torch_npu.npu_moe_distribute_combine
功能描述
- 算子功能:先进行reduce_scatterv通信,再进行alltoallv通信,最后将接收的数据整合(乘权重再相加)。需与torch_npu.npu_moe_distribute_dispatch配套使用,相当于按npu_moe_distribute_dispatch算子收集数据的路径原路返还。
- 计算公式:
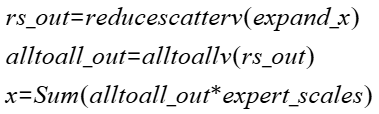
接口原型
torch_npu.npu_moe_distribute_combine(Tensor expand_x, Tensor expert_ids, Tensor expand_idx, Tensor ep_send_counts, Tensor expert_scales, str group_ep, int ep_world_size, int ep_rank_id, int moe_expert_num, *, Tensor? tp_send_counts=None, Tensor? x_active_mask=None, Tensor? activation_scale=None, Tensor? weight_scale=None, Tensor? group_list=None, Tensor? expand_scales=None, str group_tp="", int tp_world_size=0, int tp_rank_id=0, int expert_shard_type=0, int shared_expert_num=1, int shared_expert_rank_num=0, int global_bs=0, int out_dtype=0, int comm_quant_mode=0, int group_list_type=0) -> Tensor
参数说明

参数里Shape使用的变量如下:
- A:表示本卡能发送的最大token数量,取值范围如下
- 对于共享专家,要满足A=BS*ep_world_size*shared_expert_num/shared_expert_rank_num。
- 对于MoE专家,当global_bs为0时,要满足A>=BS*ep_world_size*min(local_expert_num, K);当global_bs非0时,要满足A>=global_bs* min(local_expert_num, K)。
- H:表示hidden size隐藏层大小。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :取值范围(0,7168],且保证是32的整数倍。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :取值为7168。
- BS:表示待发送的token数量。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :取值范围为0<BS≤256。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :取值范围为0<BS≤512。
- K:表示选取topK个专家,取值范围为0<K≤8同时满足0<K≤moe_expert_num。
- server_num:表示服务器的节点数,取值只支持2、4、8。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :仅该场景的shape使用了该变量。
- local_expert_num:表示本卡专家数量。
- 对于共享专家卡,local_expert_num=1
- 对于MoE专家卡,local_expert_num=moe_expert_num/(ep_world_size-shared_expert_rank_num),当local_expert_num>1时,不支持TP域通信。
- expand_x:Tensor类型,根据expertIds进行扩展过的token特征,要求为2D的Tensor,shape为(max(tp_world_size, 1) *A, H),数据类型支持bfloat16、float16,数据格式为ND,支持非连续的Tensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持共享专家场景。
- expert_ids:Tensor类型,每个token的topK个专家索引,要求为2D的Tensor,shape为(BS, K)。数据类型支持int32,数据格式为ND,支持非连续的Tensor。对应torch_npu.npu_moe_distribute_dispatch的expert_ids输入,张量里value取值范围为[0, moe_expert_num),且同一行中的K个value不能重复。
- expand_idx:Tensor类型,表示给同一专家发送的token个数,要求是1D的Tensor,shape为(BS*K, )。数据类型支持int32,数据格式为ND,支持非连续的Tensor。对应torch_npu.npu_moe_distribute_dispatch的expand_idx输出。
- ep_send_counts:Tensor类型,表示本卡每个专家发给EP(Expert Parallelism)域每个卡的数据量,要求是1D的Tensor 。数据类型支持int32,数据格式为ND,支持非连续的Tensor。对应torch_npu.npu_moe_distribute_dispatch的ep_recv_counts输出。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :要求shape为(moe_expert_num+2*global_bs*K*server_num, )。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :要求shape为(ep_world_size*max(tp_world_size, 1)*local_expert_num, )。
- expert_scales:Tensor类型,表示每个Token的topK个专家的权重,要求是2D的Tensor,shape为(BS, K),其中共享专家不需要乘权重系统,直接相加即可。数据类型支持float,数据格式为ND,支持非连续的Tensor。
- group_ep:string类型,EP通信域名称,专家并行的通信域。字符串长度范围为[1, 128),不能和group_tp相同。
- ep_world_size:int类型,必选参数,EP通信域size。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :取值支持16、32、64。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :取值支持8、16、32、64、128、144、256、288。
- ep_rank_id:int类型,EP通信域本卡ID,取值范围[0, ep_world_size),同一个EP通信域中各卡的ep_rank_id不重复。
- moe_expert_num:int类型,MoE专家数量,取值范围[1, 512],并且满足moe_expert_num%(ep_world_size-shared_expert_rank_num)=0。
- tp_send_counts:Tensor类型,可选参数,表示本卡每个专家发给TP(Tensor Parallelism)通信域每个卡的数据量。对应torch_npu.npu_moe_distribute_dispatch的tp_recv_counts输出。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持TP通信域,使用默认输入。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :支持TP通信域,要求是一个1D Tensor,shape为 (tp_world_size, ),数据类型支持int32,数据格式要求为ND,支持非连续的Tensor。
- x_active_mask:Tensor类型,预留参数,暂未使用,使用默认值即可。
- activation_scale:Tensor类型,预留参数,暂未使用,使用默认值即可。
- weight_scale:Tensor类型,预留参数,暂未使用,使用默认值即可。
- group_list:Tensor类型,预留参数,暂未使用,使用默认值即可。
- expand_scales:Tensor类型,对应torch_npu.npu_moe_distribute_dispatch的expand_scales输出。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :必选参数,要求是1D的Tensor,shape为(A,),数据类型支持float,数据格式为ND,支持非连续的Tensor。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :暂不支持该参数,使用默认值即可。
- group_tp:string类型,可选参数,TP通信域名称,数据并行的通信域。有TP域通信才需要传参。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持TP域通信,使用默认值即可。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :当有TP域通信时,字符串长度范围为[1, 128),不能和group_ep相同。
- tp_world_size:int类型,可选参数,TP通信域size。有TP域通信才需要传参。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持TP域通信,使用默认值0即可。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :当有TP域通信时,取值范围[0, 2],0和1表示无TP域通信,2表示有TP域通信。
- tp_rank_id:int类型,可选参数,TP通信域本卡ID。有TP域通信才需要传参。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持TP域通信,使用默认值0即可。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :当有TP域通信时,取值范围[0, 1],同一个TP通信域中各卡的tp_rank_id不重复。无TP域通信时,传0即可。
- expert_shard_type:int类型,表示共享专家卡排布类型。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :暂不支持该参数,使用默认值即可。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :当前仅支持0,表示共享专家卡排在MoE专家卡前面。
- shared_expert_num:int类型,表示共享专家数量,一个共享专家可以复制部署到多个卡上。预留参数,暂未使用,使用默认值即可。
- shared_expert_rank_num:int类型,可选参数,表示共享专家卡数量。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :不支持共享专家,传0即可。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :取值范围[0, ep_world_size-1)。取0表示无共享专家,不取0需满足ep_world_size%shared_expert_rank_num=0。
- global_bs:int类型,可选参数,表示EP域全局的batch size大小。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :当每个rank的BS不同时,传入256*ep_world_size;当每个rank的BS相同时,支持取值0或BS*ep_world_size。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :支持取0或BS*ep_world_size。
- out_dtype:int类型,预留参数,暂未使用,使用默认值即可。
- comm_quant_mode:int类型,预留参数,暂未使用,使用默认值即可。
- group_list_type:int类型,预留参数,暂未使用,使用默认值即可。
输出说明
x:Tensor类型,表示处理后的token, 要求是2D的Tensor,shape为(BS, H),数据类型支持bfloat16、float16,类型与输入expand_x保持一致,数据格式为ND,不支持非连续的Tensor。
约束说明
- 该接口支持推理场景下使用。
- 该接口支持静态图模式(PyTorch 2.1版本)。
- 调用接口过程中使用的group_ep、ep_world_size、moe_expert_num、group_tp、tp_world_size、expert_shard_type、shared_expert_num、shared_expert_rank_num、global_bs参数取值所有卡保持一致,且和torch_npu.npu_moe_distribute_dispatch对应参数也保持一致。
Atlas A3 训练系列产品/Atlas A3 推理系列产品 :该场景下单卡包含双DIE(简称为“晶粒”或“裸片”),因此参数说明里的“本卡”均表示单DIE。- 调用本接口前需检查HCCL_BUFFSIZE环境变量取值是否合理:
CANN环境变量HCCL_BUFFSIZE:表示单个通信域占用内存大小,单位MB,不配置时默认为200MB。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :要求>=2*(BS*ep_world_size*min(local_expert_num, K)*H*sizeof(unit16)+2MB)。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :要求大于等于2且满足1024*1024*(HCCL_BUFFSIZE-2)/2>=(BS*2*(H+128)*(ep_world_size*local_expert_num+K+1)。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :当K=8且BS<=128时,配置环境变量HCCL_INTRA_PCIE_ENABLE=1和HCCL_INTRA_ROCE_ENABLE=0可以减少跨机通信数据量,提升算子性能。此时要求HCCL_BUFFSIZE>=moe_expert_num*BS*(H*sizeof(dtypeX)+4*K*sizeof(uint32))+4MB+100MB。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件
Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157
import os import torch import random import torch_npu import numpy as np from torch.multiprocessing import Process import torch.distributed as dist from torch.distributed import ReduceOp # 控制模式 quant_mode = 2 # 2为动态量化 is_dispatch_scales = True # 动态量化可选择是否传scales input_dtype = torch.bfloat16 # 输出dtype server_num = 1 server_index = 0 port = 50001 master_ip = '127.0.0.1' dev_num = 16 world_size = server_num * dev_num rank_per_dev = int(world_size / server_num) # 每个host有几个die sharedExpertRankNum = 2 # 共享专家数 moeExpertNum = 14 # moe专家数 bs = 8 # token数量 h = 7168 # 每个token的长度 k = 8 random_seed = 0 tp_world_size = 1 ep_world_size = int(world_size / tp_world_size) moe_rank_num = ep_world_size - sharedExpertRankNum local_moe_expert_num = moeExpertNum // moe_rank_num globalBS = bs * ep_world_size is_shared = (sharedExpertRankNum > 0) is_quant = (quant_mode > 0) def gen_unique_topk_array(low, high, bs, k): array = [] for i in range(bs): top_idx = list(np.arange(low, high, dtype=np.int32)) random.shuffle(top_idx) array.append(top_idx[0:k]) return np.array(array) def get_new_group(rank): for i in range(tp_world_size): # 如果tp_world_size = 2,ep_world_size = 8,则为[[0, 2, 4, 6, 8, 10, 12, 14], [1, 3, 5, 7, 9, 11, 13, 15]] ep_ranks = [x * tp_world_size + i for x in range(ep_world_size)] ep_group = dist.new_group(backend="hccl", ranks=ep_ranks) if rank in ep_ranks: ep_group_t = ep_group print(f"rank:{rank} ep_ranks:{ep_ranks}") for i in range(ep_world_size): # 如果tp_world_size = 2,ep_world_size = 8,则为[[0, 1], [2, 3], [4, 5], [6, 7], [8, 9], [10, 11], [12, 13], [14, 15]] tp_ranks = [x + tp_world_size * i for x in range(tp_world_size)] tp_group = dist.new_group(backend="hccl", ranks=tp_ranks) if rank in tp_ranks: tp_group_t = tp_group print(f"rank:{rank} tp_ranks:{tp_ranks}") return ep_group_t, tp_group_t def get_hcomm_info(rank, comm_group): if torch.__version__ > '2.0.1': hcomm_info = comm_group._get_backend(torch.device("npu")).get_hccl_comm_name(rank) else: hcomm_info = comm_group.get_hccl_comm_name(rank) return hcomm_info def run_npu_process(rank): torch_npu.npu.set_device(rank) rank = rank + 16 * server_index dist.init_process_group(backend='hccl', rank=rank, world_size=world_size, init_method=f'tcp://{master_ip}:{port}') ep_group, tp_group = get_new_group(rank) ep_hcomm_info = get_hcomm_info(rank, ep_group) tp_hcomm_info = get_hcomm_info(rank, tp_group) # 创建输入tensor x = torch.randn(bs, h, dtype=input_dtype).npu() expert_ids = gen_unique_topk_array(0, moeExpertNum, bs, k).astype(np.int32) expert_ids = torch.from_numpy(expert_ids).npu() expert_scales = torch.randn(bs, k, dtype=torch.float32).npu() scales_shape = (1 + moeExpertNum, h) if sharedExpertRankNum else (moeExpertNum, h) if is_dispatch_scales: scales = torch.randn(scales_shape, dtype=torch.float32).npu() else: scales = None expand_x, dynamic_scales, expand_idx, expert_token_nums, ep_recv_counts, tp_recv_counts, expand_scales = torch_npu.npu_moe_distribute_dispatch( x=x, expert_ids=expert_ids, group_ep=ep_hcomm_info, group_tp=tp_hcomm_info, ep_world_size=ep_world_size, tp_world_size=tp_world_size, ep_rank_id=rank // tp_world_size, tp_rank_id=rank % tp_world_size, expert_shard_type=0, shared_expert_rank_num=sharedExpertRankNum, moe_expert_num=moeExpertNum, scales=scales, quant_mode=quant_mode, global_bs=globalBS) if is_quant: expand_x = expand_x.to(input_dtype) x = torch_npu.npu_moe_distribute_combine(expand_x=expand_x, expert_ids=expert_ids, expand_idx=expand_idx, ep_send_counts=ep_recv_counts, tp_send_counts=tp_recv_counts, expert_scales=expert_scales, group_ep=ep_hcomm_info, group_tp=tp_hcomm_info, ep_world_size=ep_world_size, tp_world_size=tp_world_size, ep_rank_id=rank // tp_world_size, tp_rank_id=rank % tp_world_size, expert_shard_type=0, shared_expert_rank_num=sharedExpertRankNum, moe_expert_num=moeExpertNum, global_bs=globalBS) print(f'rank {rank} epid {rank // tp_world_size} tpid {rank % tp_world_size} npu finished! \n') if __name__ == "__main__": print(f"bs={bs}") print(f"global_bs={globalBS}") print(f"shared_expert_rank_num={sharedExpertRankNum}") print(f"moe_expert_num={moeExpertNum}") print(f"k={k}") print(f"quant_mode={quant_mode}", flush=True) print(f"local_moe_expert_num={local_moe_expert_num}", flush=True) print(f"tp_world_size={tp_world_size}", flush=True) print(f"ep_world_size={ep_world_size}", flush=True) if tp_world_size != 1 and local_moe_expert_num > 1: print("unSupported tp = 2 and local moe > 1") exit(0) if sharedExpertRankNum > ep_world_size: print("sharedExpertRankNum 不能大于 ep_world_size") exit(0) if sharedExpertRankNum > 0 and ep_world_size % sharedExpertRankNum != 0: print("ep_world_size 必须是 sharedExpertRankNum的整数倍") exit(0) if moeExpertNum % moe_rank_num != 0: print("moeExpertNum 必须是 moe_rank_num 的整数倍") exit(0) p_list = [] for rank in range(rank_per_dev): p = Process(target=run_npu_process, args=(rank,)) p_list.append(p) for p in p_list: p.start() for p in p_list: p.join() print("run npu success.")
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178
# 仅支持静态图 import os import torch import random import torch_npu import torchair import numpy as np from torch.multiprocessing import Process import torch.distributed as dist from torch.distributed import ReduceOp # 控制模式 quant_mode = 2 # 2为动态量化 is_dispatch_scales = True # 动态量化可选择是否传scales input_dtype = torch.bfloat16 # 输出dtype server_num = 1 server_index = 0 port = 50001 master_ip = '127.0.0.1' dev_num = 16 world_size = server_num * dev_num rank_per_dev = int(world_size / server_num) # 每个host有几个die sharedExpertRankNum = 2 # 共享专家数 moeExpertNum = 14 # moe专家数 bs = 8 # token数量 h = 7168 # 每个token的长度 k = 8 random_seed = 0 tp_world_size = 1 ep_world_size = int(world_size / tp_world_size) moe_rank_num = ep_world_size - sharedExpertRankNum local_moe_expert_num = moeExpertNum // moe_rank_num globalBS = bs * ep_world_size is_shared = (sharedExpertRankNum > 0) is_quant = (quant_mode > 0) class MOE_DISTRIBUTE_GRAPH_Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, x, expert_ids, group_ep, group_tp, ep_world_size, tp_world_size, ep_rank_id, tp_rank_id, expert_shard_type, shared_expert_rank_num, moe_expert_num, scales, quant_mode, global_bs, expert_scales): output_dispatch_npu = torch_npu.npu_moe_distribute_dispatch(x=x, expert_ids=expert_ids, group_ep=group_ep, group_tp=group_tp, ep_world_size=ep_world_size, tp_world_size=tp_world_size, ep_rank_id=ep_rank_id, tp_rank_id=tp_rank_id, expert_shard_type=expert_shard_type, shared_expert_rank_num=shared_expert_rank_num, moe_expert_num=moe_expert_num, scales=scales, quant_mode=quant_mode, global_bs=global_bs) expand_x_npu, _, expand_idx_npu, _, ep_recv_counts_npu, tp_recv_counts_npu, expand_scales = output_dispatch_npu if expand_x_npu.dtype == torch.int8: expand_x_npu = expand_x_npu.to(input_dtype) output_combine_npu = torch_npu.npu_moe_distribute_combine(expand_x=expand_x_npu, expert_ids=expert_ids, expand_idx=expand_idx_npu, ep_send_counts=ep_recv_counts_npu, tp_send_counts=tp_recv_counts_npu, expert_scales=expert_scales, group_ep=group_ep, group_tp=group_tp, ep_world_size=ep_world_size, tp_world_size=tp_world_size, ep_rank_id=ep_rank_id, tp_rank_id=tp_rank_id, expert_shard_type=expert_shard_type, shared_expert_rank_num=shared_expert_rank_num, moe_expert_num=moe_expert_num, global_bs=global_bs) x = output_combine_npu x_combine_res = output_combine_npu return [x_combine_res, output_combine_npu] def gen_unique_topk_array(low, high, bs, k): array = [] for i in range(bs): top_idx = list(np.arange(low, high, dtype=np.int32)) random.shuffle(top_idx) array.append(top_idx[0:k]) return np.array(array) def get_new_group(rank): for i in range(tp_world_size): ep_ranks = [x * tp_world_size + i for x in range(ep_world_size)] ep_group = dist.new_group(backend="hccl", ranks=ep_ranks) if rank in ep_ranks: ep_group_t = ep_group print(f"rank:{rank} ep_ranks:{ep_ranks}") for i in range(ep_world_size): tp_ranks = [x + tp_world_size * i for x in range(tp_world_size)] tp_group = dist.new_group(backend="hccl", ranks=tp_ranks) if rank in tp_ranks: tp_group_t = tp_group print(f"rank:{rank} tp_ranks:{tp_ranks}") return ep_group_t, tp_group_t def get_hcomm_info(rank, comm_group): if torch.__version__ > '2.0.1': hcomm_info = comm_group._get_backend(torch.device("npu")).get_hccl_comm_name(rank) else: hcomm_info = comm_group.get_hccl_comm_name(rank) return hcomm_info def run_npu_process(rank): torch_npu.npu.set_device(rank) rank = rank + 16 * server_index dist.init_process_group(backend='hccl', rank=rank, world_size=world_size, init_method=f'tcp://{master_ip}:{port}') ep_group, tp_group = get_new_group(rank) ep_hcomm_info = get_hcomm_info(rank, ep_group) tp_hcomm_info = get_hcomm_info(rank, tp_group) # 创建输入tensor x = torch.randn(bs, h, dtype=input_dtype).npu() expert_ids = gen_unique_topk_array(0, moeExpertNum, bs, k).astype(np.int32) expert_ids = torch.from_numpy(expert_ids).npu() expert_scales = torch.randn(bs, k, dtype=torch.float32).npu() scales_shape = (1 + moeExpertNum, h) if sharedExpertRankNum else (moeExpertNum, h) if is_dispatch_scales: scales = torch.randn(scales_shape, dtype=torch.float32).npu() else: scales = None model = MOE_DISTRIBUTE_GRAPH_Model() model = model.npu() npu_backend = torchair.get_npu_backend() model = torch.compile(model, backend=npu_backend, dynamic=False) output = model.forward(x, expert_ids, ep_hcomm_info, tp_hcomm_info, ep_world_size, tp_world_size, rank // tp_world_size,rank % tp_world_size, 0, sharedExpertRankNum, moeExpertNum, scales, quant_mode, globalBS, expert_scales) torch.npu.synchronize() print(f'rank {rank} epid {rank // tp_world_size} tpid {rank % tp_world_size} npu finished! \n') if __name__ == "__main__": print(f"bs={bs}") print(f"global_bs={globalBS}") print(f"shared_expert_rank_num={sharedExpertRankNum}") print(f"moe_expert_num={moeExpertNum}") print(f"k={k}") print(f"quant_mode={quant_mode}", flush=True) print(f"local_moe_expert_num={local_moe_expert_num}", flush=True) print(f"tp_world_size={tp_world_size}", flush=True) print(f"ep_world_size={ep_world_size}", flush=True) if tp_world_size != 1 and local_moe_expert_num > 1: print("unSupported tp = 2 and local moe > 1") exit(0) if sharedExpertRankNum > ep_world_size: print("sharedExpertRankNum 不能大于 ep_world_size") exit(0) if sharedExpertRankNum > 0 and ep_world_size % sharedExpertRankNum != 0: print("ep_world_size 必须是 sharedExpertRankNum的整数倍") exit(0) if moeExpertNum % moe_rank_num != 0: print("moeExpertNum 必须是 moe_rank_num 的整数倍") exit(0) p_list = [] for rank in range(rank_per_dev): p = Process(target=run_npu_process, args=(rank,)) p_list.append(p) for p in p_list: p.start() for p in p_list: p.join() print("run npu success.")
父主题: torch_npu