SequenceParallelism序列并行
概述
序列并行指对Dropout、LayerNorm按照sequence轴进行切分,在切分后原来TP中的all-reduce会被拆分成reduce-scatter、all-gather算子,实现了在不增加通信量的情况下,降低了每卡上的计算量与activation内存需求。
在下图中,g所代表的就是前向all-gather,反向reduce-scatter;而g-则相反。
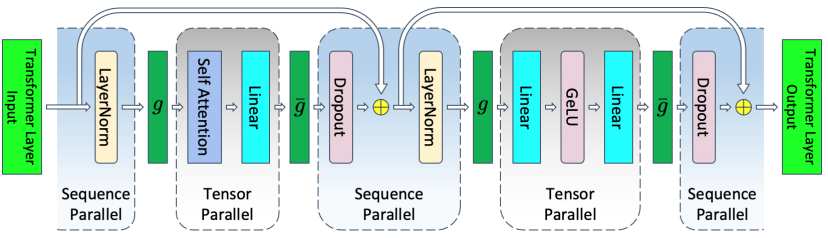
在ascendspeed/mpu/mapping.py文件下,定义了相关函数的实现。
def gather_from_sequence_parallel_region(input_, tensor_parallel_output_grad=True):
return _GatherFromSequenceParallelRegion.apply(input_, tensor_parallel_output_grad)
def reduce_scatter_to_sequence_parallel_region(input_):
return _ReduceScatterToSequenceParallelRegion.apply(input_)
def scatter_to_sequence_parallel_region(input_):
return _ScatterToSequenceParallelRegion.apply(input_):
gather在池化特定的token(比如序列的起始)的隐藏状态中有使用:
if self.sequence_parallel:
hidden_states = gather_from_sequence_parallel_region(
hidden_states,
tensor_parallel_output_grad=False)
reduce_scatter在RowParallelLinear中,行切割涉及到最后的reduce操作,假设使用SP,则在会将所有partition在输出时进行此步操作:
if self.sequence_parallel_enabled:
output_ = reduce_scatter_to_sequence_parallel_region(output_parallel)
scatter
同文件夹下的layer.py文件中linear_with_grad_accumulation_and_async_allreduce函数考虑是否使用序列化并行。
def linear_with_grad_accumulation_and_async_allreduce(
input_: torch.Tensor,
weight: torch.Tensor,
bias: Optional[torch.Tensor],
sequence_parallel_enabled: bool,
) -> torch.Tensor:
args = [
input_,
weight,
bias,
sequence_parallel_enabled,
]
with torch.cuda.amp.autocast(enabled=False):
return LinearWithGradAccumulationAndAsyncCommunication.apply(*args)
linear_with_grad_accumulation_and_async_allreduce.warned = False
在序列并行性的情况下,输入梯度的减少散射与权重梯度的计算异步完成。
参数情况:
- input:输入的张量。
- weight:输入的权重。
- bias:偏置项。
- sequence_parallel_enabled:指示使用序列并行化,因此在正向传递中,输入全部收集,而反向传递中,输入梯度减少散射。
此外在RowParallelLinear在使能开关的设置中,参数位于argumens.py文件的_add_distributed_args函数中。
功能使用
序列并行功能的定义位于“ascendspeed/mpu/mapping.py”文件下。
通过修改--sequence-parallel的值来使能,输入值为bool型,默认值False。需要注意的是当TP值为1时,序列并行为关闭。
if args.tensor_model_parallel_size == 1:
args.sequence_parallel = False
训练脚本参数配置示例,加粗部分为流水并行功能配置参数示例:
python -m torch.distributed.run $DISTRIBUTED_ARGS \
pretrain_bloom.py \
--num-layers $NLAYERS \
--hidden-size $NHIDDEN \
--num-attention-heads $NHEADS \
--seq-length $SEQ_LEN \
--max-position-embeddings $SEQ_LEN \
--micro-batch-size $MICRO_BATCH_SIZE \
--rampup-batch-size 192 16 9_765_625 \
--global-batch-size $GLOBAL_BATCH_SIZE \
--deepspeed \
--deepspeed_config ${config_json} \
--zero-stage ${ZERO_STAGE} \
--deepspeed-activation-checkpointing \
--distributed-backend nccl \
--sequence-parallel
父主题: 分布式技术