分析算子耗时
NPU的算子耗时统计可直接从profiling数据的device_xx/summary中获取,profiling目录结构如下:
图1 profiling目录结构
Op_summary在PROF_XXX/device_xx/summary下,结构如下:
图2 summary目录结构
分析算子耗时需要重点关注2个文件,一个是算子分类汇总文件op_statistic_xx.csv,另一个是算子详细数据文件op_summary_xx.csv。
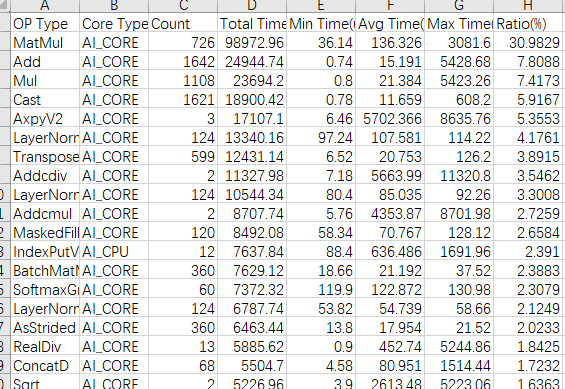
- op_statistic_xx.csv按算子粒度进行分类汇总,通过观察总耗时(Total Time)可以快速识别到耗时较高的算子。
图3 查看op_statistic_xx.csv
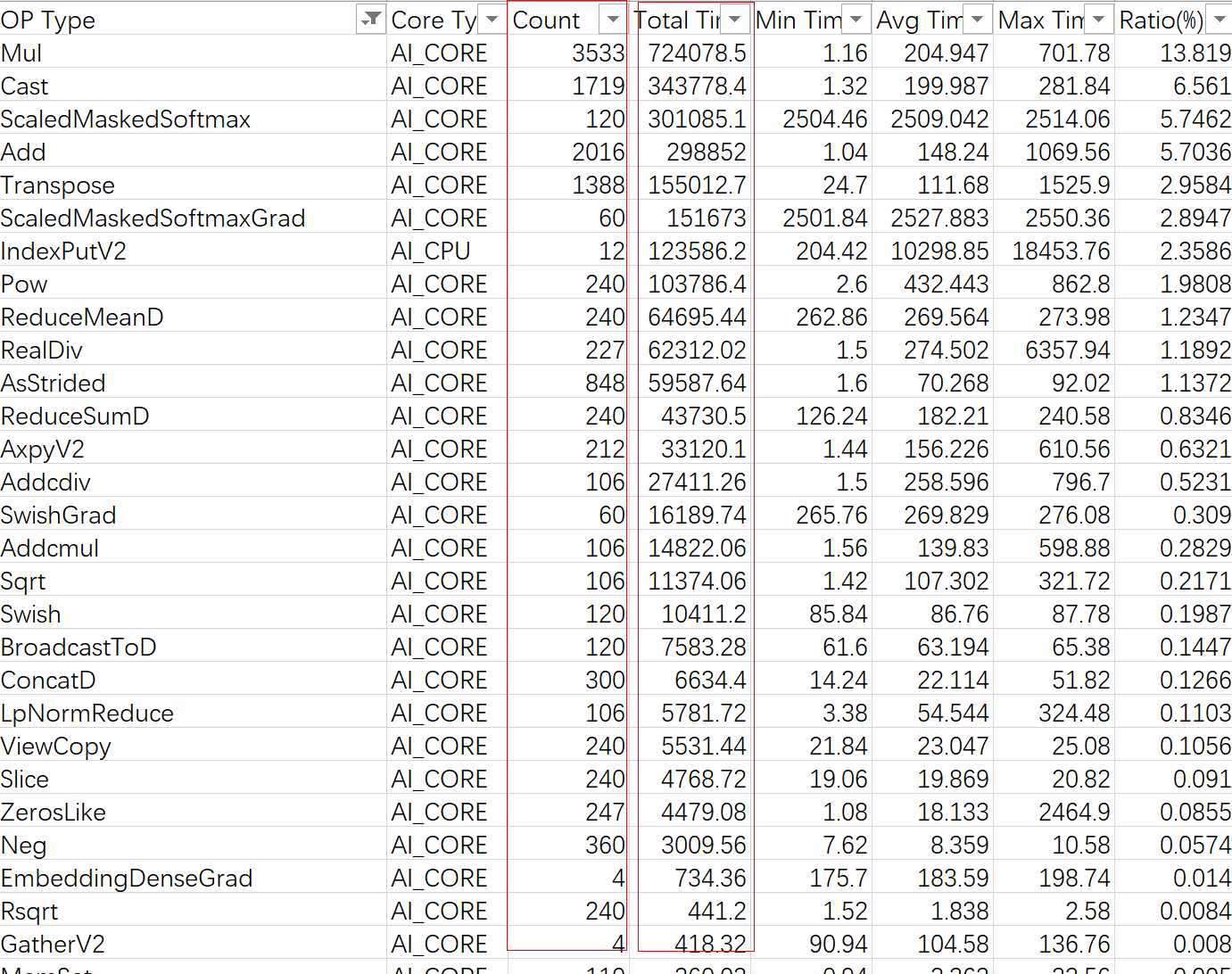
- op_summary_xx.csv文件提供了更详细的算子数据,包含算子的shape,dtype,计算耗时和流水占比等信息,可用作算子详细性能分析。
图4 查看op_summary_xx.csv

- Cube/Vector算子耗时统计:
在op_statistic_xx.csv中可以分类统计Cube和Vector算子耗时,Core Type去除HCCL, 根据Op Type,Cube时间选择BatchMatMul和MatMul,统计的总时间即为Cube算子总耗时,剩余的时间为Vector算子总耗时。
- Cube算子耗时和个数统计。
图5 汇总Cube算子耗时

- Vector算子耗时和个数统计。
图6 汇总Vector算子耗时
父主题: 算子计算性能分析与优化