GetTensorC
功能说明
Iterate后,获取一块C矩阵片,可以直接输出到GM tensor中,也可以输出到VECIN tensor中。
该接口和Iterate接口配合使用,用于在调用Iterate完成迭代计算后,获取一片baseM * baseN大小的矩阵分片。
迭代获取C矩阵分片的过程分为同步和异步两种模式:
- 同步:执行完一次Iterate后执行一次GetTensorC,需要同步等待C矩阵分片获取完成。
- 异步:调用Iterate后,无需立即调用GetTensorC同步等待,可以先执行其他逻辑,待需要获取结果时再调用GetTensorC。异步方式可以减少同步等待,提高并行度,开发者对计算性能要求较高时,可以选用该方式。
函数原型
- 同步模式
- 获取C矩阵,输出至VECIN
__aicore__ inline void GetTensorC(const LocalTensor<DstT>& co2Local, uint8_t enAtomic = 0, bool enSequentialWrite = false)
- 获取C矩阵,输出至GM
__aicore__ inline void GetTensorC(const GlobalTensor<DstT>& gm, uint8_t enAtomic = 0, bool enSequentialWrite = false)
- 获取C矩阵,同时输出至GM和VECIN
Atlas 200I/500 A2推理产品暂不支持同时输出至GM和VECIN。
template <bool sync = true>
__aicore__ inline void GetTensorC(const GlobalTensor<DstT> &c, const LocalTensor<DstT> &cLocal, uint8_t enAtomic = 0, bool enSequentialWrite = false)
- 获取C矩阵,输出至VECIN
- 异步模式
Atlas 200I/500 A2推理产品不支持异步模式。
Atlas A2训练系列产品/Atlas 800I A2推理产品支持异步模式。- 获取C矩阵,输出至VECIN
__aicore__ inline void GetTensorC(const LocalTensor<DstT>& co2Local, uint8_t enAtomic = 0, bool enSequentialWrite = false)
- 获取API接口返回的的GM上的C矩阵,后续使用过程由开发者自行控制
C矩阵输出到VECIN时, VECIN对应的物理位置Unified Buffer的大小会影响Matmul计算的力度,Unified Buffer的大小过小时,无法充分利用硬件算力。提供该接口支持返回API框架申请的GM上的C矩阵,由开发者自行控制后续使用过程。
注意,在初始化时,C矩阵的逻辑位置应设置为TPosition::VECIN,调用该接口获取GM上的C矩阵后,自行拷贝到Unified Buffer。
template <bool sync = true>
__aicore__ inline GlobalTensor<DstT> GetTensorC(uint8_t enAtomic = 0, bool enSequentialWrite = false)
- 获取C矩阵,输出至VECIN
以下接口待废弃,新开发内容不要使用该接口。
template <bool sync = true, bool doPad = false>
__aicore__ inline void GetTensorC(const LocalTensor<DstT>& c, uint8_t enAtomic = 0, bool enSequentialWrite = false, uint32_t height = 0, uint32_t width = 0, uint32_t srcGap = 0, uint32_t dstGap = 0)
参数说明
参数名 |
描述 |
|---|---|
sync |
设置同步或者异步模式:同步模式设置为true;异步模式设置为false。 |
参数名 |
输入/输出 |
描述 |
|---|---|---|
c/co2Local |
输出 |
取出C矩阵到VECIN,数据格式仅支持NZ。 针对Atlas A2训练系列产品/Atlas 800I A2推理产品支持的数据类型为half、float、bfloat16_t 针对Atlas推理系列产品AI Core支持的数据类型为half、float Atlas 200I/500 A2推理产品支持的数据类型为half、float、bfloat16_t |
Gm |
输出 |
取出C矩阵到GM,数据格式可以为ND或NZ。 针对Atlas A2训练系列产品/Atlas 800I A2推理产品支持的数据类型为half、float、bfloat16_t 针对Atlas推理系列产品AI Core支持的数据类型为half、float Atlas 200I/500 A2推理产品支持的数据类型为half、float、bfloat16_t |
enAtomic |
输入 |
是否开启Atomic操作,默认值为0。 参数取值: 0:不开启Atomic操作 1:开启AtomicAdd累加操作 2:开启AtomicMax求最大值操作 3:开启AtomicMin求最小值操作 对于Atlas推理系列产品AI Core,只有输出位置是GM才支持开启Atomic操作。 对于Atlas 200I/500 A2推理产品,只有输出位置是GM才支持开启Atomic操作。 |
enSequentialWrite |
输入 |
是否开启连续写模式到GM(连续写,写入[baseM,baseN];非连续写,写入[singleCoreM、singleCoreN]中对应的位置),默认值false(非连续写模式)。 对于Atlas 200I/500 A2推理产品,只支持非连续写模式。 |
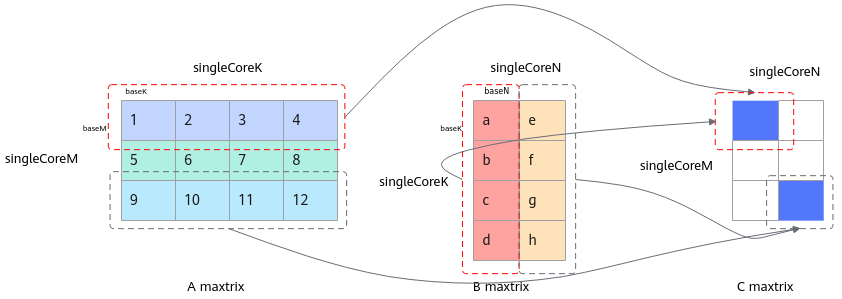
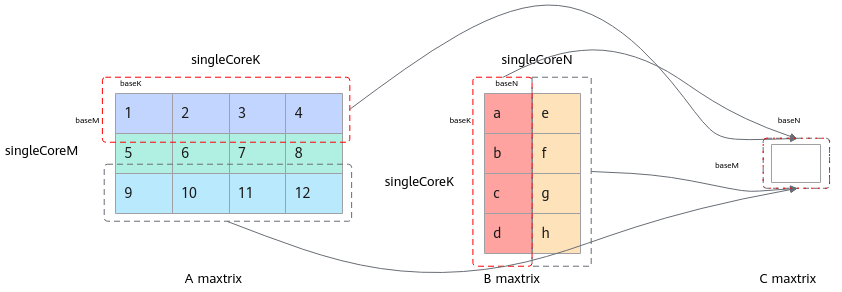
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
Atlas 200I/500 A2推理产品
注意事项
- 传入的C矩阵地址空间大小需要保证不小于baseM * baseN。
- 异步场景时,需要使用一块临时空间来缓存Iterate计算结果,调用GetTensorC时会在该临时空间中获取C的矩阵分片。临时空间通过
SetWorkspace接口进行设置。SetWorkspace接口需要在Iterate接口之前调用。
调用示例
- 获取C矩阵,输出至VECIN
// 同步模式样例 while (mm. Iterate ()) { mm. GetTensorC (ubCmatrix); } // 异步模式样例 mm.template Iterate<false>(); …… …… for (int i = 0; i < singleM/baseM*singleN/baseN; ++i) { mm.GetTensorC<false> (ubCmatrix); } - 获取C矩阵,输出至GM,同步模式样例
while (mm.Iterate()) { mm.GetTensorC(gm); } - 获取C矩阵,同时输出至GM和VECIN,同步模式样例
while (mm.Iterate()) { mm.GetTensorC(gm, ubCmatrix); } - 获取API接口返回的的GM上的C矩阵,手动拷贝至UB,异步模式样例
// BaseM * BaseN = 128 *256 mm.SetTensorA(gmA); mm.SetTensorB(gmB); mm.SetTail(singleM, singleN, singleK); mm.template Iterate<false>(); ………… for (int i = 0; i < singleM / baseM * singleN / baseN; ++i) { // 获取每次计算的BaseM*BaseN的数据(128*256) GlobalTensor<T> gm = mm.template GetTensorC<false>(); for(int j = 0; j < 4; ++j) { LocalTensor local = que.AllocTensor<half>(); //分配64*128大小的UB空间 DataCopy(local, global + 64*128 * i, 64*128); // 将GM的数据拷贝进UB中,进行后续的Vector操作 ... Vector 操作 } }