通信耗时建模
Tensor parallel通信耗时
图1 Tensor parallel通信耗时
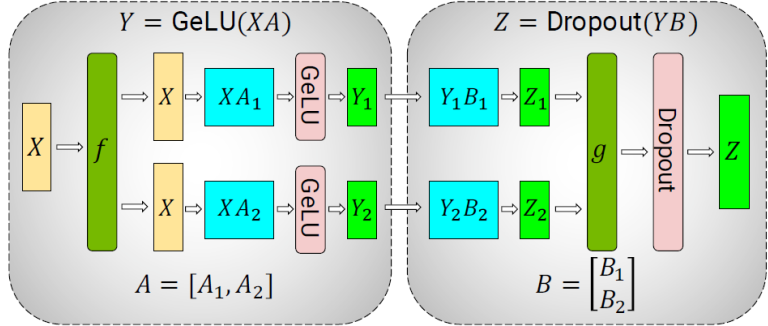
- 在完全重计算的情况下,Self-Attention和MLP各有3次All-Reduce通信。
- 在无重计算的情况下,Self-Attention和MLP各有2次All-Reduce通信。
- 消息的大小为:2 Bytes*micro_batch_size*sequence_length*hidden_size。
- All-Reduce由Reduce-Scatter和All-Gather组合实现。
- TP耗时时间理论评估(以有完全重计算的场景为例,采用All-Reduce集合通信):Ttp= 2Bytes*b*s*h/ (t*bwintra)*α*2* (3+3)*n/p*B/(b*d)

- bwintra为单条SDMA单向有效带宽;
- α是通信效率因子。
Data parallel通信耗时
Data Parallel采用All-Reduce集合通信,通信可分为SDMA通信和RDMA通信两部分:
- SDMA通信:发生在同一Server内部的通信。
- 单机8卡场景中,当TP=4,DP=2时,SDMA通信发生在同一Server内2个DP实例对应的2卡间。Time_dp_sdma = 2*Np/2/bwintra*α*2 ,其中Np≈(h*h/t*4+h*h*4/t*2)*n/p+h*v/t+s*h/t。
- 单机8卡场景中,当TP=8,DP=1时,不存在SDMA通信。
- RDMA通信:跨Server的通信。
- 跨Server时,根据Server数选择Ring或Halving-Doubling算法。
- 按照DDP分桶配置对与模型参数量相等的梯度数据进行通信。
通信算法与并行度和Server数量相关。
Pipeline parallel耗时
耗时计算公式:Tpp(p)=α* (2Bytes/(b*d) + 2(p-1)) * (msg_size/bwinter + msg_size/bwintra )
- msg_size=2Bytes*b*s*h/t。
- bwintra为单条SDMA单向有效带宽。
- bwinter为单条RDMA单向有效带宽。
父主题: 通信性能分析与优化