算子类实现
根据上一节介绍,核函数中会调用算子类的Init和Process函数,本节具体讲解如何基于编程范式实现算子类。
根据矢量编程范式对Add算子的实现流程进行设计的思路如下,矢量编程范式请参考流水编程范式中的矢量编程部分,设计完成后得到的Add算子实现流程图参见图1:
- Add算子的实现流程分为3个基本任务:CopyIn,Compute,CopyOut。CopyIn任务负责将Global Memory上的输入Tensor xGm和yGm搬运至Local Memory,分别存储在xLocal,yLocal,Compute任务负责对xLocal,yLocal执行加法操作,计算结果存储在zLocal中,CopyOut任务负责将输出数据从zLocal搬运至Global Memory上的输出Tensor zGm中。
- CopyIn,Compute任务间通过VECIN队列inQueueX,inQueueY进行通信和同步,Compute,CopyOut任务间通过VECOUT队列outQueueZ进行通信和同步。
- 任务间交互使用到的内存、临时变量使用到的内存统一使用pipe内存管理对象进行管理。
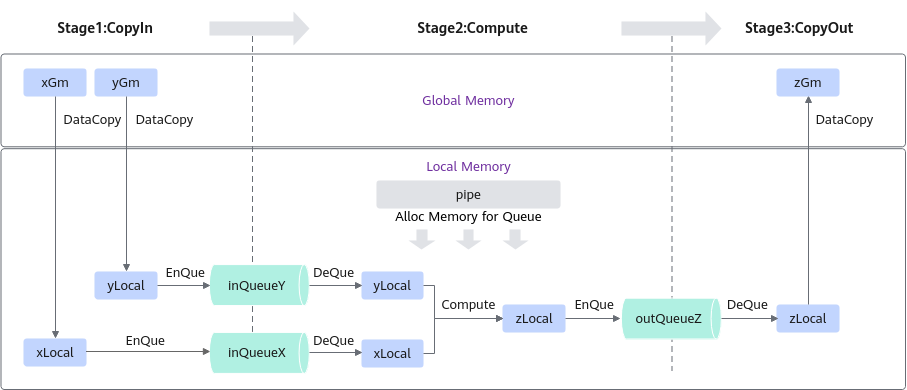
算子类中主要实现上述流程,包含对外开放的初始化Init函数和核心处理函数Process,Process函数中会对上图中的三个基本任务进行调用;同时包括一些算子实现中会用到的私有成员,比如上图中的Global Tensor和VECIN、VECOUT队列等。KernelAdd算子类具体成员如下:
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作
__aicore__ inline void Process(){}
private:
// 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用
__aicore__ inline void CopyIn(int32_t progress){}
// 计算函数,完成Compute阶段的处理,被核心Process函数调用
__aicore__ inline void Compute(int32_t progress){}
// 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用
__aicore__ inline void CopyOut(int32_t progress){}
private:
TPipe pipe; //Pipe内存管理对象
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //输入数据Queue队列管理对象,QuePosition为VECIN
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //输出数据Queue队列管理对象,QuePosition为VECOUT
GlobalTensor<half> xGm, yGm, zGm; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出
};
Init函数实现
初始化函数主要完成以下内容:
- 设置输入输出Global Tensor的Global Memory内存地址。
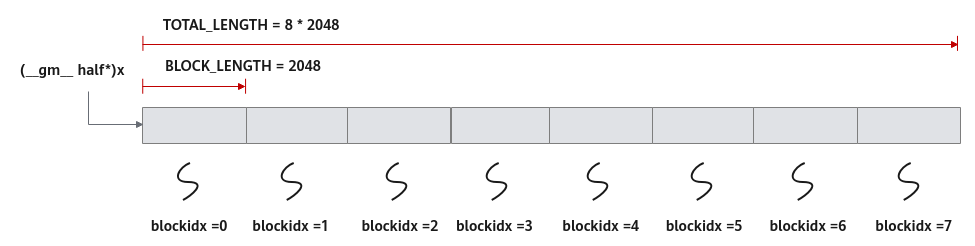
本样例中使用多核并行计算,即把数据进行分片,分配到多个核上进行处理。Ascend C核函数是在一个核上的处理函数,所以只处理部分数据,需要在初始化函数中获取该核函数需要处理的输入输出在Global Memory上的内存偏移地址,并将该偏移地址设置在Global Tensor中。
以获取输入x在Global Memory上的内存偏移地址为例:
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
本样例中的分配方案是:数据整体长度TOTAL_LENGTH为8* 2048,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048。x + BLOCK_LENGTH * GetBlockIdx()即为单核处理程序中x在Global Memory上的内存偏移地址,获取偏移地址后,使用GlobalTensor类的SetGlobalBuffer接口设定该核上Global Memory的起始地址以及长度。具体示意图请参考图2。
- 通过Pipe内存管理对象为输入输出Queue分配内存。
比如,为输入x的Queue分配内存,可以通过如下代码段实现:
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half))
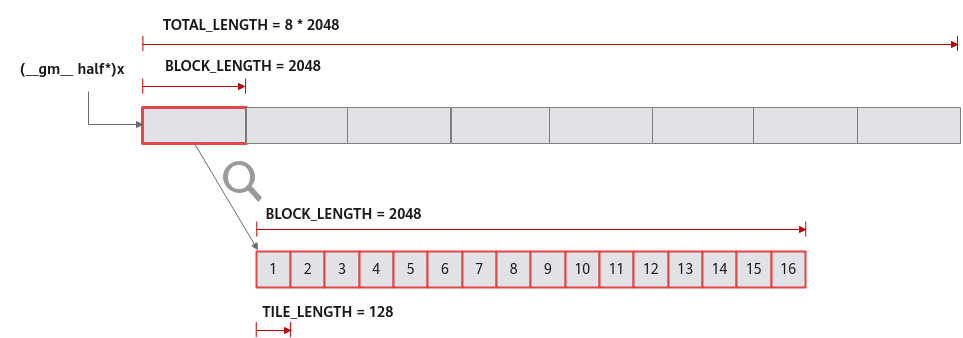
对于单核上的处理数据,可以进行数据切块(Tiling),在本示例中,仅作为参考,将数据切分成8块(并不意味着8块就是性能最优)。切分后的每个数据块再次切分成2块,即可开启double buffer,实现流水线之间的并行。double buffer功能介绍请参考double buffer。
这样单核上的数据(2048个数)被切分成16块,每块TILE_LENGTH(128)个数据。上文代码表示Pipe为inQueueX分配了两块大小为TILE_LENGTH * sizeof(half)个字节的内存块,每个内存块能容纳TILE_LENGTH(128)个half类型数据。数据切分示意图如图3所示。
具体的初始化函数代码如下:
constexpr int32_t TOTAL_LENGTH = 8 * 2048; // total length of data
constexpr int32_t USE_CORE_NUM = 8; // num of core used
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core
constexpr int32_t TILE_NUM = 8; // split data into 8 tiles for each core
constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // seperate to 2 parts, due to double buffer
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
Process函数实现
基于矢量编程范式,将核函数的实现分为3个基本任务:CopyIn,Compute,CopyOut。Process函数中通过如下方式调用这三个函数。
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// tiling strategy, pipeline parallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
根据编程范式上面的算法分析,将整个计算拆分成三个Stage,用户单独编写每个Stage的代码,三阶段流程示意图参见图1,具体流程如下:
- Stage1:CopyIn函数实现。
__aicore__ inline void CopyIn(int32_t progress) { // alloc tensor from queue memory LocalTensor<half> xLocal = inQueueX.AllocTensor<half>(); LocalTensor<half> yLocal = inQueueY.AllocTensor<half>(); // copy progress_th tile from global tensor to local tensor DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH); DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH); // enque input tensors to VECIN queue inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); } - Stage2:Compute函数实现。
- 使用DeQue从VecIn中取出LocalTensor。
- 使用Ascend C接口Add完成矢量计算。
- 使用EnQue将计算结果LocalTensor放入到VecOut的Queue中。
- 使用FreeTensor释放不再使用的LocalTensor。
__aicore__ inline void Compute(int32_t progress) { // deque input tensors from VECIN queue LocalTensor<half> xLocal = inQueueX.DeQue<half>(); LocalTensor<half> yLocal = inQueueY.DeQue<half>(); LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>(); // call Add instr for computation Add(zLocal, xLocal, yLocal, TILE_LENGTH); // enque the output tensor to VECOUT queue outQueueZ.EnQue<half>(zLocal); // free input tensors for reuse inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); } - Stage3:CopyOut函数实现。
- 使用DeQue接口从VecOut的Queue中取出LocalTensor。
- 使用DataCopy接口将LocalTensor拷贝到GlobalTensor上。
- 使用FreeTensor将不再使用的LocalTensor进行回收。
__aicore__ inline void CopyOut(int32_t progress) { // deque output tensor from VECOUT queue LocalTensor<half> zLocal = outQueueZ.DeQue<half>(); // copy progress_th tile from local tensor to global tensor DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH); // free output tensor for reuse outQueueZ.FreeTensor(zLocal); }