DataParallelism数据并行
概述
AscendSpeed提供两种数据并行方式,分别是Local Distributed Data Parallel(以下简称为LocalDDP)和torch Distributed Data Parallel(以下简称torchDDP)。
- LocalDDP:LocalDDP定义使用了连续缓存空间来存储fp32的累积梯度,如此操作是可以减少碎片空间的。此外还包含缓存清零,all-reduce梯度数据功能。
class DistributedDataParallel(DistributedDataParallelBase): """DDP with contiguous buffers options to storre and accumulate gradients. def __init__(self, module, accumulate_allreduce_grads_in_fp32, use_contiguous_buffers):参数说明:
- module:输入的模型
- accumulate_allreduce_grads_in_fp32:设置为true则使得梯度累积与all-reduce过程均使用fp32
- use_contiguous_buffers:若上述参数置为true则该参数也置为true来表示使用连续的空间存储梯度
- torchDDP:torchDDP即PyTorch框架自带的DDP功能,使用torch.nn.parallel.distributed.DistributedDataParallel进行调用,实际使用RingALLReduce实现AllReduce算法。此外torchDDP设计最核心的机制就是Gradient Bucketing。梯度分桶的做法将模型的Model的参数逆序插入每个Bucket中,当一个Bucket的参数的梯度都已经更新时,开启Allreduce,向另一个节点的对应Bucket传递梯度,这样也同时实现了异步AllReduce。
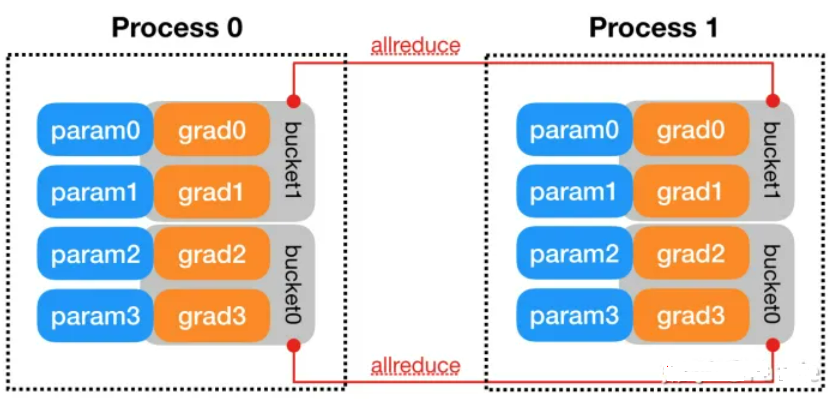
两者都存在hook机制,保证原有的训练过程不受影响:程序提供hook接口,用户可以写一个hook函数,然后钩在hook接口,即程序的主体上从而可以插入到中间执行。DDP使用hook技术把自己的逻辑插入到module的训练过程中去。parameter在反向梯度计算结束后提供了一个hook接口。DDP把Ring-Reduce的代码写成一个hook函数,插入到这里。每次parameter的反向梯度计算结束后,程序就会调用这个hook函数,从而开启Ring-Reduce流程。
功能使用
训练脚本参数配置示例,加粗部分为DDP功能配置参数示例:
python pretrain_gpt.py \ --DDP-impl local \ --num-layers 30 \ --hidden-size 4096 \ --num-attention-heads 32 \ --micro-batch-size 4 \ --global-batch-size 8 \ --seq-length 2048 \
通过修改输入参数--DDP-impl的值来确定使用何种类型的DDP,可选值“torch”和“local”.其中与localDDP相关的输入参数--no-contigous-buffers-in-local-ddp若设置了则表示在local DDP中不使用连续存储空间。
定义使用DDP时,在ascendspeed/utils.py文件下,构造定义模型
def unwrap_model(model, module_instances=(torchDDP)):
return_list = True
if not isinstance(model, list):
model = [model]
return_list = False
unwrapped_model = []
for model_module in model:
while isinstance(model_module, module_instances):
model_module = model_module.module
unwrapped_model.append(model_module)
if not return_list:
return unwrapped_model[0]
return unwrapped_model
父主题: 分布式技术