vec_cmpv_xx
功能说明
逐element比较两个tensor大小,如果为真则对应比特位为1,否则为0,支持多种比较模式。
函数原型
vec_cmpv_xx (dst, src0, src1, repeat_times, src0_rep_stride, src1_rep_stride)
PIPE:Vector
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
instruction |
输入 |
指令名称,支持以下几种比较:
|
dst |
输出 |
目的操作数,tensor中起始element,支持uint64, uint32, uint16和uint8。 Tensor的scope为Unified Buffer。 |
src0 |
输入 |
源操作数0,tensor中起始element。 Tensor的scope为Unified Buffer。 Atlas 200/300/500 推理产品,支持的数据类型为:Tensor(float16)。 Atlas 训练系列产品,支持的数据类型为:Tensor(float16/float32)。 |
src1 |
输入 |
源操作数1,tensor中起始element。 Tensor的scope为Unified Buffer。 数据类型需保证与src0类型一致。 |
repeat_times |
输入 |
重复迭代次数。
|
src0_rep_stride |
输入 |
相邻迭代间,源操作数0相同block地址步长。 |
src1_rep_stride |
输入 |
相邻迭代间,源操作数1相同block地址步长。 |
返回值
无。
支持的芯片型号
Atlas 200/300/500 推理产品
Atlas 训练系列产品
注意事项
- 无mask参数。
- dst连续产生。比如当源操作数为float16,目的操作数为uint16时,相邻迭代间dst跳8个elements;当源操作数float32,目的操作数为uint16时,跳4个elements。
- src0_rep_stride/src1_rep_stride
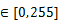 ;单位:block;支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。
;单位:block;支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。 - 为了节省地址空间,开发者可以定义一个Tensor,供源操作数与目的操作数同时使用(即地址重叠),相关约束如下:
- 对于单次repeat(repeat_times=1),且源操作数与目的操作数之间要求100%完全重叠,不支持部分重叠。
- 对于多次repeat(repeat_times>1),若源操作数与目的操作数之间存在依赖,即第N次迭代的目的操作数是第N+1次的源操作数,这种情况是不支持地址重叠的。
- 操作数地址偏移对齐要求请见通用约束。
调用示例
from tbe import tik
tik_instance = tik.Tik()
src0_gm = tik_instance.Tensor("float16", (128,), name="src0_gm", scope=tik.scope_gm)
src1_gm = tik_instance.Tensor("float16", (128,), name="src1_gm", scope=tik.scope_gm)
src0_ub = tik_instance.Tensor("float16", (128,), name="src0_ub", scope=tik.scope_ubuf)
src1_ub = tik_instance.Tensor("float16", (128,), name="src1_ub", scope=tik.scope_ubuf)
dst_gm = tik_instance.Tensor("uint16", (16,), name="dst_gm", scope=tik.scope_gm)
dst_ub = tik_instance.Tensor("uint16", (16,), name="dst_ub", scope=tik.scope_ubuf)
# 拷贝用户输入数据到src ubuf
tik_instance.data_move(src0_ub, src0_gm, 0, 1, 8, 0, 0)
tik_instance.data_move(src1_ub, src1_gm, 0, 1, 8, 0, 0)
# 将dst_ub初始化为全5
tik_instance.vector_dup(16, dst_ub, 5, 1, 1, 1)
tik_instance.vec_cmpv_eq(dst_ub, src0_ub, src1_ub, 1, 8, 8)
# 将计算结果拷贝到目标gm
tik_instance.data_move(dst_gm, dst_ub, 0, 1, 1, 0, 0)
tik_instance.BuildCCE(kernel_name="vec_cmpv_eq", inputs=[src0_gm, src1_gm], outputs=[dst_gm])
结果示例:
输入数据(float16):
src0_gm = {1,2,3,...,128}
src1_gm = {2,2,2,...,2}
输出结果:
dst_gm = {2,0,0,0,0,0,0,0,5,5,5,5,5,5,5,5}
父主题: 比较/选择相关指令