自增操作精度问题定位案例
总体思路
在PyTorch模型迁移与训练过程中出现的精度问题,可以从以下两方面依次进行定位。
- 检测整网训练过程中是否存在溢出问题。如果存在,则需要确定具体发生溢出的API,然后通过ACL检测针对该API做算子级输入输出dump,分析发生溢出的算子。
- 检测是否存在单算子与标杆数据(GPU/CPU)存在精度差异,进行数据dump,分析dump数据比对结果,从而定位出单算子的适配与实现问题。
环境准备

溢出定位
- 进入模型脚本所在目录并打开。
cd src vi main.py
- 在训练脚本中导入精度工具包,使能精度工具溢出定位。
from ptdbg_ascend import register_hook, overflow_check, seed_all, set_dump_path, set_dump_switch, acc_cmp_dump
- 为了稳定复现溢出问题,在训练脚本主函数内添加以下代码,固定网络中的随机数。
def main(): seed_all() ... - 在模型定义后,训练循环开始前,添加溢出检测函数,其中overflow_check为使能溢出检测开关,overflow_nums为检测到溢出抛出异常的阈值次数,超过这个阈值就会退出训练。
def main(): ... model = create_model(opt.arch, opt.heads, opt.head_conv) ... set_dump_path("./data/dump", dump_tag='npu_overflow') # 设置dump路径,最终数据保存在此路径下 register_hook(model, overflow_check, overflow_nums=1) # 使能溢出检测 ... for epoch in range(start_epoch + 1, opt.num_epochs + 1): ... - 执行训练脚本。
bash ./test/train_full_1p.sh --data_path=数据集路径
- 查看.pkl日志文件是否有溢出提示。日志截图样例如下所示。训练结束后,发现日志并无溢出信息,因此判定当前精度问题不是由溢出导致。图1 日志信息
Dump数据比对
- 在模型定义后,训练循环开始前,添加dump路径、hook函数和dump开关。acc_cmp_dump为数据dump比对开关。
def main(): ... model = create_model(opt.arch, opt.heads, opt.head_conv) optimizer = torch.optim.Adam(model.parameters(), opt.lr) ... set_dump_path("./dump_data_new/npu") # 设置dump路径,最终数据保存在此路径下 register_hook(model, acc_cmp_dump) # 添加hook函数和数据比对dump开关 for epoch in range(start_epoch + 1, opt.num_epochs + 1): ... - 设置dump开关。用户根据实际需要的范围,在代码中设置dump开始位置set_dump_switch("ON")和结束位置set_dump_switch("OFF"),样例代码中开关设置在循环的开始与结束。
set_dump_switch("ON") for epoch in range(start_epoch + 1, opt.num_epochs + 1): ... logger.write('\n') set_dump_switch("OFF") - 执行训练脚本。分别将模型在NPU和GPU/CPU上执行训练,注意两次执行训练前,要通过set_dump_path指定不同的输出目录,例如在CPU上可以将输出目录修改为./dump_data_new/cpu。
#NPU训练命令 bash ./test/train_full_1p.sh --data_path=数据集路径
模型训练结束后,数据会落盘到输出目录。样例输出目录如下图。
图2 Dump输出数据目录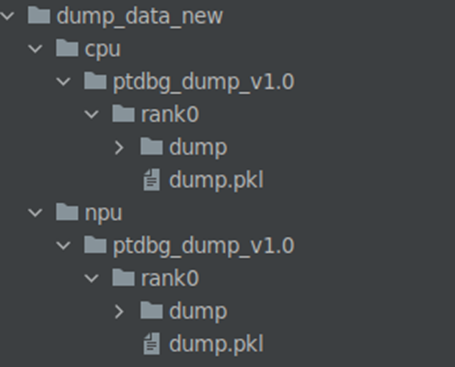
数据比对
- 参考compare.py脚本示例创建并配置精度比对脚本,样例参考如下。其中dump文件夹和pkl文件请用户根据dump时设置的实际目录修改。
from ptdbg_ascend import compare dump_result_param={ "npu_pkl_path": "./npu_dump/ptdbg_dump_v4.0/step0/rank0/dump.pkl", "bench_pkl_path": "./gpu_dump/ptdbg_dump_v4.0/step0/rank0/dump.pkl", "npu_dump_data_dir": "./npu_dump/ptdbg_dump_v4.0/step0/rank0/dump", "bench_dump_data_dir": "./gpu_dump/ptdbg_dump_v4.0/step0/rank0/dump", "is_print_compare_log": True } compare(dump_result_param, "./output") - 运行数据比对脚本。
python3 compare.py
比对完成后会在指定的输出目录中生成对比结果文件“compare_result_timestamp.csv”,示例文件如下所示。
图3 示例文件 图4 比对结果展示
图4 比对结果展示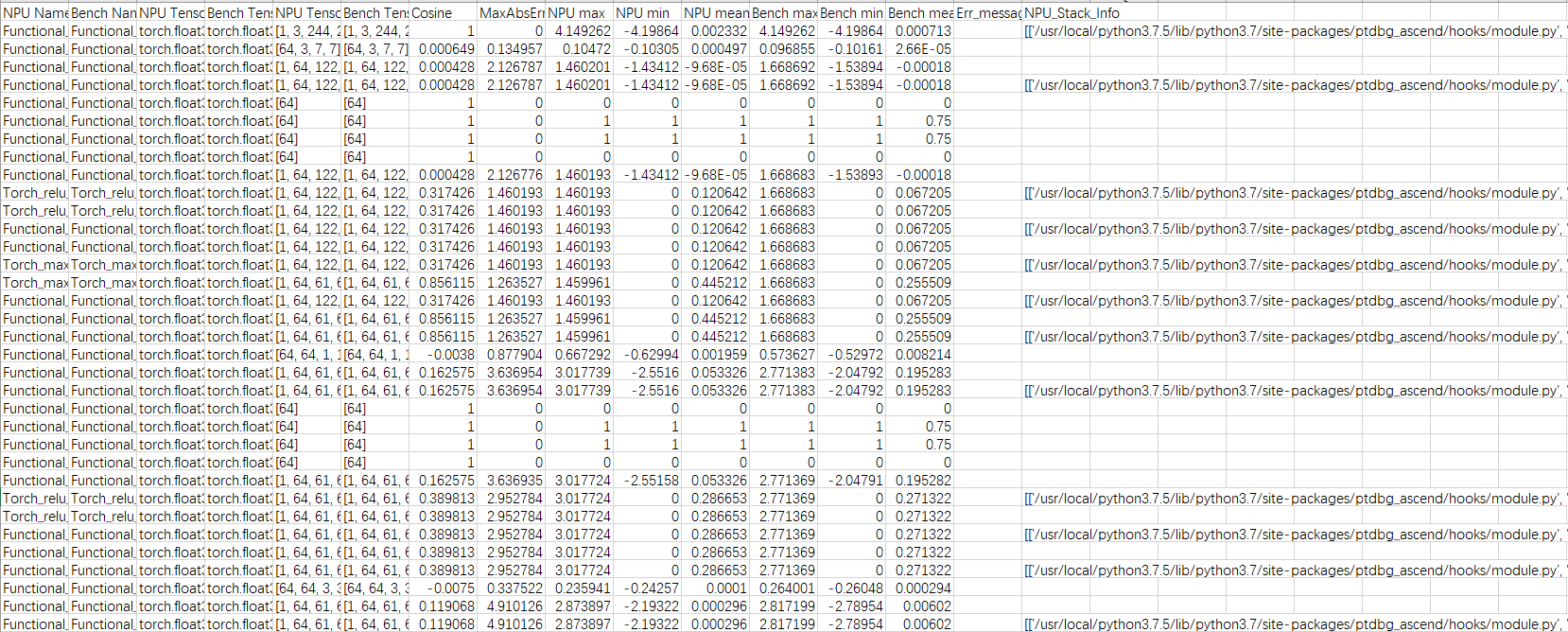
分析比对结果
- 分析dump数据精度比对结果,按余弦相似度(Cosine)小于0.99,最大绝对值误差(MaxAbsError)大于0.001进行筛选,筛选后csv结果如下所示:图5 筛选结果

可以看到第一个存在问题的是iadd API的input_0,其余弦相似度小于0.99并且最大绝对值误差远大于0.001。
- 通过工具dump的stack模式将网络中的问题API的堆栈信息dump下来。修改set_dump_switch所在行代码,使能stack模式dump。
set_dump_switch("ON", mode="stack", scope=['Tensor___iadd___forward']) - 解析问题API的堆栈信息,通过堆栈信息回溯到具体的问题代码行如下。
def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: residual = self.downsample(x) out += residual # 问题代码行 out = self.relu(out)如果只分析iadd的input_0比对结果,容易得出iadd的input有问题的判断,但其实这个判断是错误的。通过代码可知,iadd是一个自增操作。由于数据dump利用PyTorch hook机制,在执行后才会将输入和输出缓存,但是自增操作会将输出结果覆盖到输入,所以表格中呈现的input_0实际为iadd的output。观察下图中的iadd的input_0和output,发现这两行完全一致,可以验证这个结论。图6 dump数据表格结果
因此根据以上结论,可以定位到是iadd的输出存在问题,而不是输入。
- iadd的输出存在精度问题的原因可能有如下两点:
- iadd的真实输入存在精度问题。
- iadd的计算精度存在问题。
回归代码,排查iadd的真实输入,发现iadd的真实输入是batchnorm的输出。def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) # out为batchnorm的输出,代入到下方成为了自增操作的输入 if self.downsample is not None: residual = self.downsample(x) out += residual # 问题代码行 out = self.relu(out)检视batchnorm算子的比对结果数据,如下图,可以确定batchnorm输出(即iadd真实输入)的余弦相似值为1,最大绝对值误差接近0,无精度问题。
图7 batchnorm算子比对结果
因此可以得出结论:iadd算子的计算精度存在问题,导致iadd输出精度异常。可以联系华为工程师解决此问题,可进入昇腾开源社区使用issue进行沟通。
父主题: 精度调测案例