torch_npu.npu_mla_prolog
功能描述
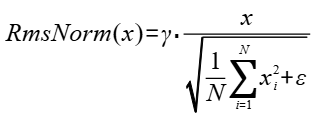
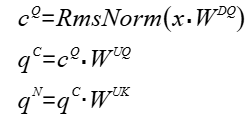
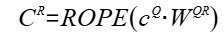
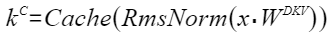
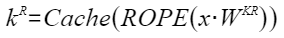
接口原型
torch_npu.npu_mla_prolog(Tensor token_x, Tensor weight_dq, Tensor weight_uq_qr, Tensor weight_uk, Tensor weight_dkv_kr, Tensor rmsnorm_gamma_cq, Tensor rmsnorm_gamma_ckv, Tensor rope_sin, Tensor rope_cos, Tensor cache_index, Tensor kv_cache, Tensor kr_cache, *, Tensor? dequant_scale_x=None, Tensor? dequant_scale_w_dq=None, Tensor? dequant_scale_w_uq_qr=None, Tensor? dequant_scale_w_dkv_kr=None, Tensor? quant_scale_ckv=None, Tensor? quant_scale_ckr=None, Tensor? smooth_scales_cq=None, float rmsnorm_epsilon_cq=1e-05, float rmsnorm_epsilon_ckv=1e-05, str cache_mode="PA_BSND") -> (Tensor, Tensor, Tensor, Tensor)
参数说明

shape格式字段含义:
- B:Batch表示输入样本批量大小,取值范围为1~65536。
- S:Seq-Length 表示输入样本序列长度,取值范围为1~16。
- He:Head-Size 表示隐藏层的大小,取值为7168。
- Hcq:q低秩矩阵维度,取值为1536。
- N:Head-Num 表示多头数,取值范围为32、64、128。
- Hckv:kv低秩矩阵维度,取值为512。
- D:qk不含位置编码维度,取值为128。
- Dr:qk位置编码维度,取值为64。
- Nkv:kv的head数,取值为1。
- BlockNum:PagedAttention场景下的块数,取值为计算B*Skv/BlockSize的值后再向上取整,其中Skv表示kv的序列长度。
- BlockSize:PagedAttention场景下的块大小,取值范围为16、128。
- token_x:Tensor类型,对应公式中x。shape支持3维,格式为(B,S,He),dtype支持bfloat16,数据格式支持ND。
- weight_dq:Tensor类型,表示计算Query的下采样权重矩阵,即公式中WDQ。shape支持2维,格式为(He,Hcq),dtype支持bfloat16,数据格式支持FRACTAL_NZ(可通过torch_npu.npu_format_cast将ND格式转为FRACTAL_NZ格式)。
- weight_uq_qr:Tensor类型,表示计算Query的上采样权重矩阵和Query的位置编码权重矩阵,即公式中WUQ和WQR。shape支持2维,格式为(Hcq,N*(D+Dr)),dtype支持bfloat16,数据格式支持FRACTAL_NZ。
- weight_uk:Tensor类型,表示计算Key的上采样权重,即公式中WUK。shape支持3维,格式为(N,D,Hckv),dtype支持bfloat16,数据格式支持ND。
- weight_dkv_kr:Tensor类型,表示计算Key的下采样权重矩阵和Key的位置编码权重矩阵,即公式中WDKV和WKR。shape支持2维,格式为(He,Hckv+Dr),dtype支持bfloat16,数据格式支持FRACTAL_NZ。
- rmsnorm_gamma_cq:Tensor类型,表示计算cQ的RmsNorm公式中的γ参数。shape支持1维,格式为(Hcq),dtype支持bfloat16,数据格式支持ND。
- rmsnorm_gamma_ckv:Tensor类型,表示计算cKV的RmsNorm公式中的γ参数。shape支持1维,格式为(Hckv),dtype支持bfloat16,数据格式支持ND。
- rope_sin:Tensor类型,表示用于计算旋转位置编码的正弦参数矩阵。shape支持3维,格式为(B,S,Dr),dtype支持bfloat16,数据格式支持ND。
- rope_cos:Tensor类型,表示用于计算旋转位置编码的余弦参数矩阵。shape支持3维,格式为(B,S,Dr),dtype支持bfloat16,数据格式支持ND。
- cache_index:Tensor类型,表示用于存储kv_cache和kr_cache的索引。shape支持2维,格式为(B,S),dtype支持int64,数据格式支持ND。
- kv_cache:Tensor类型,表示用于cache索引的aclTensor。shape支持4维,格式为(BlockNum, BlockSize, Nkv, Hckv),dtype支持bfloat16,数据格式支持ND。
- kr_cache:Tensor类型,表示用于key位置编码的cache。shape支持4维,格式为(BlockNum, BlockSize, Nkv, Dr),dtype支持bfloat16,数据格式支持ND。
- dequant_scale_x:Tensor类型,预留参数,暂未使用,使用默认值即可。
- dequant_scale_w_dq:Tensor类型,预留参数,暂未使用,使用默认值即可。
- dequant_scale_w_uq_qr:Tensor类型,预留参数,暂未使用,使用默认值即可。
- dequant_scale_w_dkv_kr:Tensor类型,预留参数,暂未使用,使用默认值即可。
- quant_scale_ckv:Tensor类型,预留参数,暂未使用,使用默认值即可。
- quant_scale_ckr:Tensor类型,预留参数,暂未使用,使用默认值即可。
- smooth_scales_cq:Tensor类型,预留参数,暂未使用,使用默认值即可。
- rmsnorm_epsilon_cq:Double类型,表示计算cQ的RmsNorm公式中的ε参数,用户不特意指定时可传入默认值1e-05。
- rmsnorm_epsilon_ckv:Double类型,表示计算cKV的RmsNorm公式中的ε参数,用户不特意指定时可传入默认值1e-05。
- cache_mode:String类型,表示kvCache的模式,支持"PA_BSND"、"PA_NZ",其用户不特意指定时可传入默认值“PA_BSND”。
输出说明
- query:Tensor类型,表示Query的输出Tensor,即公式中qN。shape支持4维,格式为(B, S, N, Hckv),dtype支持bfloat16,数据格式支持ND。
- query_rope:Tensor类型,表示Query位置编码的输出Tensor,即公式中qR。shape支持4维,格式为(B, S, N, Dr),dtype支持bfloat16,数据格式支持ND。
- kv_cache_out:Tensor类型,表示Key输出到kvCache中的Tensor,即公式中kC。shape支持4维,格式为(BlockNum, BlockSize, Nkv, Hckv),dtype支持bfloat16,数据格式支持ND。
- kr_cache_out:Tensor类型,表示Key的位置编码输出到kvCache中的Tensor,即公式中kR。shape支持4维,格式为(BlockNum, BlockSize, Nkv, Dr),dtype支持bfloat16,数据格式支持ND。
约束说明
- 该接口仅在推理场景下使用。
- 该接口支持图模式(目前仅支持PyTorch 2.1版本)。
支持的型号
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
import torch import torch_npu import math # 生成随机数据, 并发送到npu B = 8 He = 7168 Hcq = 1536 Hckv = 512 N = 32 D = 128 Dr = 64 Skv = 1024 S = 2 Nkv = 1 BlockSize = 128 BlockNum = 64 token_x = torch.rand(B, S, He, dtype=torch.bfloat16).npu() w_dq = torch.rand(He, Hcq, dtype=torch.bfloat16).npu() w_dq_cast = torch_npu.npu_format_cast(w_dq.contiguous(), 29) w_uq_qr = torch.rand(Hcq, N * (D + Dr), dtype=torch.bfloat16).npu() w_uq_qr_cast = torch_npu.npu_format_cast(w_uq_qr.contiguous(), 29) w_uk = torch.rand(N, D, Hckv, dtype=torch.bfloat16).npu() w_dkv_kr = torch.rand(He, Hckv + Dr, dtype=torch.bfloat16).npu() w_dkv_kr_cast = torch_npu.npu_format_cast(w_dkv_kr.contiguous(), 29) rmsnorm_gamma_cq = torch.rand(Hcq, dtype=torch.bfloat16).npu() rmsnorm_gamma_ckv = torch.rand(Hckv, dtype=torch.bfloat16).npu() rope_sin = torch.rand(B, S, Dr, dtype=torch.bfloat16).npu() rope_cos = torch.rand(B, S, Dr, dtype=torch.bfloat16).npu() cache_index = torch.rand(B, S).to(torch.int64).npu() kv_cache = torch.rand(BlockNum, BlockSize, Nkv, Hckv, dtype=torch.bfloat16).npu() kr_cache = torch.rand(BlockNum, BlockSize, Nkv, Dr, dtype=torch.bfloat16).npu() rmsnorm_epsilon_cq = 1.0e-5 rmsnorm_epsilon_ckv = 1.0e-5 cache_mode = "PA_BSND" # 调用MlaProlog算子 query_mla, query_rope_mla, kv_cache_out_mla, kr_cache_out_mla = torch_npu.npu_mla_prolog(token_x, w_dq_cast, w_uq_qr_cast, w_uk, w_dkv_kr_cast, rmsnorm_gamma_cq, rmsnorm_gamma_ckv, rope_sin, rope_cos, cache_index, kv_cache, kr_cache, rmsnorm_epsilon_cq=rmsnorm_epsilon_cq, rmsnorm_epsilon_ckv=rmsnorm_epsilon_ckv, cache_mode=cache_mode) # 执行上述代码的输出out类似如下 tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140], [ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117], [ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062], .. [ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039], [ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164], [ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]], device='npu:0', dtype=torch.bfloat16)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86
# 入图方式 import torch import torch_npu import math import torchair as tng from torchair.configs.compiler_config import CompilerConfig import torch._dynamo TORCHDYNAMO_VERBOSE=1 TORCH_LOGS="+dynamo" # 支持入图的打印宏 import logging from torchair.core.utils import logger logger.setLevel(logging.DEBUG) config = CompilerConfig() config.debug.graph_dump.type = "pbtxt" npu_backend = tng.get_npu_backend(compiler_config=config) from torch.library import Library, impl # 数据生成 B = 8 He = 7168 Hcq = 1536 Hckv = 512 N = 32 D = 128 Dr = 64 Skv = 1024 S = 2 Nkv = 1 BlockSize = 128 BlockNum = 64 token_x = torch.rand(B, S, He, dtype=torch.bfloat16).npu() w_dq = torch.rand(He, Hcq, dtype=torch.bfloat16).npu() w_dq_cast = torch_npu.npu_format_cast(w_dq.contiguous(), 29) w_uq_qr = torch.rand(Hcq, N * (D + Dr), dtype=torch.bfloat16).npu() w_uq_qr_cast = torch_npu.npu_format_cast(w_uq_qr.contiguous(), 29) w_uk = torch.rand(N, D, Hckv, dtype=torch.bfloat16).npu() w_dkv_kr = torch.rand(He, Hckv + Dr, dtype=torch.bfloat16).npu() w_dkv_kr_cast = torch_npu.npu_format_cast(w_dkv_kr.contiguous(), 29) rmsnorm_gamma_cq = torch.rand(Hcq, dtype=torch.bfloat16).npu() rmsnorm_gamma_ckv = torch.rand(Hckv, dtype=torch.bfloat16).npu() rope_sin = torch.rand(B, S, Dr, dtype=torch.bfloat16).npu() rope_cos = torch.rand(B, S, Dr, dtype=torch.bfloat16).npu() cache_index = torch.rand(B, S).to(torch.int64).npu() kv_cache = torch.rand(BlockNum, BlockSize, Nkv, Hckv, dtype=torch.bfloat16).npu() kr_cache = torch.rand(BlockNum, BlockSize, Nkv, Dr, dtype=torch.bfloat16).npu() rmsnorm_epsilon_cq = 1.0e-5 rmsnorm_epsilon_ckv = 1.0e-5 cache_mode = "PA_BSND" class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self): return torch_npu.npu_mla_prolog(token_x, w_dq_cast, w_uq_qr_cast, w_uk, w_dkv_kr_cast, rmsnorm_gamma_cq,rmsnorm_gamma_ckv, rope_sin, rope_cos, cache_index, kv_cache, kr_cache, rmsnorm_epsilon_cq=rmsnorm_epsilon_cq, rmsnorm_epsilon_ckv=rmsnorm_epsilon_ckv, cache_mode=cache_mode) def MetaInfershape(): with torch.no_grad(): model = Model() model = torch.compile(model, backend=npu_backend, dynamic=False, fullgraph=True) graph_output = model() query_mla, query_rope_mla, kv_cache_out_mla, kr_cache_out_mla = torch_npu.npu_mla_prolog(token_x, w_dq_cast, w_uq_qr_cast, w_uk, w_dkv_kr_cast, rmsnorm_gamma_cq,rmsnorm_gamma_ckv, rope_sin, rope_cos, cache_index, kv_cache, kr_cache, rmsnorm_epsilon_cq=rmsnorm_epsilon_cq, rmsnorm_epsilon_ckv=rmsnorm_epsilon_ckv, cache_mode=cache_mode) print("single op output:", query_mla) print("graph output:", graph_output) if __name__ == "__main__": MetaInfershape() # 执行上述代码的输出类似如下 single op output with mask: tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140], [ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117], [ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062], ..., [ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039], [ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164], [ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]], device='npu:0', dtype=torch.bfloat16) graph output with mask: tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140], [ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117], [ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062], ..., [ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039], [ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164], [ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]], device='npu:0', dtype=torch.bfloat16)
父主题: torch_npu