简介
学习矩阵编程章节之前,请先了解编程模型中核函数和矩阵编程范式相关知识。
基于Ascend C方式实现矩阵算子的流程如下图所示。
图1 矩阵算子实现流程
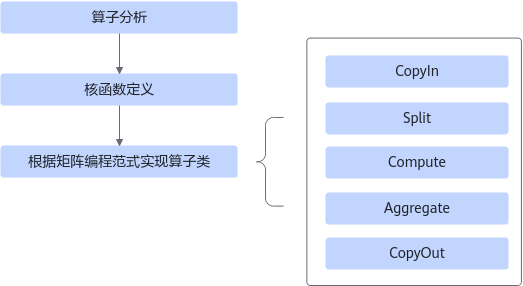
- 算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend C接口。
- 核函数定义:定义Ascend C算子入口函数。
- 根据矩阵编程范式实现算子类:完成核函数的内部实现,调用私有成员函数CopyIn、SplitA、SplitB、Compute、Aggregate、CopyOut完成矩阵算子的五级流水操作。
下文将以Matmul算子为例对上述步骤进行详细介绍,Matmul算子的代码框架如下,完整代码请参见实现样例。
#include "kernel_operator.h"
using namespace AscendC;
// 根据编程范式实现算子类
class KernelMatmul {
public:
__aicore__ inline void Init(GM_ADDR a, GM_ADDR b, GM_ADDR c)
{
// ...
}
__aicore__ inline void Process()
{
CopyIn();
SplitA();
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<float> c2Local = outQueueCO2.AllocTensor<float>();
// split matrix b into 2 parts, [32, 16] and [32, 16]
for (int i = 0; i < 2; ++i) {
SplitB(b1Local, i);
Compute(a2Local);
Aggregate(c2Local, i);
}
inQueueB1.FreeTensor(b1Local);
inQueueA2.FreeTensor(a2Local);
outQueueCO2.EnQue<float>(c2Local);
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
// ...
}
__aicore__ inline void SplitA()
{
// ...
}
__aicore__ inline void SplitB(const LocalTensor<half>& b1Local, const int bSplitIdx)
{
// ...
}
__aicore__ inline void Compute(const LocalTensor<half>& a2Local)
{
// ...
}
__aicore__ inline void Aggregate(const LocalTensor<float>& c2Local, const int bSplitIdx)
{
// ...
}
__aicore__ inline void CopyOut()
{
// ...
}
private:
// ...
};
//核函数定义
extern "C" __global__ __aicore__ void matmul_custom(GM_ADDR a, GM_ADDR b, GM_ADDR c)
{
KernelMatmul op;
op.Init(a, b, c);
op.Process();
}
父主题: 矩阵编程