训练循环下沉时设置NPU上的循环次数
该迁移点只要求设置一个NPU上的循环下沉次数,我们称之为npu loop size,有两种方法设置:
- 通过环境变量“NPU_LOOP_SIZE”设置,例如
export NPU_LOOP_SIZE=32
该变量需要在import npu_device前设置。
- 通过在您的训练脚本中调用npu.set_npu_loop_size接口进行设置,修改的内容很简单,但是需要您理解npu loop size的含义。
npu loop size用于提升NPU训练的性能,在介绍npu loop size的由来前,先介绍TF2原生流程中的一些性能损耗点。以GPU为例,GPU环境常规训练方式下的工作时序,如下图所示,脚本侧用户控制执行十次训练,每次在GPU上执行一次训练步,训练步结束后,回到python侧,用户判断当前步数等于10,启动下一次训练,直至训练完十次训练。
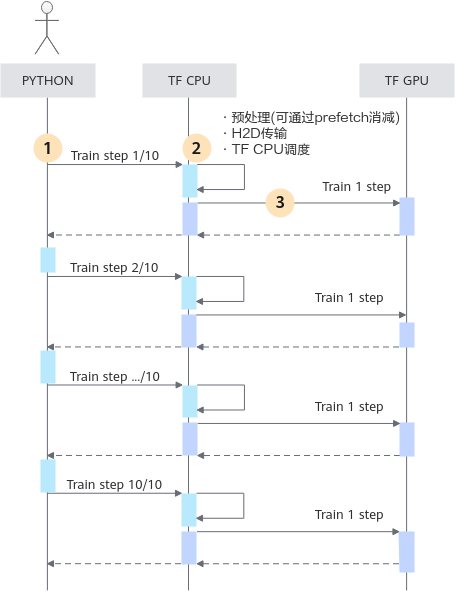
观察时序图上的有色区域我们不难发现,此时不论是CPU还是GPU都是间歇性工作的,该模式下的缺陷:
- Python解释器存在额外开销,且运行耗时不稳定,两个训练步间的间隙造成性能黑洞。
- 数据预处理与GPU训练过程的流水不充分,虽然TF2 Dataset的prefetch功能可以消减预处理过程的耗时影响,但是每次训练时H2D(Host to Device)的数据传输以及CPU调度耗时是无法忽略的。
TF2为了省去Python解释器上的额外开销,推荐用户使用While算子来实现训练循环(也就是所谓的循环下沉,循环下沉并非NPU特有的策略),此时判断训练是否达到指定步数的逻辑不再在Python解释器中进行,而是依赖TF2中的While算子,在编码时,使用者应当这样组织自己的训练(下称“循环下沉的编码方式”):
1 2 3 4 |
@tf.function def loop_train(iterator, steps): for i in tf.range(steps): train_step(next(iterator)) |
这样的TF2代码,在编译后,会将训练步嵌套在While算子中执行,时序变为下图所示:
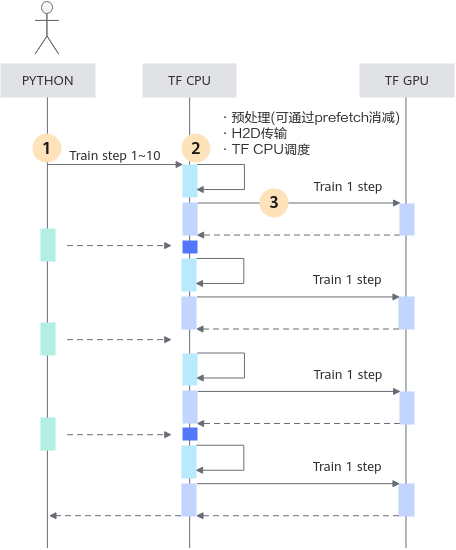
可以看出,采用循环下沉的策略后,在Python解释器上的耗时转移到TF CPU上,耗时更短也更稳定,但是在该形式下,仍然有两部分额外开销:
- 预处理H2D数据传输。
- 判定训练到达指定步数的算子计算耗时。
NPU为了达到较优性能,采取了两个策略来消除这两部分额外耗时:
- 异步预处理H2D线程,使得预处理输出传输与NPU训练完全异步,H2D的传输隐藏在NPU训练过程中。
- 需要用户指定训练循环下沉次数,消除次数判断算子计算耗时(也用于指示预处理数据H2D异步传输次数)。
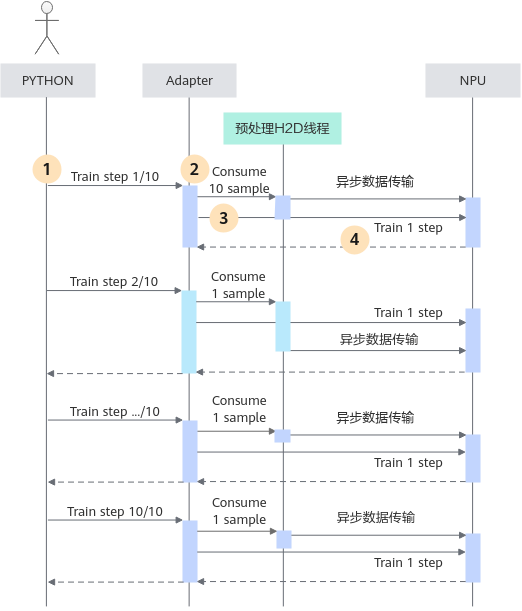
异步数据传输指TF Adapter的预处理线程主动向NPU发送训练数据,在未使用循环下沉的方式编码时,执行时序如下所示:
此时可以一定程度上消减数据预处理H2D数据传输与CPU调度的耗时(下发训练步的同时,数据传输正在进行)。
当使用了训练循环下沉的编码方式时,NPU上的执行时序图为:
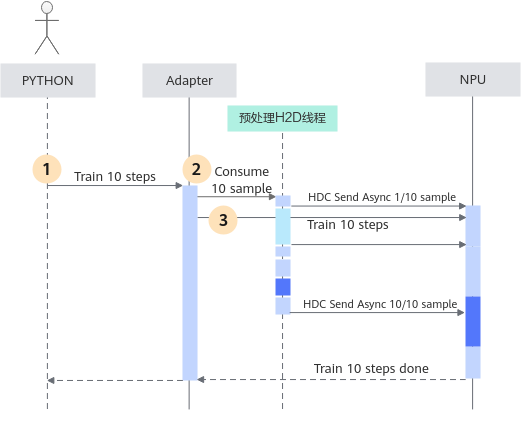
可以看到:
- 脚本发起在NPU上训练十次的请求后,直到训练结束,都不会再与Python解释器交互,而是单纯的NPU运算。
- 预处理的耗时抖动,可以被前面训练步中预处理领先NPU运算的耗时抵消,从而可以抵御更大的数据预处理性能波动。
NPU训练循环下沉与异步预处理数据传输方式可以最大程序地减少训练计算无关的耗时,最大化性能收益,但同时对用户训练有额外约束:
由于预处理线程与NPU训练步异步,在使用循环下沉的编码方式时,需要告诉NPU当前的循环下沉次数,所以NPU要求用户在使用循环下沉的编码方式时,额外设置npu loop size,用于指示循环下沉执行的次数。
比如,您使用循环下沉的编码方式组织您的训练:
1 2 3 4 |
@tf.function def loop_train(iterator, steps): for i in tf.range(steps): train_step(next(iterator)) |
当您期望每次loop_train调用会在NPU上训练100个Step时,此时您有两种方式设置npu loop size:
- 在启动训练前通过NPU_LOOP_SIZE的环境变量设置:
export NPU_LOOP_SIZE=100
- 在Python脚本调用loop_train前调用npu.set_npu_loop_size设置,然后就可以调用loop_train,并传入循环次数100:
1 2
npu.set_npu_loop_size(100) loop_train(train_iter, tf.constant(100))
您也可以在训练过程中调用npu.set_npu_loop_size来改变NPU上每次下沉执行的步数,比如您总共训练100个Step,希望每次在NPU上循环执行30Step,显然,最后的91~100Step小于npu loop size,此时你可以在训练完90Step后调用npu.set_npu_loop_size来调整npu loop size的大小:
1 2 3 4 5 6 7 8 9 |
remaining_steps = 100 # 剩余Steps数 base_loop_size = 30 # 基准npu loop size npu.set_npu_loop_size(base_loop_size) while remaining_steps >= base_loop_size: # 按照基准loop循环下沉训练,直到剩余Step数不足一次loop loop_train(train_iterator, tf.constant(base_loop_size)) remaining_steps -= base_loop_size if remaining_steps > 0: # 如果还有未处理的数据,调整为一个较小的npu loop size处理 npu.set_npu_loop_size(remaining_steps) loop_train(train_iterator, tf.constant(remaining_steps)) |