TIK简介
什么是TIK
TIK(Tensor Iterator Kernel)是一种基于Python语言的动态编程框架,呈现为一个Python模块。
开发者可以通过调用TIK提供的API基于Python语言编写自定义算子,然后TIK编译器会编译为适配昇腾AI处理器应用程序的二进制文件。
TIK的优势
TIK算子开发方式是一种灵活的开发方式。TIK代码在算子开发效率和算子性能自动优化上有着一定的优势:
- 并行化:提供程序员串行化编程体系,方便编写算子,TIK工具自动对计算过程并行化,实现高性能。
- 自动内存管理:程序员在编写算子的时候不用感知和管理地址,编译器会做好内存分配。
- 灵活性:通过手动调度可以更加精确的控制数据搬运和计算流程,从而实现更高的性能,将昇腾AI处理器的能力发挥到极致。
- 易调试:区别于其他形式算子验证的黑盒模式,开发人员没有办法一步一步的去定位算子的问题,tik的Debug模式可以帮助用户快速的定位功能问题,极大的缩短了开发调测时间。
TIK编程模型
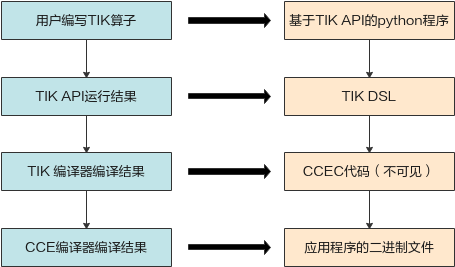
图1是使用TIK进行编程的过程示意图,用户调用TIK API编写算子对应的Python程序后,TIK会将其转化为TIK DSL(TIK DSL是一种DSL语言,它可以在比CCE更高的抽象层次上定义CCEC程序的行为),经过编译器编译后生成CCEC文件(CCEC代码目前对于TIK编程人员无法感知),再经过CCE编译器编译后生成可运行在昇腾AI处理器上的应用程序。
基于TIK API编写Python程序的通用步骤,如图2所示。

下面以一个简单的例子描述TIK程序的编写步骤:
- Python模块导入。
from tbe import tik
“tbe.tik”:提供了所有TIK相关的python函数,具体请参考CANN软件安装后文件存储路径的“python/site-packages/tbe/tik”。
- 构建TIK DSL容器。
from tbe import tik tik_instance = tik.Tik()
- 向TIK DSL容器中,插入TIK DSL语句。
- 在AI Core的外部存储和内部存储中定义输入数据、输出数据。
data_A = tik_instance.Tensor("float16", (128,), name="data_A", scope=tik.scope_gm) data_B = tik_instance.Tensor("float16", (128,), name="data_B", scope=tik.scope_gm) data_C = tik_instance.Tensor("float16", (128,), name="data_C", scope=tik.scope_gm) data_A_ub = tik_instance.Tensor("float16", (128,), name="data_A_ub", scope=tik.scope_ubuf) data_B_ub = tik_instance.Tensor("float16", (128,), name="data_B_ub", scope=tik.scope_ubuf) data_C_ub = tik_instance.Tensor("float16", (128,), name="data_C_ub", scope=tik.scope_ubuf) - 将外部存储中的数据搬入AI Core内部存储(比如Unified Buffer)中。
tik_instance.data_move(data_A_ub, data_A, 0, 1, 128 //16, 0, 0) tik_instance.data_move(data_B_ub, data_B, 0, 1, 128 //16, 0, 0) - 进行计算。
tik_instance.vec_add(128, data_C_ub[0], data_A_ub[0], data_B_ub[0], 1, 8, 8, 8)
- 搬出到外部存储。
tik_instance.data_move(data_C, data_C_ub, 0, 1, 128 //16, 0, 0)
- 在AI Core的外部存储和内部存储中定义输入数据、输出数据。
- 将TIK DSL容器中的语句,编译成昇腾AI处理器可执行的代码,即算子的.o文件和算子描述.json文件。
tik_instance.BuildCCE(kernel_name="simple_add",inputs=[data_A,data_B],outputs=[data_C])
其中,
- kernel_name:指明编译产生的二进制代码中的AI Core核函数名称。
- inputs:存放程序的输入Tensor,为从外部存储中加载的数据,必须是Global Memory的存储类型。
- outputs:存放程序的输出Tensor,对应计算后搬运到外部存储中的数据,必须是Global Memory的存储类型。
编译产生文件的存储位置默认为”./kernel_meta”,也可以通过BuildCCE中的output_files_path参数指定。
上述TIK实例中,将data_A和data_B从外部存储分别搬运到Unified Buffer中,并通过TIK计算接口vec_add()相加,存放到data_C_ub中,然后将data_C_ub中的数据搬到外部存储data_C中。运行该用例,如果输入data_A和data_B分别为128个float16类型的数字1的一维矩阵,则输出data_C为:
data_C: [2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]
以上仅对大致编程过程进行展示,后续会对上述实例中各接口、各参数的含义进行详细描述。
TIK面向的存储模型
在入门学习章节,您已经熟悉了AI Core架构,TIK是基于AI Core架构研发出来的动态编程架构,其面向的存储模型即为AI Core架构的存储模块。
AI Core内的存储介质称为内部存储,对程序员可见的内部存储包括L1 Buffer、L0A Buffer、L0B Buffer、L0C Buffer、Unified Buffer、Scalar Buffer、GPR、SPR等。而AI Core外的存储介质称为外部存储。只有将存储在外部存储内的数据加载到内部存储中,AI Core才能完成相应的计算。详细介绍可参考存储单元,下表简要介绍各内部存储:
存储单元 |
描述 |
TIK标识符 |
|---|---|---|
L1 Buffer |
通用内部存储,AI Core内比较大的一块数据中转区,可暂存AI Core中需要反复使用的一些数据从而减少从总线读写的次数。 某些MTE的数据格式转换功能,要求源数据必须位于L1 Buffer,例如3D图像转2D矩阵(Img2Col)操作。 |
scope_cbuf |
L0A Buffer / L0B Buffer |
Cube指令的左/右矩阵输入。 |
scope_ca/scope_cb |
L0C Buffer |
Cube指令的输出,但进行累加计算的时候,也是输入的一部分。 |
scope_cc |
Unified Buffer |
向量和标量计算的输入和输出。 |
scope_ubuf |
Scalar Buffer |
标量计算的通用Buffer,作为GPR不足时的补充。 |
NA |
GPR |
General-Purpose Register,标量计算的输入和输出。 应用开发工程师不需要具体关注这些寄存器,由系统内部实现封装,程序访问Scalar Buffer并执行标量计算的时候,系统内部自动实现Scalar Buffer和GPR之间的同步。 |
NA |
SPR |
Special-Purpose Register,AI Core的一组配置寄存器。 通过修改SPR的内容可以修改AI Core的部分计算行为。 例如,在Tik中可通过调用sys_set/get()函数实现对应配置的修改,这些配置修改后,有可能改变其他函数的行为。 |
NA |
由于各型号芯片的存储单元大小有所不同,TIK用户在编程时可以通过get_soc_spec查阅各存储单元的大小,便于在编程时决定如何安排程序,实现最高效的执行过程。