TF Adapter简介
TF Adapter为加速TensorFlow图在昇腾AI处理器上执行的TensorFlow插件,主要目的是将TensorFlow图转换为昇腾AI处理器上可以执行的图。
TF Adapter在昇腾AI软件栈中的位置如下图所示。
TensorFlow网络执行时各组件交互流程
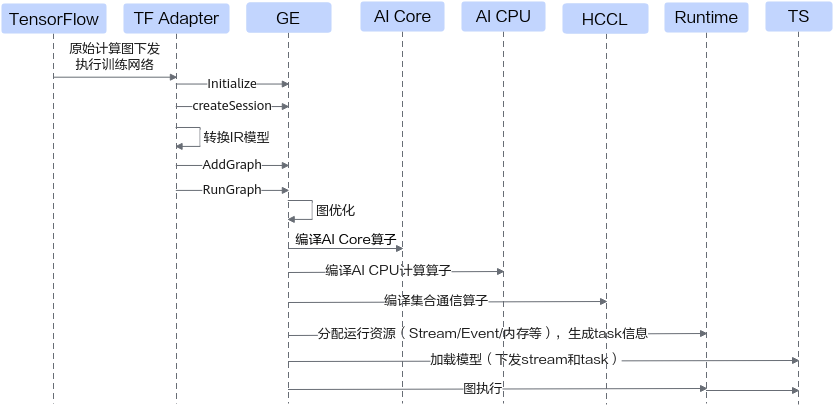
- 当用户执行训练代码后,TensorFlow前端会根据用户提供的训练脚本,生成训练模型,读取指定路径下的checkpoint文件完成模型权重初始化或随机初始化。
- 随后,框架前端会通过TF Adapter调用GE初始化接口,完成设备打开、计算引擎初始化、算子信息库初始化等操作,然后,将前端训练模型转换为IR格式的模型,并启动模型编译和执行;在图引擎GE中,它还会完成Shape推导、常量折叠、算子融合等优化操作。在完成图优化后会根据算子的执行引擎将计算图拆分为不同的子图,每个子图都可以执行在同一个设备上,而在每一个具体模块中,也会进行特定的子图优化。
- 待计算图的编译和优化都完成后,GE会调用Runtime接口分配运行资源,包含内存、 Stream、Event等,待计算资源分配完成后,交由Runtime运行时对资源进行管理。
用户Python接口
【接口简介】
- 扩展Estimator API,提供在昇腾AI处理器上进行高效训练的易用API。
- 提供session策略、子图下沉、预处理下沉等配置项。
- 提供资源初始化相关API。
- 提供分布式训练API,例如npu_distributed_optimizer_wrapper,提供简便的基于RING-ALLREDUCE的数据并行分布式训练架构接口。
【获取路径】
“tfplugin安装目录/tfplugin/latest/python/site-packages/npu_bridge”
【头文件引用】
使用接口前,可以新增以下头文件引用,用于导入NPU相关库。
1
|
from npu_bridge.npu_init import * |

引入上述头文件后,训练脚本默认在昇腾AI处理器执行。
然后直接使用相关接口:
1 2 3 4 5 |
mnist_classifier=NPUEstimator( model_fn=cnn_model_fn, config=npu_config, model_dir="/tmp/mnist_convert_model" ) |
也可以通过如下方式导入:
1
|
from npu_bridge.estimator.npu.npu_estimator import NPUEstimator |
子图拆分优化器
TF Adapter在TensorFlow图执行器扩展子图拆分优化器。子图拆分优化器在TensorFlow图构建、图拆分、图优化后执行,作用是识别可下沉到Device执行的节点,对可下沉节点进行边收缩,使连续的可下沉的节点变为一副子图,并在原图上添加一个持有该子图的GEOP算子。GEOP算子为TF Adapter扩展的TensorFlow算子,在TensorFlow Runtime中运行,作用是将标识的子图下沉到Device执行。
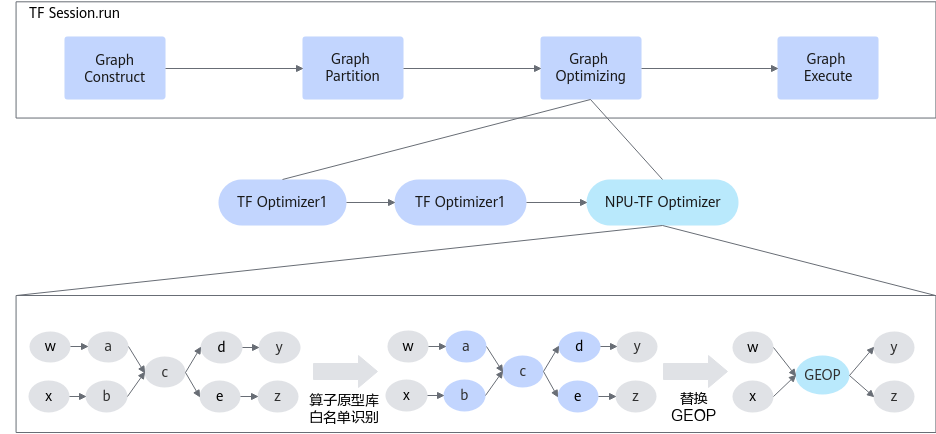
全下沉与混合计算
昇腾AI处理器默认采用计算全下沉模式,即所有的计算类算子全部下沉到Device侧执行,从而利用昇腾AI处理器进行加速。针对在计算图中有不支持的算子的场景(例如py_func),为提供灵活性和扩展性,提供混合计算模式,将不支持在Device侧执行的算子留在Host由前端框架执行。
混合计算场景下,TF Adapter会通过NPU算子支持清单(“CANN软件安装目录/opp/built-in/framework/tensorflow/npu_supported_ops.json”)识别哪些算子可下沉到昇腾AI处理器执行,其中清单内的算子会下沉到Device执行,清单外的算子留在Host由前端框架执行。
混合计算场景下,用户还可通过接口自行指定不下沉的算子,更多介绍请参考混合计算。