PipelineParallelism流水并行
概述
流水并行是指按顺序将模型切分为不同的部分至不同的处理器上运行。 每个处理器上只有部分参数,因此每个部分的模型消耗处理器的显存成比例减少。
模型在多个NPU上垂直(即分层)拆分,因此只有一个或多个模型放置在单个NPU上。每个NPU并行处理流水线的不同阶段,并处理batch的一部分数据。
- 在前向传播过程中,每个设备将中间的激活传递给下一个阶段。
- 在后向传播过程中,每个设备将张量的梯度传回给前一个流水线阶段。
而virtual pipeline技术,在device数量不变的情况下,通过split model从而划分出更多的pipeline stage以获得更多的通信量,降低空泡的比率,减少step e2e的用时。
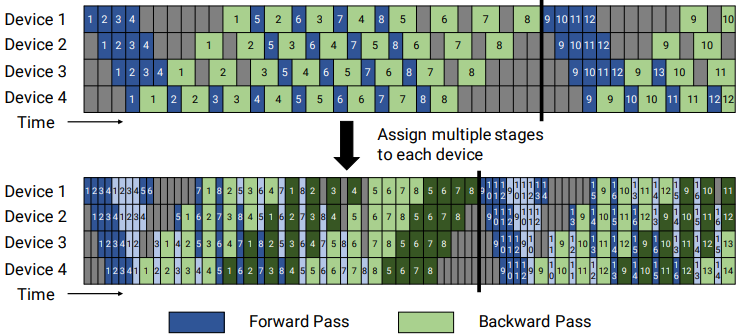
具体机制,结合图片进行分析:
上图显示了默认的非交织1F1B调度,下图显示了交织1F1B调度,其中每个设备被分配多个块(在本例中为2),深色表示第一个块,浅色表示第二个块。virtual pipeline 是按照virtual_pipeline_stage 概念减小切分粒度,以 virtaul_pipeline_stage=2 为例,将 0-1 层放 Device1, 2-3 层放在 Device2,...,6-7 层放到 Device4,8-9 层继续放在 Device1,10-11 层放在 Device2,...,14-15 层放在 Device4。在step中间的稳定阶段是 1F1B 的形式,叫做 1F1B-interleaving。按照这种方式,Device之间的点对点通信次数(量)直接翻了virtual_pipeline_stage倍,但空泡比率也是降低为原来的virtual_pipeline_stage倍。
其次,可以使用“全向前,全向后”版本的调度,但有较高的内存占用空间,因此开发了一个交织的调度,以适应内存高效的1F1B计划,且要在批处理为流水线并行度的整数倍(流水中的设备数量)。例如,有4台设备,批中的微批数量必须是4的倍数。
功能使用
通过修改输入参数--pipeline-model-parallel-size的值来使能流水并行,输入值为int型,默认值为1;通过修改--num-layers-per-virtual-pipeline-stage的值来使能虚拟化流水并行,使用前需先配置--tensor-model-parallel-size、--pipeline-model-parallel-size、--model-parallel-size,输入值为int型,无默认值。
训练脚本参数配置示例,加粗部分为流水并行功能配置参数示例:
python -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_llama.py \
--DDP-impl local \
--use-contiguous-buffers-in-local-ddp \
--tensor-model-parallel-size 4 \
--pipeline-model-parallel-size 2 \
--model-parallel-size 2 \
--num-layers-per-virtual-pipeline-stage 4 \
--num-layers 30 \
--hidden-size 6656 \
--ffn-hidden-size 17920 \
--num-attention-heads 52 \
--micro-batch-size 1 \
--global-batch-size 32 \
--seq-length 2048
具体而言,流水化并行功能与虚拟化流水并行功能的初始化定义位于“ascendspeed/core/parallel_state.py”文件中:
def initialize_model_parallel(
tensor_model_parallel_size: int = 1,
pipeline_model_parallel_size: int = 1,
virtual_pipeline_model_parallel_size: Optional[int] = None,
pipeline_model_parallel_split_rank: Optional[int] = None,
use_fp8: bool = False,
) -> None:
参数说明:
- tensor_model_parallel_size:要拆分单个张量的GPU数量。
- pipeline_model_parallel_size:要拆分transformer层的张量并行GPU组的数量。如果TP大小设置为4,MP为2,则模型将被拆分为2组,由4个GPU组成。
- virtual_pipeline_model_parallel_size:根据设置交织,每个流水将具有的阶段数;如果无,则不执行交织。
for i in range(pipeline_model_parallel_size):
start_rank = i * num_pipeline_model_parallel_groups
end_rank = (i + 1) * num_pipeline_model_parallel_groups
for j in range(tensor_model_parallel_size):
ranks = range(start_rank + j, end_rank, tensor_model_parallel_size)
all_data_parallel_group_ranks.append(list(ranks))
group = torch.distributed.new_group(ranks)
group_gloo = torch.distributed.new_group(ranks, backend="gloo")
if rank in ranks:
_DATA_PARALLEL_GROUP = group
_DATA_PARALLEL_GROUP_GLOO = group_gloo
_DATA_PARALLEL_GLOBAL_RANKS = ranks
if virtual_pipeline_model_parallel_size is not None:
if not pipeline_model_parallel_size > 2:
raise RuntimeError("pipeline-model-parallel size should be greater than 2 with interleaved schedule")
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
_VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK = 0
_VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE = virtual_pipeline_model_parallel_size
if pipeline_model_parallel_split_rank is not None:
global _PIPELINE_MODEL_PARALLEL_SPLIT_RANK_PIPELINE_MODEL
_PARALLEL_SPLIT_RANK = pipeline_model_parallel_split_rank
def get_virtual_pipeline_model_parallel_rank():
"""Return the virtual pipeline-parallel rank."""
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK
return _VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK
def set_virtual_pipeline_model_parallel_rank(rank):
"""Set the virtual pipeline-parallel rank."""
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK
_VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK = rank
def get_virtual_pipeline_model_parallel_world_size():
"""Return the virtual pipeline-parallel world size."""
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
return _VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
def set_virtual_pipeline_model_parallel_world_size(world_size):
"""Set the virtual pipeline-parallel world size"""
global _VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
_VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE = world_size
def forward_backward_pipelining_with_interleaving def forward_backward_pipelining_with_foldx_aiao def forward_backward_pipelining_with_foldx_fifo
三者均涉及到继续在流水中划分model到stage中,即流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的执行序,从而达到提升效率的目的。
# Pipeline model parallel size.
args.pipeline_model_parallel_size = min(
args.pipeline_model_parallel_size,
(args.world_size // args.tensor_model_parallel_size))