网络模型训练性能分析样例
背景介绍
以TensorFlow网络基础框架的堆叠沙漏网络模型为例执行训练,发现该模型在GPU上的迭代耗时为310ms,而在Atlas 训练系列产品上的迭代耗时达到360ms,Atlas 训练系列产品慢了50ms。通过执行Profiling性能分析,寻找昇腾平台训练迭代耗时高的原因,发现问题在于AI CPU中dropout算子的随机数函数耗时较大。通过查看并修改用户脚本的drop脚本,重新测试性能后迭代端到端的性能得到了提升。
Profiling性能分析思路
Profiling数据采集的目的是通过数据分析出执行推理或训练过程中软件硬件的性能瓶颈,可以根据图1来对数据进行分析。
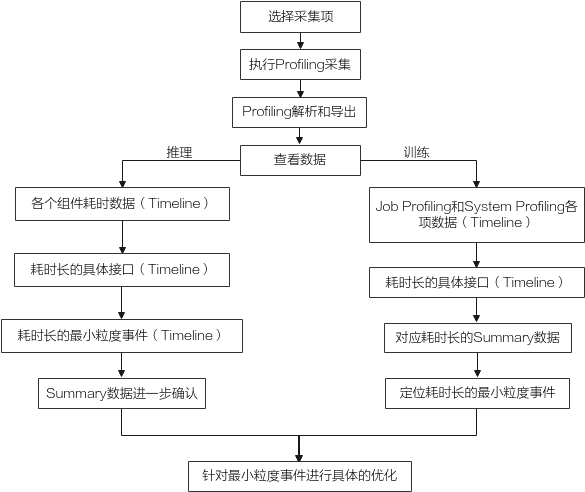
- 根据执行推理或训练场景选择Profiling采集的方式以及采集项。
- 执行Profiling采集、解析并导出Timeline和Summary数据。
- 查看数据:
- 推理:先查看各个组件耗时数据,观察并找出耗时多的接口,找到耗时长的接口详细Timeline文件并进一步分析接口内耗时长的内容,直到定位出最小粒度的事件,找到对应的Summary文件进一步确认,最后针对该事件进行具体的优化。
- 训练:分别查看Job Profiling和System Profiling各项数据的Timeline文件,找出对应耗时较长的项并找出对应是Summary文件,在Summary文件中定位到耗时长的最小粒度事件,针对该事件进行具体的优化。
Profiling性能分析操作
执行以下操作前请参见环境准备完成环境搭建。
通过以下操作方法执行Job Profiling:
- 以Ascend-cann-toolkit开发套件包的运行用户登录环境。以HwHiAiUser用户为例。进入用例路径。
cd ${data_path} - 通过设置环境变量方式,开启Profiling数据采集功能。配置的环境变量内容示例如下。
- 编辑环境变量文件,增加Profiling的配置。
export PROFILING_MODE=true export PROFILING_OPTIONS='{"output":"/home/HwHiAiUser/profiler_data","storage_limit": "500MB","training_trace":"on","task_trace":"on","aicpu":"on","fp_point":"","bp_point":"","aic_metrics":"PipeUtilization"}' - 使设置生效。
详细的使用及参数解释,请参见采集Job Profiling数据(非msprof命令行方式)和Profiling options参数解释。
- 编辑环境变量文件,增加Profiling的配置。
- 执行训练操作。示例如图2所示。
执行命令后等待训练完成。
- 解析profiling数据。
- 切换至msprof.py脚本所在目录,如/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof。

小技巧:为方便执行msprof.py脚本,您可以使用HwHiAiUser用户执行命令alias msprofanlysis='python3 /home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.py'设置别名,后续就可以不用进入/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行profiling命令。
- 执行如下命令,解析任意目录的profiling数据。
python3 msprof.py import -dir /home/HwHiAiUser/profiler_data
此处仅以import方式为例执行解析,详细操作请参见解析Job Profiling数据。
- 切换至msprof.py脚本所在目录,如/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof。
- 在msprof.py脚本所在目录继续执行如下命令导出timeline数据。
python3 msprof.py export timeline -dir /home/HwHiAiUser/profiler_data
执行完上述命令后,会在collection-dir目录下的PROFXXX目录下生成timeline目录,目录中生成对应的json文件,如图3所示,具体内容参见表2。
- 在msprof.py脚本所在目录继续执行如下命令导出summary数据。
python3 msprof.py export summary -dir /home/HwHiAiUser/profiler_data --format csv
执行完上述命令后,会在collection-dir目录下的PROFXXX目录下生成summary目录,目录中生成对应的csv文件,如图4所示,具体内容参见表3。



问题分析
- 迭代耗时分析。
通过解析Profiling数据可得到迭代轨迹数据step_trace_{device_id}_{iter_id}.json。在Chrome浏览器中输入“chrome://tracing”地址,将迭代轨迹数据step_trace_{device_id}_{iter_id}.json拖到空白处进行打开,通过键盘上的快捷键(w:放大 s:缩小 a:左移 d:右移),查看每次迭代的耗时情况。timeline数据展示如下。
从图5中可以看到迭代训练的总耗时为561.827 ms,其中FP+BP耗时为561.599ms,FP+BP耗时可从图6中得到,FP+BP耗时占总耗时的99.9%,两者差异部分为Grad_refresh Bound(梯度更新拖尾)。step_trace_{device_id}_{model_id}_{iter_id}.json对应的summary文件为step_trace_{device_id}_{model_id}_{iter_id}.csv,打开该文件后如下图所示。

基于以上数据可知,Grad_refresh Bound(梯度更新拖尾)部分耗时比算子FP+BP耗时小很多,不存在性能瓶颈,也就是说该模型训练耗时长不是由性能瓶颈导致。那么我们需要接着分析算子的耗时。
- 算子耗时分析。
- AI Core数据op_summary_{device_id}_{iter_id}.csv。该文件统计的是某个迭代下(默认为1),bp_point + fp_point整个链路的算子耗时具体情况。在这个文件中,着重看Task Duration列,它记录着当前算子的耗时。可以通过表格中的自定义排序,选择Task Duration为主要关键字,进行降序重排表格,开头部分截图如下。可见,当前网络中涉及的算子,最大耗时仅231.54us。如图7所示。
从该表中依旧无法判断耗时较长的原因,那么继续打开AI Core算子调用次数及耗时数据。
- AI Core算子调用次数及耗时数据op_statistic_{device_id}_{iter_id}.csv。该文件是对bp_point + fp_point整个链路上算子,不区分OP Name,按算子的OP Type做了统计。比如将 Mul 算子统计为一行,统计调用次数,总耗时,平均耗时,最大耗时,最小耗时等。通过表格中的自定义排序,选择Ratio(%)为主要关键字,进行降序重排表格,截图如下。可见,AI CPU在整体耗时占比达到76.5%。如图8所示。
- 问题定位到了AI CPU耗时上,那么我们查看aicpu_{device_id}_{iter_id}.csv文件。通过表格中的自定义排序,选择Total_time为主要关键字,进行降序重排表格,截图如下。可以看到在AI CPU中耗时最大的是dropout算子中的随机数函数,且已经达到了毫秒级别。如图9所示。
到此Profiling性能分析工具的任务已经完成。
- AI Core数据op_summary_{device_id}_{iter_id}.csv。该文件统计的是某个迭代下(默认为1),bp_point + fp_point整个链路的算子耗时具体情况。在这个文件中,着重看Task Duration列,它记录着当前算子的耗时。可以通过表格中的自定义排序,选择Task Duration为主要关键字,进行降序重排表格,开头部分截图如下。可见,当前网络中涉及的算子,最大耗时仅231.54us。如图7所示。





问题解决


结论
通过Profiling性能分析工具对模型训练的迭代端到端性能进行分析,定位到耗时最长的算子,通过修改训练脚本,最终提升了模型在Atlas 训练系列产品的训练性能