模型微调
使用方法
运行脚本参数配置示例:
deepspeed pretrain_llama.py \ --DDP-impl local \ --tensor-model-parallel-size 1 \ --pipeline-model-parallel-size 1 \ --num-layers 40 \ --hidden-size 5120 \ --ffn-hidden-size 13824 \ --num-attention-heads 40 \ --micro-batch-size 2 \ --global-batch-size 16 \ --seq-length 2048 \ --zero-stage 2 \ --lora-target-modules gate_proj up_proj down_proj \ --fp16 | tee logs/train.log
参数说明:
- --lora-target-modules:必选参数,Lora目标模块,字符串列表,无默认值。每一个字符串是需要进行 LoRA 的层的名称。
- --lora-load:可选参数,lora模型checkpoint所在目录,默认为空。
- --lora-r:可选参数,int型,默认值16。
- --lora-alpha:可选参数,int型,默认值32。
- --lora-register-forward-hook:当模型被PP切分时候,梯度传播可能会切断,因此要将每个PP的输入层的输出tensor设置为需要计算梯度。默认值为llama可能的输入层。
概述
- peft Lora只支持torch.nn.LinearandConv1D两种类型Module新增模块,AscendSpeed中的线性层定义不一致,需要进行适配:
if isinstance(target, (ColumnParallelLinear, RowParallelLinear)): if kwargs["fan_in_fan_out"]: warnings.warn( "fan_in_fan_out is set to True but the target module is `torch.nn.Linear`. " "Setting fan_in_fan_out to False." ) kwargs["fan_in_fan_out"] = lora_config.fan_in_fan_out = False new_module = LoraParallelLinear(adapter_name=adapter_name, parallel_linear=target, **kwargs) - peft Lora中的LoraLayer层是```torch.nn.Linear```类型的线性层,不能很好的兼容AscendSpeed中定义的多维并行中使用的线形层,需要重新定义,用AscendSpeed中的并行linear代替原有的Linear类。在构建Lora模型的时候用仓上模块替换原有的模块:
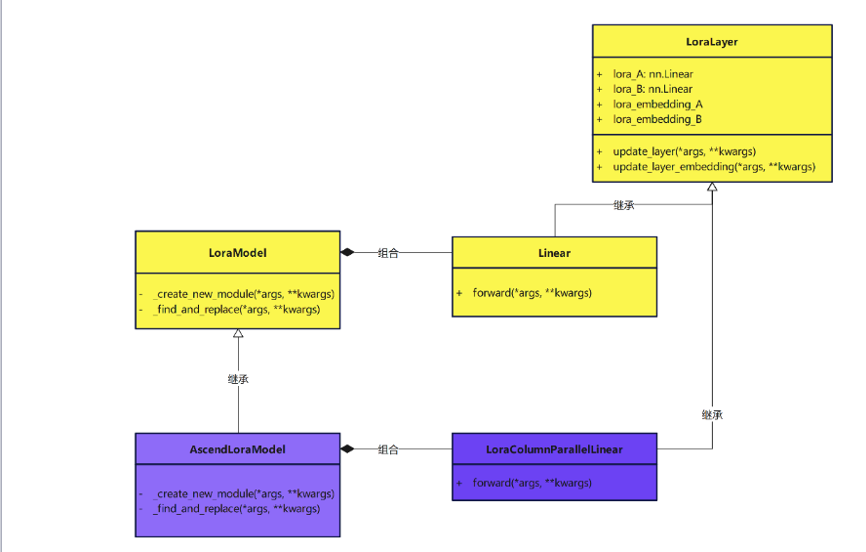
在asendspeed仓上进行LoraParallelLayer定义A,B层的实现时,采用的方式是并行化处理:当需要对A进行并行化处理时,对lora_A做行切分,而此时的lora_B应该是完整的线性层;否则的话将lora_B做列切分,而此时的lora_A则保持完整的线性层。
if self.is_paralle_a:
lora_a = RowParallelLinear(input_size=self.in_features, output_size=r, bias=False,
input_is_parallel=True, skip_bias_add=True,
dtype=torch.float32) # lora需要强制升格到32位精度,否则会溢出
lora_b = nn.Linear(in_features=r, out_features=self.out_features, bias=False, dtype=torch.float32)
else:
lora_a = nn.Linear(in_features=self.in_features, out_features=r, bias=False, dtype=torch.float32)
lora_b = ColumnParallelLinear(input_size=r, output_size=self.out_features, bias=False,
gather_output=False, dtype=torch.float32)
self.lora_A.update(nn.ModuleDict({adapter_name: lora_a}))
self.lora_B.update(nn.ModuleDict({adapter_name: lora_b}))
在ascendspeed/model文件夹下,根据“lora_modules.py”与l“ora_utils.py”进行lora微调。使用lora对模型进行处理时候,调用的配置函数为“def handle_mode_with_lora()”
实现过程需要在forward处理中加入lora_result:
lora_a = self.lora_A[self.active_adapter]
lora_b = self.lora_B[self.active_adapter]
lora_dropout = self.lora_dropout[self.active_adapter]
scaling = self.scaling[self.active_adapter]
lora_result = lora_a(lora_dropout(x))
if isinstance(lora_result, tuple):
lora_result = lora_result[0]
lora_result = lora_b(lora_result)
if isinstance(lora_result, tuple):
lora_result = lora_result[0]
lora_result = lora_result * scaling
result += lora_result
微调结果:
在LLaMA Alpaca 13B上分别通过deepspeed与megatron进行测度,结果为
megatron:1000steps@平均偏差:0.19% deeepspeed:1000steps@平均偏差:0.25%
父主题: 解决方案