调优流程
数据采集和性能分析
本样例采用E2E profiling方式进行数据采集。E2E profiling可以端到端地分析模型性能瓶颈所在,详见概述。进行profiling的详细样例步骤如下:
- 在脚本原代码训练模型部分,添加获取性能数据文件的代码。因NPU算子需要编译后才能执行,为保证数据的准确性,先运行10个step,在第10个step后再profiling1个step。原代码如下:
for i, (images, target) in enumerate(train_loader): # measure data loading time data_time.update(time.time() - end) # move data to the same device as model …… if i % args.print_freq == 0: progress.display(i + 1)修改后代码如下:
for i, (images, target) in enumerate(train_loader): if i == 11: #运行10个step后再profiling模型训练一个step的数据 with torch_npu.npu.profile(profiler_result_path="./result",use_e2e_profiler=True): # measure data loading time data_time.update(time.time() - end) # move data to the same device as model …… if i % args.print_freq == 0: progress.display(i + 1) else: #正常执行模型训练过程 # measure data loading time data_time.update(time.time() - end) # move data to the same device as model …… if i % args.print_freq == 0: progress.display(i + 1) - 拉起模型训练,进行profiling数据采集。拉起训练命令如下:
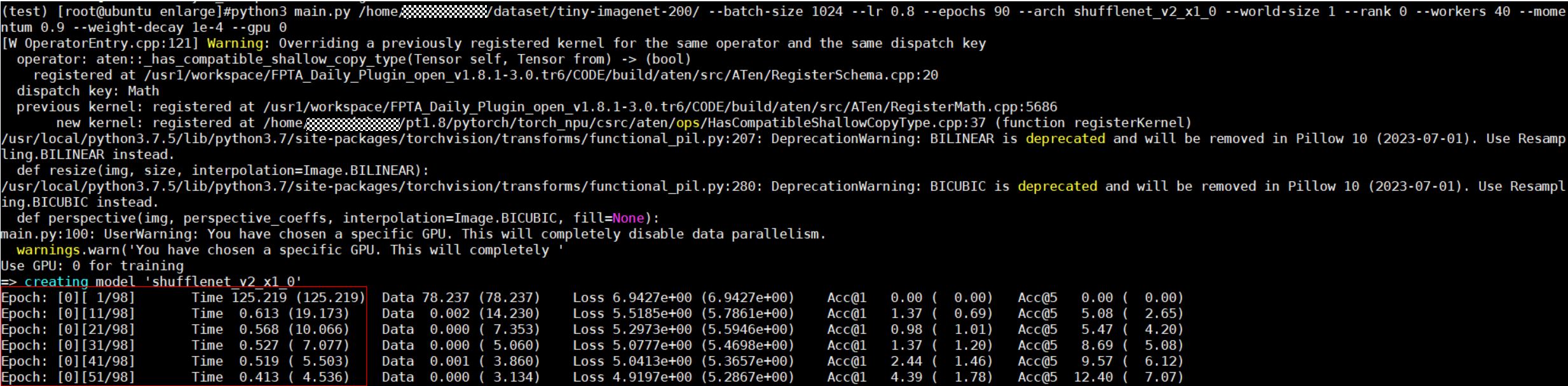
python3 main.py /home/data/resnet50/imagenet --batch-size 1024 \ # 训练批次大小 --lr 0.8 \ # 学习率 --epochs 90 \ # 训练迭代轮数 --arch shufflenet_v2_x1_0 \ # 模型架构 --world-size 1 \ --rank 0 \ --workers 40 \ # 加载数据进程数 --momentum 0.9 \ # 动量 --weight-decay 1e-4 \ # 权重衰减 --gpu 0 # device号, 这里参数名称仍为gpu, 但迁移完成后实际训练设备已在代码中定义为npu - 检查模型训练中每10个step的耗时数据,发现模型训练耗时长,可能存在NPU性能瓶颈,如下图所示。
- 解析性能数据。
- 切换至profiling数据保存路径(本例中为“./result”),执行如下命令(msprof工具路径请根据实际安装路径修改):
/usr/local/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/bin/msprof --export=on --output=./
- 运行完成后,在数据保存路径下生成summary目录(./result/PROF_***/device_0/summary),该目录下为解析得到的.csv性能数据文件。
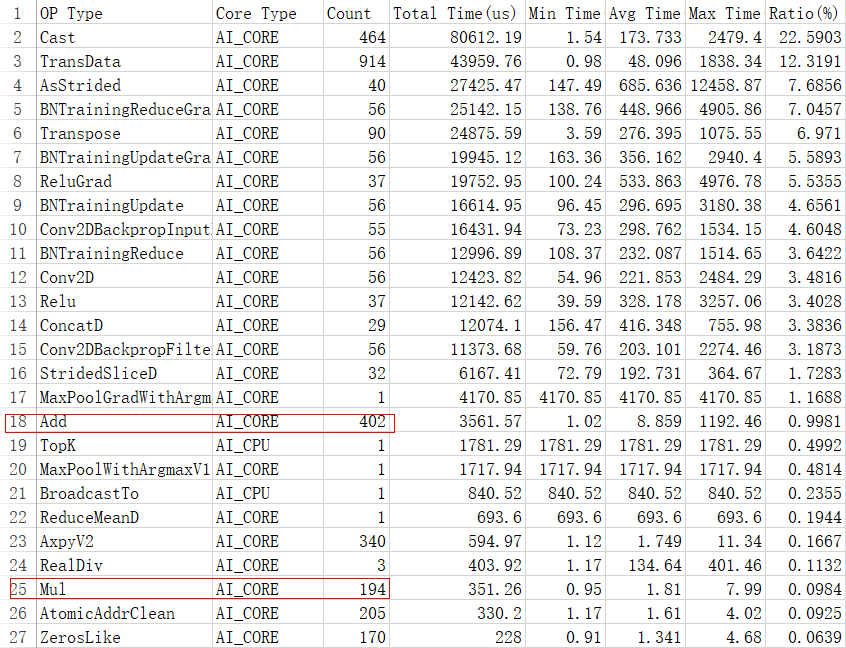
- 分析性能数据文件,分析步骤可见性能数据分析。检查summary目录下的op_statistic文件中的性能数据,发现大量Add、Mul小算子被引入,存在性能瓶颈。如下图所示。
- 切换至profiling数据保存路径(本例中为“./result”),执行如下命令(msprof工具路径请根据实际安装路径修改):
AOE工具自动调优
针对上述NPU性能瓶颈,需要参考《AOE工具使用指南》进行AOE自动调优。本样例中具体AOE调优步骤如下:
- 在脚本原代码中添加如下代码,将算子图dump到本地。以PyTorch1.8.1版本为例:
# switch to train mode model.train() end = time.time() #如果为PyTorch1.5版本,请使用torch.npu.set_aoe(dump_path),dump_path为保存算子子图的路径,请自行设置 torch_npu.npu.set_aoe(dump_path) for i, (images, target) in enumerate(train_loader): if i > 0: #只需要运行一个step exit() if i > 100: pass …… - 配置自定义知识库存储路径的环境变量。bank_path为自定义知识库存储路径。若在执行调优前不配置此环境变量,自定义知识库默认存储在${HOME}/Ascend/latest/data/aoe/custom/graph/${soc_version}路径下。
- 执行AOE调优,命令如下:
aoe --job_type=2 --model_path=dump_path #dump_path为保存算子子图的路径
执行调优后,将逐个打印算子调优完成情况,完成后打印调优总耗时,如下所示:
[Aoe]<xxxx> Single operator tuning process finished. //xxxx:算子名称。 [Aoe]Aoe process finished,cost time ***s. //调优完成,***为调优耗时。
- 调优成功后,还原代码修改,使用调优后的自定义知识库重新训练,并profiling数据,验证性能是否提高。本样例以同一用户在同一套环境上进行AOE调优和训练为例。
- 配置使用自定义知识库的环境变量:
export TUNE_BANK_PATH=bank_path #使能知识库 export ENABLE_TUNE_BANK=True
- 还原脚本中的AOE调优代码修改,再次拉起训练并profiling数据。检查模型训练中每10个step的耗时数据,对比图1,发现已有明显提升,如下图所示。图3 调优后模型训练耗时
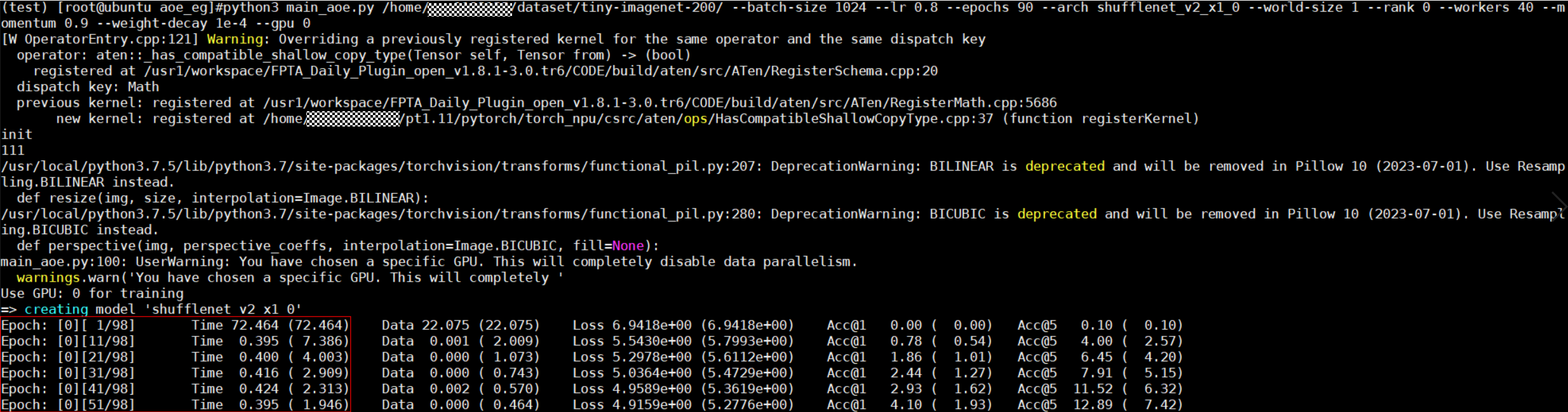
- 解析profiling数据,查看算子调优结果。调优结束后,会在执行调优的工作目录下(./aoe_worksapce)生成每个算子对应的调优结果文件夹,文件夹中会生成命名为“aoe_result.json”的文件,记录调优过程中被调优的算子信息。算子调优结果样例如下:
[ { "basic": { "tuning_name": "ge_proto_00274_MatMul", "tuning_time(s)": 129 } }, { "OPAT": { "opat_tune_result": "tune success", "repo_modified_operators": { "add_repo_operators": [ { "op_name": "MatMul", #算子名称。 "op_type": "MatMul", #算子类型。 "performance_after_tune(us)": 16.95, #调优后算子执行时间,单位:us。 "performance_before_tune(us)": 77.508, #调优前算子执行时间,单位:us。 "performance_improvement": "78.13%" #调优后算子执行时间减少百分比。 } ] }, "repo_summary": { "repo_add_num": 1, "repo_hit_num": 0, "repo_reserved_num": 0, "repo_unsatisfied_num": 0, "repo_update_num": 0, "total_num": 1 } } } ]在以上算子样例中,MatMul算子成功调优后执行时间减少了78.13%,提升了模型运行性能。
- 配置使用自定义知识库的环境变量:
亲和函数调优
针对上述小算子过多瓶颈,为了优化性能,需要替换亲和函数减少梯度更新阶段的Add、Mul算子调用数量。
- 替换亲和函数,函数说明请参考亲和库。
样例原代码如下:
optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=args.momentum, weight_decay=args.weight_decay)样例修改后代码如下:
optimizer = apex.optimizers.NpuFusedSGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay) - 执行模型训练,进行profiling数据采集,解析性能数据。
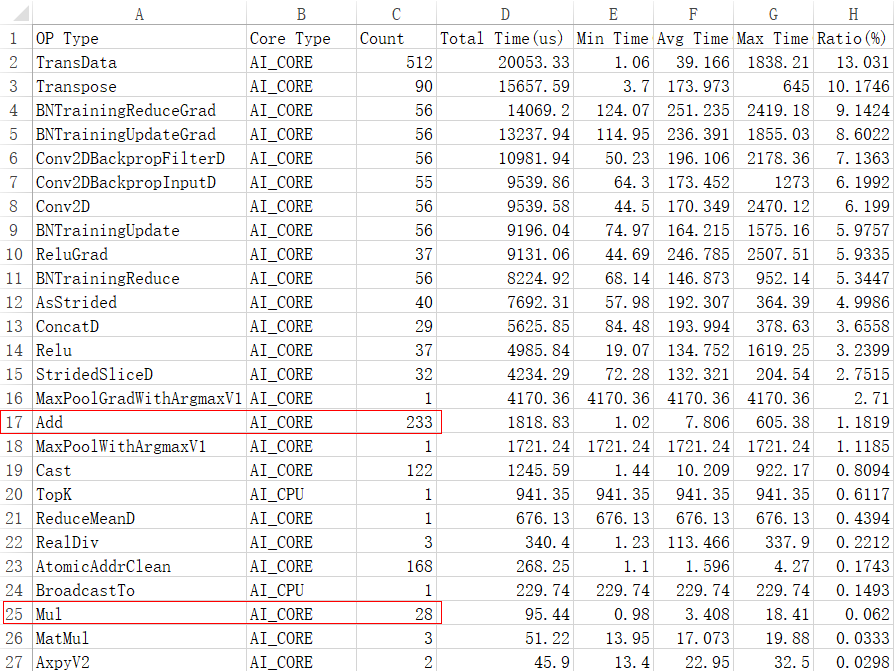
- 解析数据完成后,查看数据保存路径下summary目录下的op_statistic文件中的性能数据。如下图所示,发现调优后Add、Mul小算子数量与图2相比已经明显减少,调优成功。图4 调优后小算子数量
父主题: 模型调优样例参考