动态shape(算子二进制)调优案例
问题背景
有些模型在模型计算的过程中会存在动态shape场景,即在模型计算过程中,模型的输入和输出存在多种shape。这种情况下,由于编译时无法已知全部shape信息,每次调用算子进行计算时都需要进行编译,会增加编译开销和内存使用,降低性能。
总体思路
使用PyTorch Analyse工具的动态shape模式对于模型脚本进行分析,判断是否存在动态shape算子。
- 若不存在可进行其他内容调优。
- 若存在,请安装算子二进制包。PyTorch框架可调用算子二进制包中算子编译信息,可设置模型编译时是否优先在线编译,以此解决动态shape问题、优化模型训练性能。
瓶颈识别
使用PyTorch Analyse工具的动态shape模式对于模型脚本进行分析,生成动态shape的分析报告msft_dynamic_shape_analysis_report.csv。
- 进入分析工具所在路径。
cd Ascend-cann-toolkit安装目录/ascend-toolkit/latest/tools/ms_fmk_transplt/ - 执行分析。
./pytorch_analyse.sh -i 待分析脚本路径 -o 分析结果输出路径 -v 待分析脚本框架版本 -m dynamic_shape
表1 参数说明 参数
参数说明
取值示例
-i
--input
- 待分析脚本文件所在文件夹或三方库套件源码所在文件夹路径。
- 必选。
/home/xxx/analysis
-o
--output
- 分析结果文件输出路径。
- 会在该路径下生成xxxx_analysis文件夹。
- 必选。
/home/xxx/analysis_output
-v
--version
- 待分析脚本或三方库套件源码的PyTorch版本。目前支持1.11.0、2.0.1、2.1.0。
- 必选。
- 1.11.0
- 2.0.1
- 2.1.0
-m
--mode
- 分析的模式。目前支持torch_apis(算子支持情况分析)、third_party(三方库套件分析)、affinity_apis(亲和API分析)和dynamic_shape(动态shape分析)模式。
- 可选。
- torch_apis(默认)
- third_party
- affinity_apis
- dynamic_shape
-env
--env-path
- 分析时需要增加的PYTHONPATH环境变量路径,仅安装jedi后该参数才生效。
- 可选。
/home/xxx/transformers/src /home/xxx/transformers/utils
多个文件路径使用空格隔开。
-api
--api-files
- 三方库不支持API的分析结果文件。
- 可选。
/home/xxx/mmcv_analysis/full_unsupported_results.csv /home/xxx/transformers_analysis/full_unsupported_results.csv
多个文件路径使用空格隔开。
-h
--help
显示帮助信息。
-
- 完成分析后,在分析结果输出路径下会生成一个完整的模型脚本文件夹,其中模型脚本代码都做了自动修改。在分析结果输出路径下,修改训练脚本文件中读取训练数据集的for循环,手动开启动态shape检测,请参考下方示例进行修改。
- 修改前:
for i, (ings, targets, paths, _) in pbar:
- 修改如下加粗字体信息:
for i, (ings, targets, paths, _) in DETECTOR.start(pbar):
- 修改前:
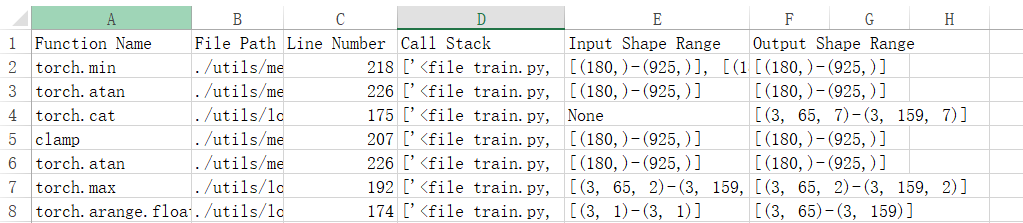
- 在分析结果输出路径下,拉起修改过的训练脚本,运行一个epoch即可。完成后会在路径下生成动态shape的分析报告msft_dynamic_shape_analysis_report.csv。其中存储了函数名称、调用栈、所在文件、文件行号、输入和输出的shape范围,如下图样例所示。图1 样例动态shape分析报告
性能调优
在代码中使能算子二进制即可完成性能调优。
- 打开训练脚本。
vi train.py
- 在主函数中添加使能算子二进制的代码。
if __name__ == '__main__': torch_npu.npu.set_compile_mode(jit_compile=False) main() - 拉起训练。对比使能算子二进制前后的step训练耗时,发现性能数据获得提升即说明调优成功。如下图所示,未开启算子二进制时一个step训练总耗时(mTime)约为1.4s,开启后一个step训练总耗时(mTime)约为1.2s。图2 未开启算子二进制
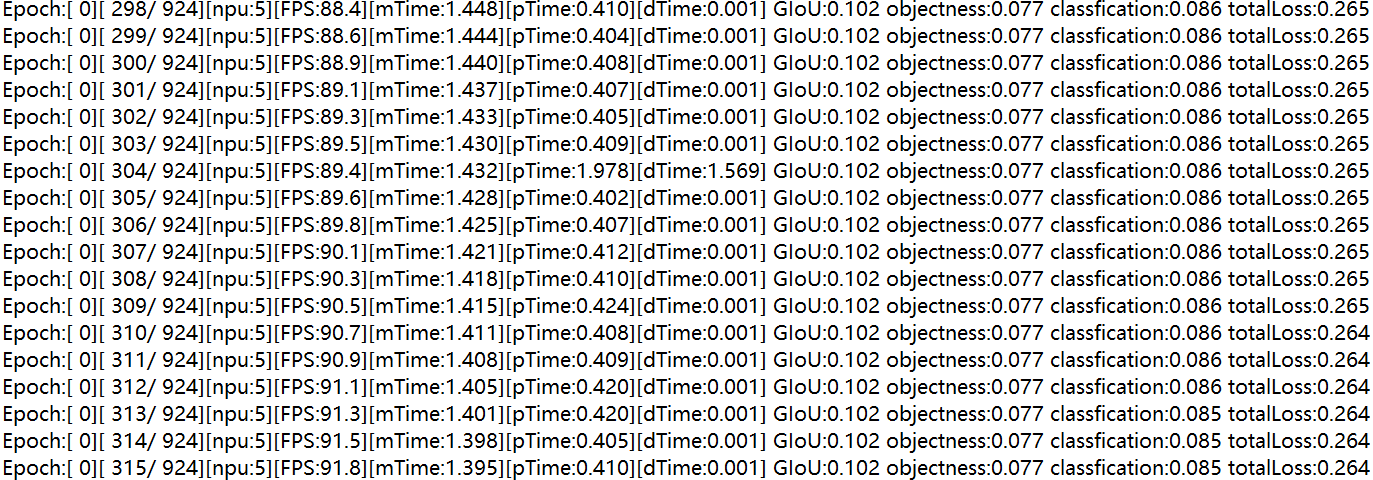 图3 开启算子二进制
图3 开启算子二进制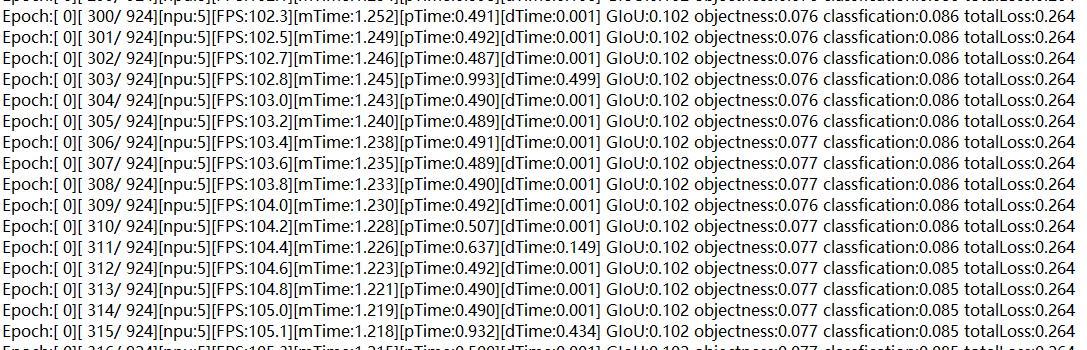
父主题: 初级调优