在线推理
使用方法:
运行脚本examples/llama/generate_llama_7B_tp2_pp2.sh,脚本内容如下:
python -m torch.distributed.launch $DISTRIBUTED_ARGS ./tasks/inference/inference_llama.py
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load "${CHECKPOINT}" \
--num-attention-heads 32 \
--max-position-embeddings 2048 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path "$VOCAB_FILE" \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seq-length 256 \
--max-new-tokens 64 \
--seed 42
参数说明:
- TP、PP均为常规的分布式参数设定。
- load:加载训练好的模型进行在线推理,路径为训练时生成的ckpt文件夹。
- tokenizer-type:进行分词与id化时选用的处理类型。
概述
支持对大模型进行多维并行推理。输入模型定义、权重文件和配置文件,输出结果,输出结果用于下游任务和与用户进行交互。接口定义位于“tasks/inference/inference_llama.py”文件中。
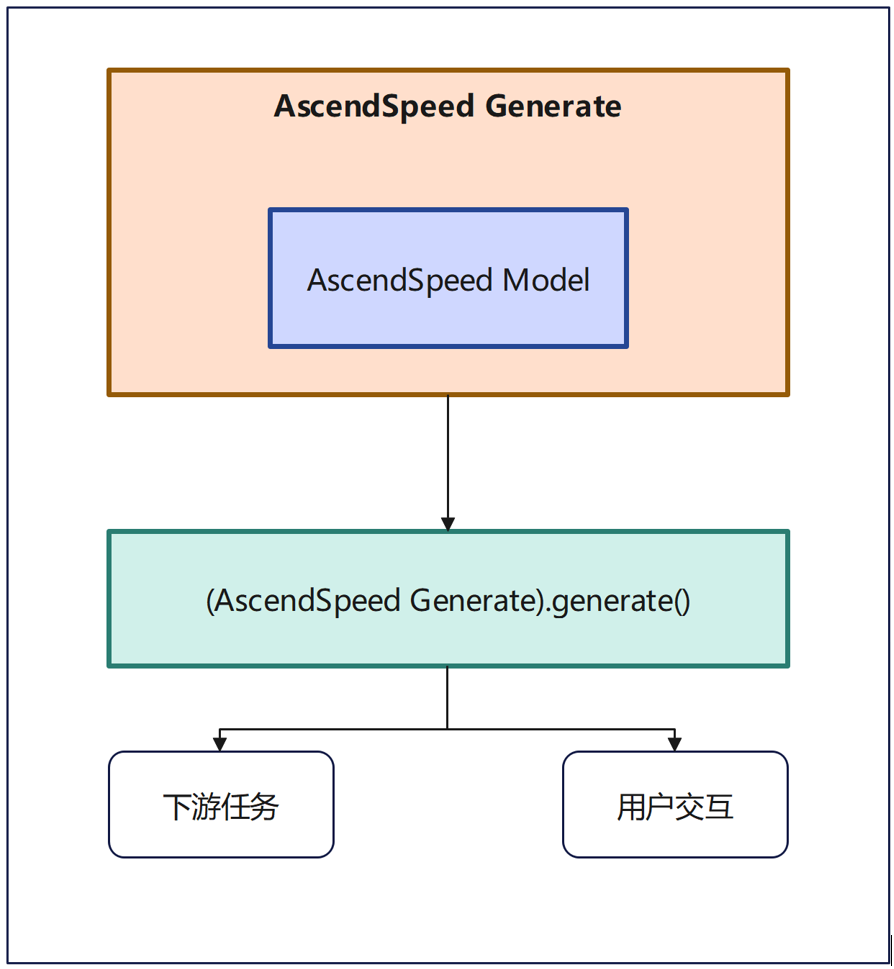
在实现中主要有以下的两方面内容:
模型加载接口:
# 首先按照megatron的方式初始化环境
initialize_megatron(extra_args_provider=add_text_generate_args,
args_defaults={'no_load_rng': True,
'no_load_optim': True})
# 获取初始化参数对象
args = get_args()
# 加载模型
model = LlamaModel.from_pretrained(
model_provider=model_provider,
pretrained_model_name_or_path=args.load
)
# 设置指令模板
system_template = ""
dialog_template = "{instruction}"
template = system_template + dialog_template
# 分别执行以下3个测试用例
task1(args, model, system_template=system_template, dialog_template=dialog_template)
task2(args, model, system_template=system_template, dialog_template=dialog_template)
task3(args, model, system_template=system_template, dialog_template=dialog_template)
模型推理接口:
responses = model.generate(
instruction,
do_sample=True,
top_k=args.top_k,
top_p=args.top_p,
temperature=args.temperature,
max_length=args.max_length,
max_new_tokens=args.max_new_tokens,
)
参数说明:
- instruction:str类型,用户构造的输入文本。
- do_sample:bool类型,是否使用采样,否则使用贪心的解码方式。
- top_k:int型,保留的用于top-k过滤后最高概率词汇表token的数量。生成文本时,模型会根据预测的概率值选择前k个最有可能的词语作为候选。
- top_p:float型,如果设置为浮点<1,则仅保留概率加起来为`top_p`或更高的最小最可能token集以便生成。即设定阈值,只选择概率累加大于该阈值的词进行生成,而忽略概率较小的词。
- temperature:float型,调节下一个token的概率,控制生成文本的多样性,即控制模型生成的文本的创造性程度。
- max_length:int型,可以生成的token的最大长度,等于prompt + max_new_tokens,当max_new_tokens也设定时效果会被覆盖。
- max_new_tokens:int型,生成的token的最大长度,忽略prompt中的token的数量。
测试用例(以多轮交互式问答为例)
首先定义获取上下文函数:q,r分别表示question与response
def get_context(content):
res = system_template
for q, r in content:
if r is None:
res += dialog_template.format(instruction=q)
else:
res += dialog_template.format(instruction=q) + r
return res
此后,通过history的记录可以支持多轮交互式对话,会以元组的形式记录提示词和对应的输出:
context = "\n"
for q, r in histories:
context += f"{input_template}{q}\n\n{response_template}\n{r}\n\n"
for output in responses:
if dist.get_rank() == 0:
subprocess.call(command_back)
logging.info("%s\n\n%s\n%s\n", context, response_template, output)
histories.append((prompt, output))
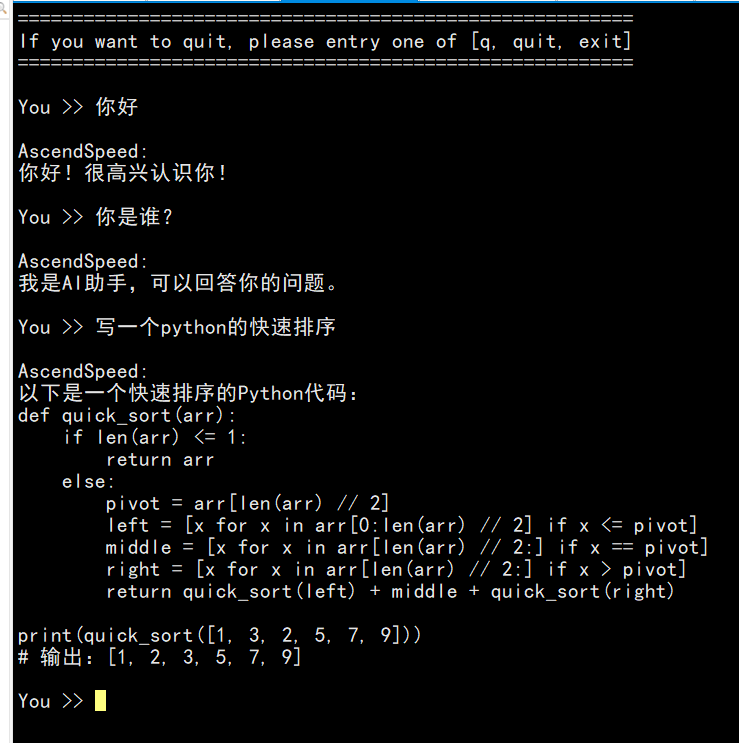
在线推理之交互式问答结果展示如下:
父主题: 解决方案