torch_npu.npu_moe_gating_top_k
功能描述
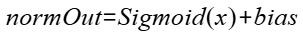
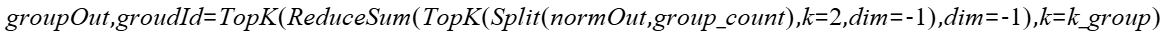
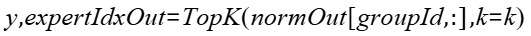
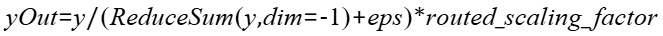
接口原型
npu_moe_gating_top_k(Tensor x, int k, *, Tensor? bias=None, int k_group=1, int group_count=1, int group_select_mode=0, int renorm=0, int norm_type=1, bool out_flag=False, float routed_scaling_factor=1.0, float eps=1e-20) -> (Tensor, Tensor, Tensor)
参数说明
- x:Tensor类型,公式中的x,要求是一个2D的Tensor,数据类型支持float16、bfloat16、float32,数据格式要求为ND。支持非连续Tensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :x最后一维的大小(即专家数)当前只支持取256。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :x最后一维的大小(即专家数)当前只支持取256。
- k:整型,公式中的k,每个token最终筛选得到的专家个数,数据类型为int64。要求1≤k≤x.shape[-1]/group_count*k_group。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :k取值范围为[1, 32]。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :k取值范围为[1, 32]。
- bias:Tensor类型,公式中的bias,可选参数。要求是1D的Tensor,要求shape值与x的最后一维相等。数据类型支持float16、bfloat16、float32,数据类型需要与x保持一致,数据格式要求为ND。支持非连续Tensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :必须不为None。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :必须不为None。
- k_group:整型,公式中的k_group,每个token组筛选过程中,选出的专家组个数,数据类型为int64,默认为1。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :k_group当前只支持取4。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :k_group当前只支持取4。
- group_count:整型,公式中的group_count,表示将全部专家划分的组数,数据类型为int64,默认为1。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :group_count当前只支持取8。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :group_count当前只支持取8。
- group_select_mode:整型,表示一个专家组的总得分计算方式。默认值为0,表示取组内Top2的专家进行得分累加,作为专家组得分。当前仅支持默认值0。
- renorm:整型,renorm标记,当前仅只支持0,表示先进行norm再进行topk计算。
- norm_type:整型,表示norm函数类型,当前仅支持1,表示使用Sigmoid函数。
- out_flag:布尔型,是否输出norm函数中间结果。当前仅支持False,表示不输出。
- routed_scaling_factor:float类型,公式中的routed_scaling_factor系数,默认值1.0。
- eps:float类型,公式中的eps系数,默认值1e-20。
输出说明
- yOut:Tensor类型,公式中输出yOut,表示对x做norm操作和分组排序topk后计算的结果。要求是一个2D的Tensor,数据类型支持float16、bfloat16、float32,数据类型与x需要保持一致,数据格式要求为ND,第一维的大小要求与x的第一维相同,最后一维的大小与k相同。不支持非连续Tensor。
- expertIdxOut:Tensor类型,公式中输出expertIdxOut,表示对x做norm操作和分组排序topk后的索引,即专家的序号。shape要求与yOut一致,数据类型支持int32,数据格式要求为ND。不支持非连续Tensor。
- normOut:Tensor类型,公式中输出normOut,norm计算的输出结果。shape要求与x保持一致,数据类型为float32,数据格式要求为ND。不支持非连续Tensor。
约束说明
- 该接口仅在推理场景下使用。
- 该接口支持图模式(目前仅支持PyTorch 2.1版本)。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
import torch import torch_npu import numpy k = 1 k_group = 4 group_count = 8 group_select_mode = 1 renorm = 0 norm_type = 1 out_flag = False routed_scaling_factor = 1.0 eps = 1e-20 # 生成随机数据, 并发送到npu x = numpy.random.uniform(0, 2, (16, 256)).astype(numpy.float16) bias = numpy.random.uniform(0, 2, (256,)).astype(numpy.float16) x_tensor = torch.tensor(x).npu() bias_tensor = torch.tensor(bias).npu() # 调用MoeGatingTopK算子 y_npu, expert_idx_npu, out_npu = torch_npu.npu_moe_gating_top_k(x_tensor, k, bias=bias_tensor, k_group=k_group, group_count=group_count, group_select_mode=group_select_mode, renorm=renorm, norm_type=norm_type, out_flag=out_flag, routed_scaling_factor=routed_scaling_factor, eps=eps)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
# 入图方式 import torch import torch_npu import torchair import numpy class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, x_tensor, bias_tensor): return torch_npu.npu_moe_gating_top_k(x_tensor, k, bias=bias_tensor, k_group=k_group, group_count=group_count, group_select_mode=group_select_mode, renorm=renorm, norm_type=norm_type, out_flag=out_flag, routed_scaling_factor=routed_scaling_factor, eps=eps) # 实例化模型model model = Model().npu() # 从TorchAir获取NPU提供的默认backend config = torchair.CompilerConfig() npu_backend = torchair.get_npu_backend(compiler_config=config) # 使用TorchAir的backend去调用compile接口编译模型 model = torch.compile(model, backend=npu_backend) k = 1 k_group = 4 group_count = 8 group_select_mode = 1 renorm = 0 norm_type = 1 out_flag = False routed_scaling_factor = 1.0 eps = 1e-20 # 生成随机数据, 并发送到npu x = numpy.random.uniform(0, 2, (16, 256)).astype(numpy.float16) bias = numpy.random.uniform(0, 2, (256,)).astype(numpy.float16) x_tensor = torch.tensor(x).npu() bias_tensor = torch.tensor(bias).npu() # 调用MoeGatingTopK算子 y_npu, expert_idx_npu, out_npu = model(x_tensor, bias_tensor)
父主题: torch_npu