MLP层融合优化
基本原理
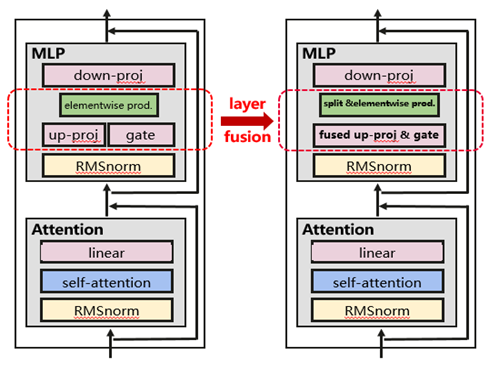
基于LLaMA模型结构进行分布式层面的算子融合,通过对MLP中up-proj层和gate层融合,可以在分布式训练场景下获得以下收益:
- 通信:前向和反向各减少一次allreduce;
- 计算:前向将2次矩阵乘融合成1次大矩阵乘;反向将4次矩阵乘融合成2次大矩阵乘,减少算子下发。
图1 MLP层融合示意
使用场景
LLaMA系列结构通用,当前在Atlas A2 训练系列产品上验证: LLaMA-16B性能提升3.3%,LLaMA-32B性能提升4.0%,LLaMA2-7B上提升9%。
操作步骤
使用AscendSpeed,添加 --mlp-layer-fusion标志。
父主题: 初级调优