调度性能采集与分析
- 参见Ascend PyTorch Profiler完成数据采集,并使用Chrome浏览器的Tracing页面(chrome://tracing/)打开trace_view.json文件。
- 在Tracing页面上选定需要分析的一个step端到端的时间,计算调度时间=端到端时间-计算和通信时间,如果计算和通信间有overlap则需要单独分析。
此处以示例模型的单step为例,进行调度耗时的分析,由于大模型的timeline数据较冗余,故在分析时将整体的一个step切分为前8段前反向计算结果、中16段前反向计算结果、后8段前反向计算结果三段,进行分段式分析。
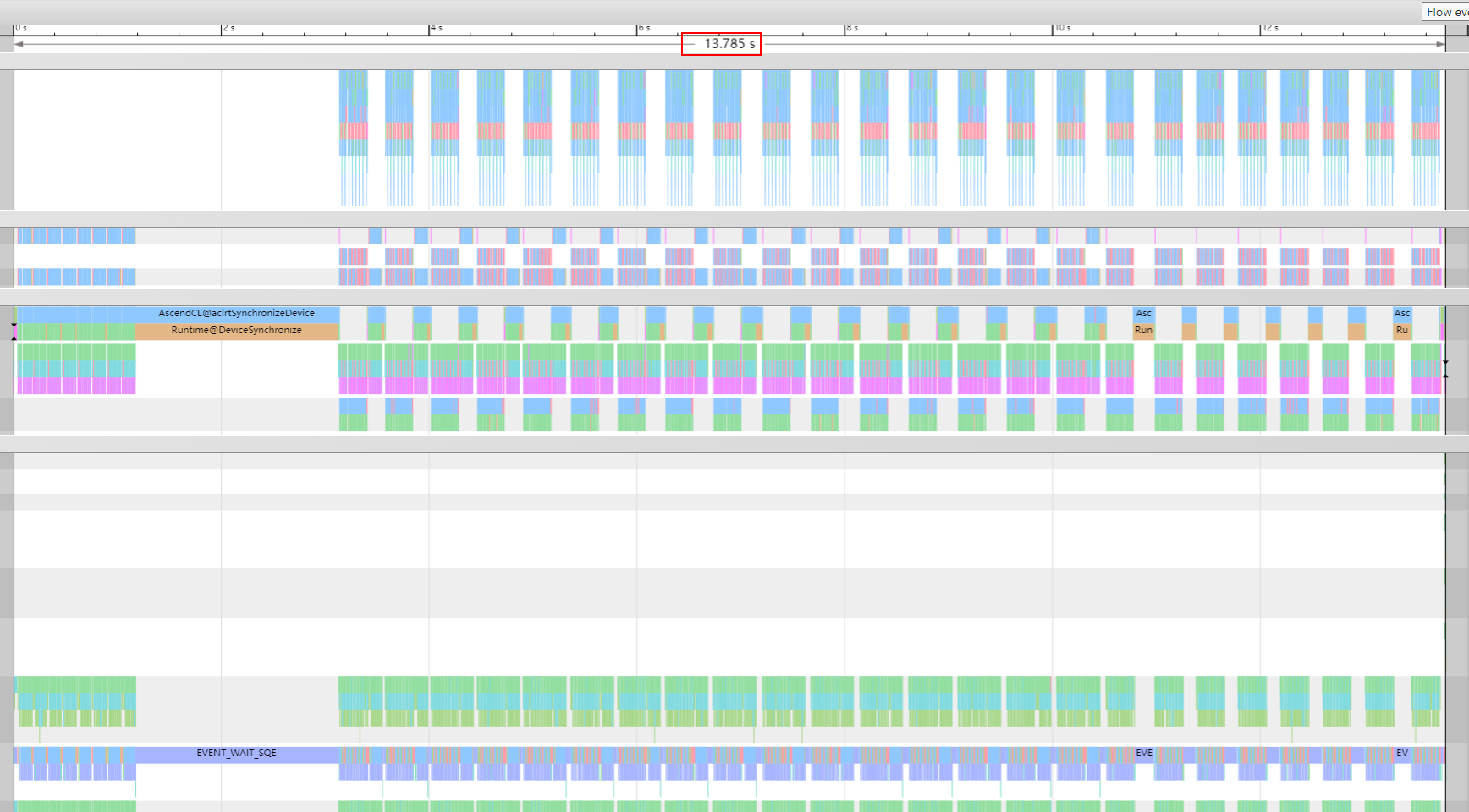
- 根据profiling数据查看step端到端时间为13.78s。
图1 查看step端到端时间
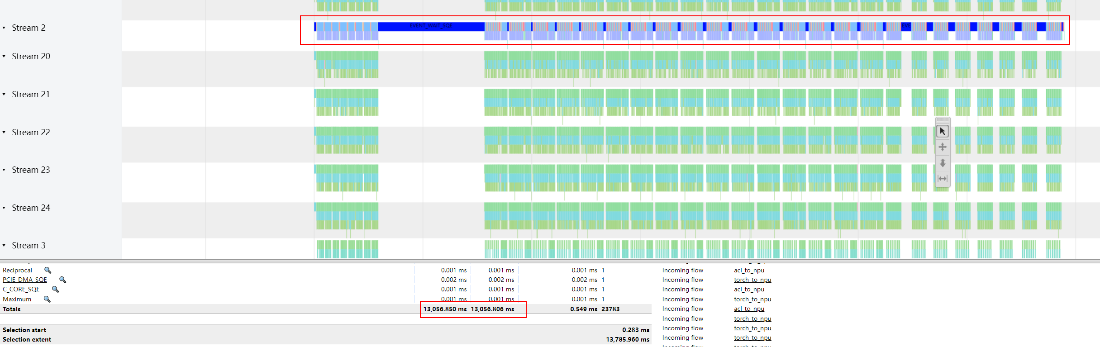
- 计算流上的任务耗时13.06s。
图2 查看计算流耗时
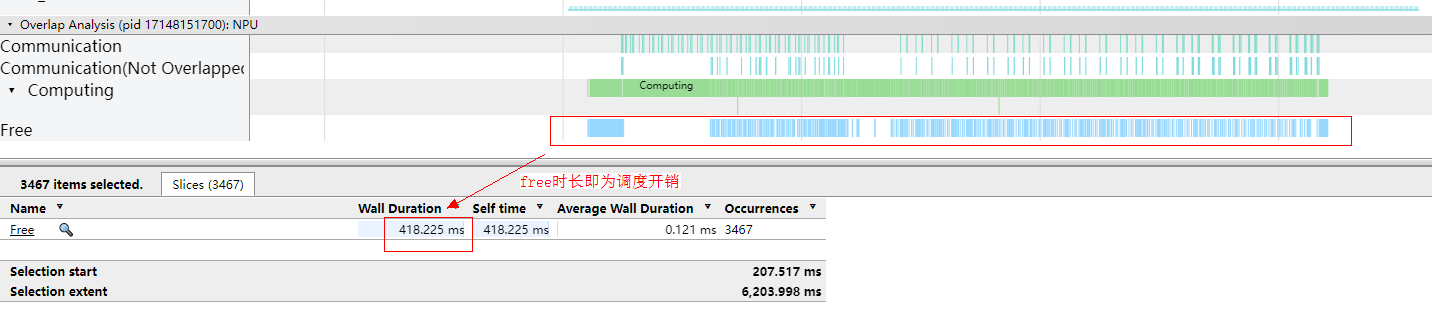
- profiling中调度耗时的部分为下图中的Free Time所示。
图3 查看调度耗时
- 根据profiling数据查看step端到端时间为13.78s。
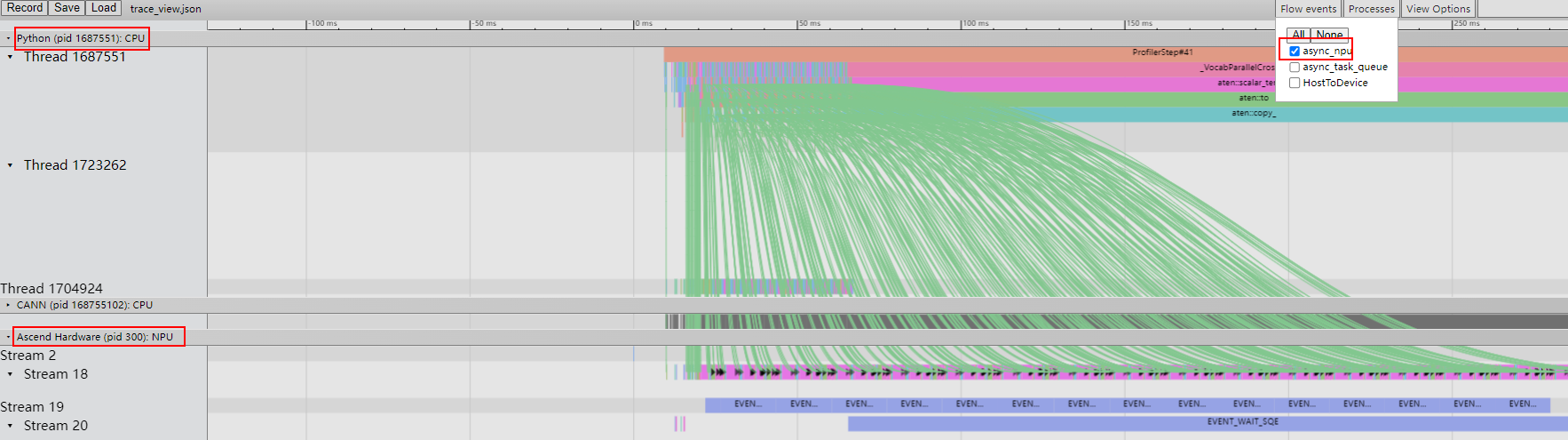
- 观察Host与Device侧调度产生的空白间隙。
- 观察Device侧流水上的调度间隙,寻找对应时段的事件。
图4 查看调度间隙

- 观察Host下发与Device执行的调度曲线,如果多数调度曲线垂直,则说明模型存在下发瓶颈,需要联系华为工程师进行处理。下图为正常下发示例。
图5 正常调度展示

host侧profiling统计本身也会引入较大开销,打开host profiling获取到的端到端时延比实际时延大很多,因此在统计调度时延时关闭host profiling,只打开device侧profiling,这样才能获取准确的调度开销。
- 观察Device侧流水上的调度间隙,寻找对应时段的事件。
父主题: 调度性能优化