大模型加速框架介绍
Transformer推理加速库(Ascend Transformer Boost,以下简称加速库),该加速库用于Transformer的神经网络推理。加速库中包含了各种Transformer类模型的高度优化模块,如Encoder和Decoder。
加速库底层算子主要由Ascend C编写,基于Ascend底层高性能算子库/TBE算子库实现Transformer类模型的快速推理。
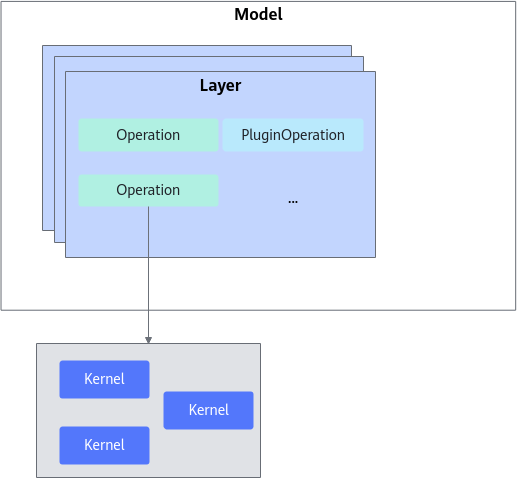
加速库主要层级划分如图1所示,模型的迁移和应用主要基于以下几层展开。
- Operation
Operation可以分为两类,加速库本身提供的基础Operation和用户根据自己需求使用Ascend C开发的PluginOperation。
Operation 为Transformer加速库成图的最小单元,是可识别的Transformer类模型的最小单元模块,通常对应Pytorch的Module或者Function,如 ROPE、Self-Attention、FFN 等。Operation通常也是基于不同底层算子(Kernel)的组合,如FFN是matmul/add/activation等算子的组合,是模型之间可复用的模块。
底层 Kernel 算子由公共算子库提供,对用户不可见。模型适配不涉及 Kernel 的开发,如果存在不支持的Operation,用户可以给加速库提需求或者用户使用Ascend C开发自定义的PluginOperation。
- Layer
Layer层为Operation的组合单元,定义为不同模型的通用大颗粒结构,如Transformer_Block/LM_Head层等。
- Model
将2中定义的Layer进行拼接,组成完整的推理流程即为Model层。Model层通常包含了完整的模型推理过程,PyTorch等框架可以直接在对应Python代码侧调用已实现的Model类,实现模型的推理调用。