分析Profiling数据
开发人员可通过分析Profiling工具解析得到Timeline和Summary文件,识别性能瓶颈点。
下面仅介绍常用的关键性能数据文件,关于更多Profiling数据文件的介绍可参见《性能调优工具指南》 。
- timeline文件:step_trace_*.csv
“step_trace_*.csv”记录了迭代轨迹数据信息,包含每轮迭代的耗时,主要字段及含义如下:
- Iteration Time:一轮迭代的计算时间,主要包含FP/BP和Grad Refresh两个阶段的时间。
- FP to BP Time:网络正向传播和反向传播的计算时间。
- Iteration Refresh:迭代拖尾时间。
- Data Aug Bound:两个相邻Iteration Time的间隔时间。
展示数据如下图所示,开发者进行数据分析时,需要注意选择合适的Iteration ID和Model ID的数据。
图1 step_trace_*.csv文件示例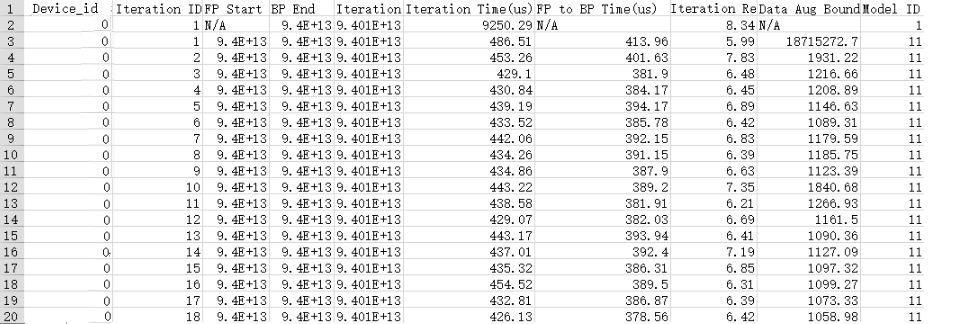
从上面示例可以看出,Model ID=1的数据明显与后续不同,为初始化图,而Model ID=11才为真正的迭代计算图,因此要选择Model ID=11的数据进行分析。另外,可以看到在Model ID=11,Iteration ID=1时,Data Aug Bound的时间很长,因为该阶段存在编译等操作,所以耗时较长,因此需要选择Model ID=11且Iteration ID>2的数据进行分析。
- summary文件:op_statistic_*.csv与op_summary_*.csv
“op_statistic_*.csv”文件记录了AI Core和AI CPU算子调用次数及耗时统计,“op_summary_*.csv”文件记录了详细的AI Core和AI CPU算子数据。
开发者可根据“op_statistic_*.csv”文件初步判断耗时较长的算子,然后再根据耗时长的算子,查找“op_summary_*.csv”文件中的详细信息,从而定位出最小粒度事件。
父主题: Profiling数据采集与分析