AOE调优(MatMul算子)
基本原理
AOE(Ascend Optimization Engine)是一款自动调优工具,通过生成调优策略、编译和在运行环境上验证的闭环反馈机制,不断迭代出更优的调优策略,最终得到最佳的调优策略,从而可以更充分利用硬件资源,不断提升网络的性能,达到最优的效果。
使用场景
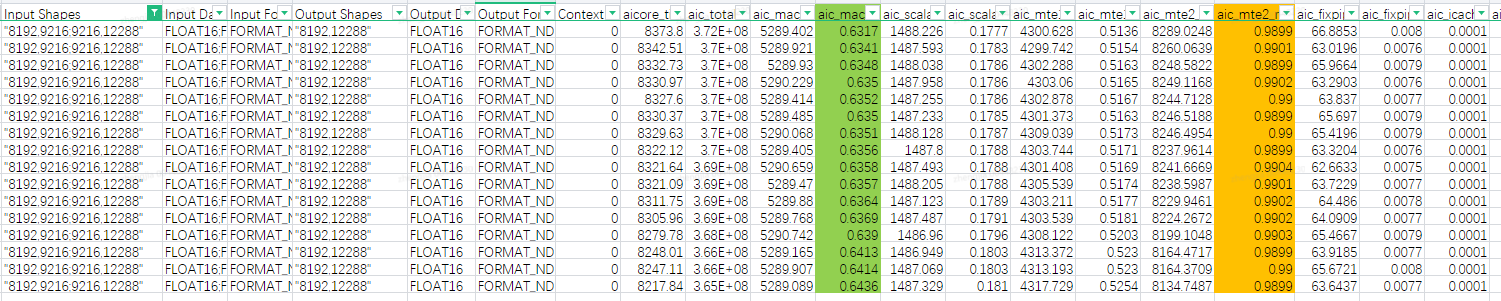
如图1,通过summary表格能看到每个shape的PMU数据。在例子图中,可以看到基本都是MTE2bound,mte2-ratio达到99%以上,mac-ratio则都在63%左右。针对mac-ratio未达到70%以上的case,则认为存在优化的空间,可以使用AOE工具进行调优;请联系华为工程师进行优化。
操作步骤
|
当前调优支持 |
FP16 |
BF16 |
FP32 |
INT8(全量化) |
|---|---|---|---|---|
|
Tensorflow(.pb) |
支持 |
支持 |
支持 |
待测试 |
|
Pytorch(.txt) |
支持 |
支持 |
支持 |
待测试 |
|
MindSpore(.air/proto*.txt) |
待测试 |
待测试 |
待测试 |
待测试 |
- 生成用户输入文件。
- pb离线模型:
- 当前msopst框架中存在生成MatMul算子的pb模型的模板,可以借以调用。
- 构建msopst所需的xlsx表格,以所需算子shape构建(参考gen_case目录下的MatMul网络用例如./aicore_test/gen_case/cube_daily_case/milan_case/matmul_network_case.xlsx)。
- 调用op_template生成pb模型,调用./aicore_test/msopst/op_template/fusion_mm_gen_pb_model.py,通过msopst框架生成对应pb模型,指令可参考:
bash run.sh --case_file=./aicore_test/msopst/msopst_case.xlsx --sheet_name=matmul_v2 --fusion_file=op_template/fusion_mm_gen_pb_model.py --case_type=stc --host_process_count=1 --testcase_id=case1
- 输出的pb模型保存在./aicore_test/msopst/tmp_wks/process_MainProcess_host_done_device_done/op_models/中。
- torch模型:
原则上需要在模型开头添加以下内容以生成dump的txt文件。
torch_npu.npu.set_aoe('./dump_path')- 参考安装PyTorch获取torch安装对应torch环境。
- 通过torch脚本dump所需txt模型。
- 使用source命令配置Ascend环境变量。
source /usr/local/Ascend/latest/bin/setenv.bash
- 通过aoe接口在指定路径下生成所需模型文件。
torch_npu.npu.set_aoe('./dump_path') -
MatMul算子torch模型生成脚本可参考:
python import torch import torch_npu import numpy as np torch_npu.npu.set_compile_mode(jit_compile=True) # 当前aoe仅在静态时生成dump图 torch_npu.npu.set_aoe('./dump_path') def case1(): input_shape_0 = (1024,10240) input_shape_1 = (5120,10240) fmap = torch.from_numpy(np.ones(input_shape_0).astype(np.float16)) fmap_npu = fmap.npu() weight = torch.from_numpy(np.ones(input_shape_1).astype(np.float16)) weight_npu = weight.npu() attn_output_npu = torch.mm(fmap_npu, weight_npu.t()) print("successed!") case1() - 批量生成MatMul算子dump图脚本可参考:
import torch import torch_npu import numpy as np torch_npu.npu.set_compile_mode(jit_compile=True) torch_npu.npu.set_aoe('./1119ms') def case1(): input_shape_0 = (2048,12288) input_shape_1 = (12288,6144) fmap = torch.from_numpy(np.ones(input_shape_0)) fmap = fmap.to(torch.float16) fmap_npu = fmap.npu() weight = torch.from_numpy(np.ones(input_shape_1)) weight = weight.to(torch.float16) weight_npu = weight.npu() attn_output_npu = torch.mm(fmap_npu, weight_npu) print("successed!") def case2(): input_shape_0 = (2048,12288) input_shape_1 = (1536,12288) fmap = torch.from_numpy(np.ones(input_shape_0)) fmap = fmap.to(torch.float16) fmap_npu = fmap.npu() weight = torch.from_numpy(np.ones(input_shape_1)) weight = weight.to(torch.float16) weight_npu = weight.npu() attn_output_npu = torch.mm(fmap_npu, weight_npu.t()) print("successed!") def case3(): input_shape_0 = (2048,12288) input_shape_1 = (2048,6144) fmap = torch.from_numpy(np.ones(input_shape_0)) fmap = fmap.to(torch.float16) fmap_npu = fmap.npu() weight = torch.from_numpy(np.ones(input_shape_1)) weight = weight.to(torch.float16) weight_npu = weight.npu() attn_output_npu = torch.mm(fmap_npu.t(), weight_npu) print("successed!") case1() case2() case3() - 在配置路径的文件夹中生成模型文件则代表生成成功。
-- dump_path ---- ge_proto_00000_MatMul1.txt ---- ge_proto_00001_MatMul3.txt ---- ge_proto_00002_MatMul5.txt ---- ge_proto_00003_MatMul7.txt
- 使用source命令配置Ascend环境变量。
- pb离线模型:
- 配置AOE环境。
- 参考《AOE工具使用指南》中的“PyTorch训练场景下调优>环境准备”章节完成CANN和AOE环境配置。以下步骤默认已配置CANN软件基础环境变量及Python环境变量,请在调优前提前配置。
- 使用source命令配置环境变量。
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash
- 开启调优模式。
export REPEAT_TUNE=True
- 配置生成知识库存放路径。
export TUNE_BANK_PATH=./matmul_bank
- 执行调优。
- pb模型,fp16进fp16出用例:
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash export REPEAT_TUNE=True # 执行调优流程 rm -rf ./matmul_bank mkdir ./matmul_bank export TUNE_BANK_PATH=./matmul_bank # 配置知识库输出路径 aoe -m case10_model.pb -f 3 -j 2
- pb模型,fp32进fp32出(或bf16进bf16出)用例:
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash export REPEAT_TUNE=True # 执行调优流程 rm -rf ./matmul_bank mkdir ./matmul_bank export TUNE_BANK_PATH=./matmul_bank # 配置知识库输出路径 aoe --precision_mode=must_keep_origin_dtype -m case10_model.pb -f 3 -j 2
- torch模型,fp16进fp16出用例(调优文件夹中存放ge_proto_xxxx.txt,可批量存放):
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash export REPEAT_TUNE=True # 执行调优流程 rm -rf ./matmul_bank mkdir ./matmul_bank export TUNE_BANK_PATH=./matmul_bank # 配置知识库输出路径 aoe --job_type=2 --model_path=./dump_path/
- torch模型,fp32进fp32出(或bf16进bf16出)用例(调优文件夹中存放ge_proto_xxxx.txt,可批量存放):
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash export REPEAT_TUNE=True # 执行调优流程 rm -rf ./matmul_bank mkdir ./matmul_bank export TUNE_BANK_PATH=./matmul_bank # 配置知识库输出路径 aoe --job_type=2 --precision_mode=must_keep_origin_dtype --model_path=./dump_path/
- MindSpore模型:
- 由于当前cache_tiling调优仅支持离线模型调优,先前MindSpore适配的在线调优接口不可用,因此可尝试dump出离线模型进行调优。
- dump方式:增加图模式环境变量,dump出ge_proto_xxxx.txt文件:
export DUMP_GE_GRAPH=1 export DUMP_GRAPH_LEVEL=4
- 调优脚本如下:
source /usr/local/Ascend/latest/bin/setenv.bash source /usr/local/Ascend/latest/tools/aoe/bin/setenv.bash export REPEAT_TUNE=True # 执行调优流程 rm -rf ./matmul_bank mkdir ./matmul_bank export TUNE_BANK_PATH=./matmul_bank #配置知识库输出路径 aoe --job_type=2 --precision_mode=must_keep_origin_dtype --model_path=./dump_path/ #torch txt bf16 fp32
- pb模型,fp16进fp16出用例:
- 生成知识库样式参考。
在配置知识库输出路径下,找到./AscendXX/AscendXX_24_AiCore_MatMulV2_runtime_kb.json中存在对应知识库(参考)则说明成功。
{"id":1550289820,"info_dict":{"a_dtype":1,"a_format":2,"aub_double_num":1.0,"b_dtype":1,"b_format":2,"batch_a1":1,"batch_a2":1,"batch_a3":1,"batch_a4":1,"batch_b1":1,"batch_b2":1,"batch_b3":1,"batch_b4":1,"bias_flag":false,"bub_double_num":1.0,"fused_double_operand_num":0.0,"k":8000,"k_align_flag":true,"l1_fused_num":0.0,"m":4096,"m_align_flag":true,"n":10240,"n_align_flag":true,"out_dtype":1,"out_format":2,"reserved_bool":false,"reserved_params1":2,"reserved_params2":0,"reserved_params3":0,"reserved_params4":0,"reserved_params5":0,"reserved_params6":0,"trans_a_flag":false,"trans_b_flag":false},"knowledge":{"batch_aub":1,"batch_bub":1,"batch_cub":1,"batch_dim":1,"batch_l0":1,"db_al1":2,"db_aub":2,"db_bl1":2,"db_bub":2,"db_cub":2,"db_l0a":2,"db_l0b":2,"db_l0c":1,"k_al1":16,"k_aub":8192,"k_bl1":8,"k_bub":9,"k_dim":1,"k_l0":4,"m_al1":1,"m_aub":12,"m_dim":8,"m_l0":16,"n_bl1":1,"n_bub":10240,"n_cub":1,"n_dim":3,"n_l0":8},"op":"MatMulV2","version":0} - 验证调优生成的知识库结果。
- 生成知识库后,将生成知识库复制到CANN仓路径中重新验证性能,CANN仓路径参考:
cd /usr/local/Ascend/CANN-7.x/opp/built-in/data/op/
- 找到对应版本,路径为:
./AscendXX/unified_bank/AscendXX_24_AiCore_MatMulV2_runtime_kb.json
- 将AOE生成的知识库复制到文件中,重新批跑获取性能,筛选出使性能优化的对应用例知识库。
- 生成知识库后,将生成知识库复制到CANN仓路径中重新验证性能,CANN仓路径参考:
父主题: 初级调优