执行分布式训练
概述
本节介绍如何基于迁移好的TensorFlow训练脚本,在裸机环境的多个Device上执行训练。
使用前须知:
- 一个Device对应执行一个训练进程,当前不支持多进程在同一个Device上进行训练。
- 如果使用1台训练服务器(Server),要求实际参与集合通信的昇腾AI处理器数目只能为1/2/4/8,且0-3卡和4-7卡各为一个组网,使用2张卡或4张卡训练时,不支持跨组网创建设备集群。
- 如果使用Server集群,即由集群管理主节点+一组训练服务器(Server)组成训练服务器集群,要求参与集合通信的的昇腾AI处理器数目只能为8*n(其中n为参与训练的Server个数,上限为512)。且n为2的指数倍情况下,集群性能最好,建议用户优先采用此种方式进行集群组网。
前提条件
- 准备好包含多个可用的昇腾AI处理器的裸机环境。环境搭建请参见《CANN 软件安装指南》。
- 准备好经过工具迁移好的TensorFlow训练脚本和对应数据集。
- 准备包含两个Device的昇腾AI处理器资源信息配置文件,文件名举例:rank_table_2p.json,配置文件举例:
{ "server_count":"1", "server_list": [ { "device":[ { "device_id":"0", "device_ip":"192.168.1.8", "rank_id":"0" }, { "device_id":"1", "device_ip":"192.168.1.9", // 两个Device需要处于同一网段,0卡和1卡为同一网段 "rank_id":"1" } ], "server_id":"10.0.0.10" } ], "status":"completed", "version":"1.0" }配置文件的详细介绍请参考准备资源配置文件。

用户也可以在此处配置全量的昇腾AI处理器资源信息,后续训练进程启动时仅使用其中的指定的几个昇腾AI处理器资源。
在多Device上执行训练
在多个Device上进行分布式训练时,需要依次拉起所有训练进程,下面以单机两个Device的训练场景举例介绍如何拉起各训练进程。
用户可以在不同的shell窗口依次拉起不同的训练进程。
- 拉起训练进程0。
安装CANN软件后,使用CANN运行用户编译、运行时,需要以CANN运行用户登录环境,执行. ${install_path}/set_env.sh命令设置环境变量。并进行如下配置:
export PYTHONPATH=/home/test:$PYTHONPATH export JOB_ID=10086 export ASCEND_DEVICE_ID=0 export RANK_ID=0 export RANK_SIZE=2 export RANK_TABLE_FILE=/home/test/rank_table_2p.json python3 /home/xxx.py - 拉起训练进程1。
安装CANN软件后,使用CANN运行用户编译、运行时,需要以CANN运行用户登录环境,执行. ${install_path}/set_env.sh命令设置环境变量。并进行如下配置:
export PYTHONPATH=/home/test:$PYTHONPATH export JOB_ID=10086 export ASCEND_DEVICE_ID=1 export RANK_ID=1 export RANK_SIZE=2 export RANK_TABLE_FILE=/home/test/rank_table_2p.json python3 /home/xxx.py
- 除了以上方式,您还可以通过自定义启动脚本通过循环方式依次拉起多个训练进程,具体样例请参考链接。
- 若训练所在系统环境需要升级gcc(例如CentOS、Debian和BClinux系统),则此处动态库查找路径需要添加“${install_path}/lib64”,其中“{install_path}”为gcc升级安装路径。请参见安装7.3.0版本gcc。
检查执行结果
- 检查运行结果。
每个step打印N条数据,说明脚本正常执行。
图1 每个step打印8条数据
当开启环境变量DUMP_GE_GRAPH时,会生成GE的dump图文件。
export DUMP_GE_GRAPH=2
在dump下来的图文件目录下,搜索到包含HcomBroadcast和HcomAllReduce算子:
图2 GE的dump图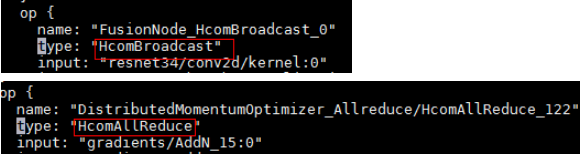
- 如果运行失败,和单Device训练一样,通过日志分析并定位问题。
父主题: 自动迁移和训练