torch_npu.npu_dynamic_quant
功能描述
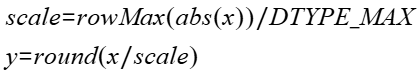
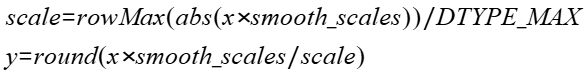
接口原型
torch_npu.npu_dynamic_quant(Tensor x, *, Tensor? smooth_scales=None, Tensor? group_index=None, ScalarType? dst_type=None) ->(Tensor, Tensor)
参数说明
- x:Tensor类型,需要进行量化的源数据张量,必选输入,数据类型支持float16、bfloat16,数据格式支持ND,支持非连续的Tensor。输入x的维度必须大于1。进行int4量化时,要求x形状的最后一维是8的整数倍。
- smooth_scales:Tensor类型,对x进行scales的张量,可选输入,数据类型支持float16、bfloat16,数据格式支持ND,支持非连续的Tensor。shape必须是1维,和x的最后一维相等。
- 单算子模式:smooth_scales的dtype必须和x保持一致。
- group_index:Tensor类型,对smooth_scales进行分组的下标,可选输入,仅在MoE场景下生效。数据类型支持int32,数据格式支持ND,支持非连续的Tensor。
- dst_type:ScalarType类型,指定量化输出的类型,可选输入,传None时当做torch.int8处理。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 :支持取值torch.int8、torch.quint4x2。Atlas A3 训练系列产品/Atlas A3 推理系列产品 :支持取值torch.int8、torch.quint4x2。
输出说明
- y:量化后的输出Tensor,数据类型由dst_type指定。当dst_type是torch.quint4x2时,y的数据类型为int32,形状最后一维为x最后一维除以8,其余维度与x一致,每个int32元素包含8个int4结果。其他场景下y形状与输入x一致,数据类型由dst_type指定。
- scale:Tensor类型,非对称动态量化过程中计算出的缩放系数,数据类型为float32,形状为x的形状剔除最后一维。
约束说明
- 该接口仅在推理场景下使用。
- 该接口支持图模式(目前仅支持PyTorch 2.1版本)。
- 该接口仅在如下产品支持MoE场景。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 Atlas A3 训练系列产品/Atlas A3 推理系列产品
- 使用smooth_scales时:
- 若不使用group_index,smooth_scales必须是一维Tensor,元素数量与x的最后一维大小一致。
- 若使用group_index,smooth_scales必须是二维Tensor,第二维元素数量与x的最后一维大小一致,group_index必须是一维数组,元素数量与smooth_scales第一维一致。group_index中的元素必须是单调递增的,其最后一个元素的值,应等于x的元素数量除以x的最后一个维度。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
- 只有一个输入x
1 2 3 4 5 6 7
import torch import torch_npu x = torch.rand((3, 3), dtype = torch.float16).to("npu") output, scale = torch_npu.npu_dynamic_quant(x) print(output) print(scale)
- 使用smooth_scales输入
1 2 3 4 5 6 7 8
import torch import torch_npu x = torch.rand((3, 3), dtype = torch.float16).to("npu") smooth_scales = torch.rand((3,), dtype = torch.float16).to("npu") output, scale = torch_npu.npu_dynamic_quant(x, smooth_scales=smooth_scales) print(output) print(scale)
- 只有一个输入x
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
import torch import torch_npu import torchair as tng from torchair.configs.compiler_config import CompilerConfig torch_npu.npu.set_compile_mode(jit_compile=True) config = CompilerConfig() npu_backend = tng.get_npu_backend(compiler_config=config) device=torch.device(f'npu:0') torch_npu.npu.set_device(device) class DynamicQuantModel(torch.nn.Module): def __init__(self): super().__init__() def forward(self, input_tensor, smooth_scales=None, group_index=None, dst_type=None): out, scale = torch_npu.npu_dynamic_quant(input_tensor, smooth_scales=smooth_scales, group_index=group_index, dst_type=dst_type) return out, scale x = torch.randn((2, 4, 6),device='npu',dtype=torch.float16).npu() smooth_scales = torch.randn((6),device='npu',dtype=torch.float16).npu() dynamic_quant_model = DynamicQuantModel().npu() dynamic_quant_model = torch.compile(dynamic_quant_model, backend=npu_backend, dynamic=True) out, scale = dynamic_quant_model(x, smooth_scales=smooth_scales) print(out) print(scale)
父主题: torch_npu