);
}
__aicore__ inline void Compute()
{
LocalTensor<float> src0Local = inQueueSrc0.DeQue<float>();
LocalTensor<float> dstLocal = outQueueDst.AllocTensor<float>();
Exp(dstLocal, src0Local, 1024);
outQueueDst.EnQue<float>(dstLocal);
inQueueSrc0.FreeTensor(src0Local);
}
__aicore__ inline void CopyOut()
{
LocalTensor<float> dstLocal = outQueueDst.DeQue<float>();
DataCopy(dstGlobal, dstLocal, 1024);
outQueueDst.FreeTensor(dstLocal);
}
__aicore__ inline void CopyIn1()
{
PipeBarrier<PIPE_ALL>();
LocalTensor<float> src0Local = inQueueSrc0.AllocTensor<float>();
DataCopy(src0Local, dstGlobal, 1024);
inQueueSrc0.EnQue(src0Local);
}
__aicore__ inline void Compute1()
{
LocalTensor<float> src0Local = inQueueSrc0.DeQue<float>();
LocalTensor<float> dstLocal = outQueueDst.AllocTensor<float>();
Abs(dstLocal, src0Local, 1024);
outQueueDst.EnQue<float>(dstLocal);
inQueueSrc0.FreeTensor(src0Local);
}
__aicore__ inline void CopyOut1()
{
LocalTensor<float> dstLocal = outQueueDst.DeQue<float>();
DataCopy(dstGlobal, dstLocal, 1024);
outQueueDst.FreeTensor(dstLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueSrc0;
TQue<QuePosition::VECOUT, 1> outQueueDst;
GlobalTensor<float> src0Global, dstGlobal;
};
【正例】
在UB上进行连续vector计算时,前一次的结果可直接作为后一次计算的输入,继续在UB上进行计算,不需要中间的搬运搬出,只需在开始计算时将源操作数搬运到UB,以及全部计算结束后将最终结果从UB搬运到GM,共2次搬进搬出。
class KernelSample {
public:
__aicore__ inline KernelSample() {}
__aicore__ inline void Init(__gm__ uint8_t* src0Gm, __gm__ uint8_t* dstGm)
{
src0Global.SetGlobalBuffer((__gm__ float*)src0Gm);
dstGlobal.SetGlobalBuffer((__gm__ float*)dstGm);
pipe.InitBuffer(inQueueSrc0, 1, 1024 * sizeof(float));
pipe.InitBuffer(outQueueDst, 1, 1024 * sizeof(float));
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<float> src0Local = inQueueSrc0.AllocTensor<float>();
DataCopy(src0Local, src0Global, 1024);
inQueueSrc0.EnQue(src0Local);
}
__aicore__ inline void Compute()
{
LocalTensor<float> src0Local = inQueueSrc0.DeQue<float>();
LocalTensor<float> dstLocal = outQueueDst.AllocTensor<float>();
Exp(dstLocal, src0Local, 1024);
Abs(dstLocal, dstLocal, 1024);
outQueueDst.EnQue<float>(dstLocal);
inQueueSrc0.FreeTensor(src0Local);
}
__aicore__ inline void CopyOut()
{
LocalTensor<float> dstLocal = outQueueDst.DeQue<float>();
DataCopy(dstGlobal, dstLocal, 1024);
outQueueDst.FreeTensor(dstLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueSrc0;
TQue<QuePosition::VECOUT, 1> outQueueDst;
GlobalTensor<float> src0Global, dstGlobal;
};
父主题: 内存优化