Pipeline并行Bubble耗时占比分析
分析内容
one forward one backward(1F1B)策略下:
图1 pipeline并行bubble占比分析

相关耗时计算公式:
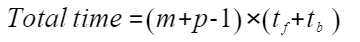 :端到端总耗时。
:端到端总耗时。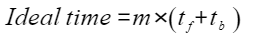 :理想耗时。
:理想耗时。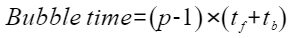 :Bubble耗时。
:Bubble耗时。
参数解释:
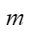 :number of mini batches.
:number of mini batches.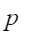 :number of pipeline stages.
:number of pipeline stages.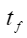 :forward step time.
:forward step time.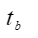 :backward step time.
:backward step time.
Bubble占比=Bubble time/Total time = (p-1)/(m+p-1),其中m = global batch size/data parallel/micro batch size。
优化手段
部署时需要减少Bubble占比,即减少p或者增加m的比例。
- 减少p:pipeline并行能减少每卡部署的模型层数,减少片上内存占用。减少p,则每卡部署的模型层数增加,受片上内存容量限制。
- 增加m:
- 增加global batch size:增加global batch size会增加每个step训练的耗时,选择合适的global batch size,可以方便观察和checkpoint,不能无限制增加global batch size。
- 减少data parallel个数:data parallel是最有效的提升网络的吞吐性能的策略,减少data parallel个数可以增加m,但不利于性能提升。
- 减少micro batch size:减少micro batch size同样可以增加m,但需要注意过小的micro batch size不利于cube、vector算力利用。
在profiling数据中查看Bubble耗时
网络配置及部署参数如表1所示(举例):
|
Vocab Size(v) |
Seq Length(s) |
Attn heads(ah) |
Hidden size(h) |
Layers(n) |
DP(d) |
TP(t) |
PP(p) |
卡数 |
micro batch size(b) |
Global batch size(B) |
|---|---|---|---|---|---|---|---|---|---|---|
|
51200 |
1024 |
96 |
12288 |
64 |
1 |
8 |
8 |
64 |
4 |
96 |
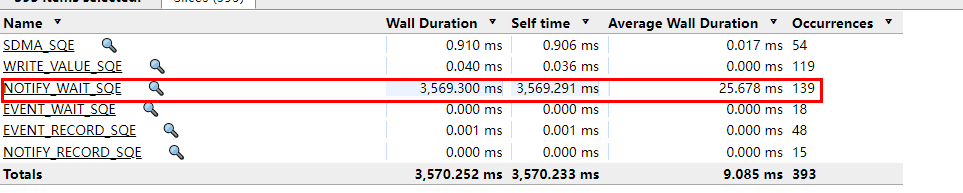
如下图所示,在1F1B策略下,NOTIFY_WAIT_SQE的红色标记处耗时,属于理论上的Bubble耗时。
图2 Bubble耗时

图3 NOTIFY_WAIT_SQE耗时记录
父主题: 通信性能分析与优化