PETR模型多节点性能下降分析
问题现象
Stream PETR模型,DP Size为8, 在节点数量提高后,多任务训练耗时均匀变慢,如表1所示。
分析定位
- 初步分析
- 单节点内性能劣化问题,从单步时间看,单节点劣化的核心原因是SyncBatchNormBackwardElemt带来算子耗时劣化。
- 单节点到多节点存在性能劣化问题。
- 根因解析
- 1节点到5节点性能明显劣化的原因(从上至下,重要性递减)
- 1节点性能问题的原因(从上至下,重要性递减)
- 总差距为390ms,算子耗时差距占了240ms。
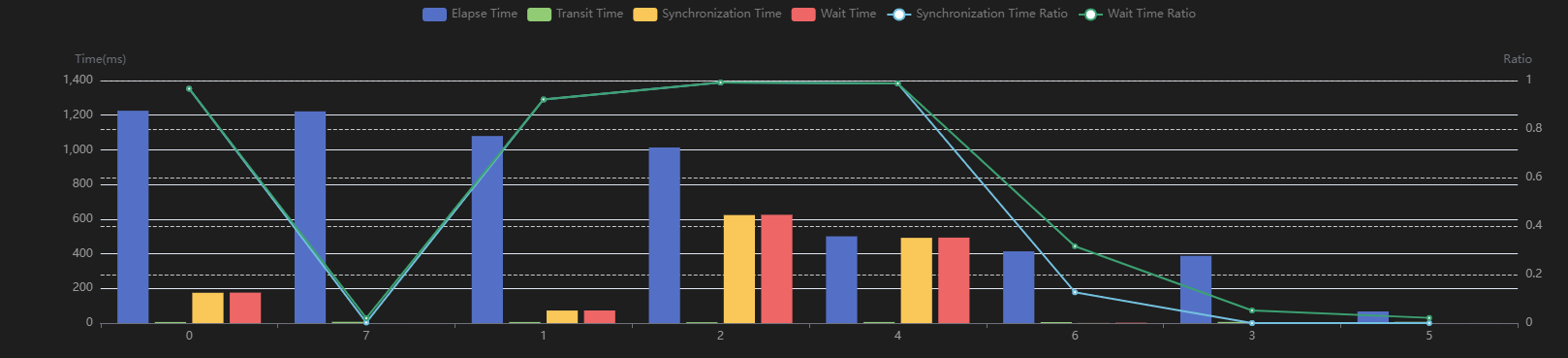
- 模型原本就存在严重的快慢卡问题,syncbn的大量同步导致了大量同步等待时延。
不加syncbn的不同卡Elapse Time示意图,如图1所示。
- 快慢卡原因分析
- 差距从Python CPU侧开始,随着API的调用,差距慢慢拉大,造成影响的API为aten。
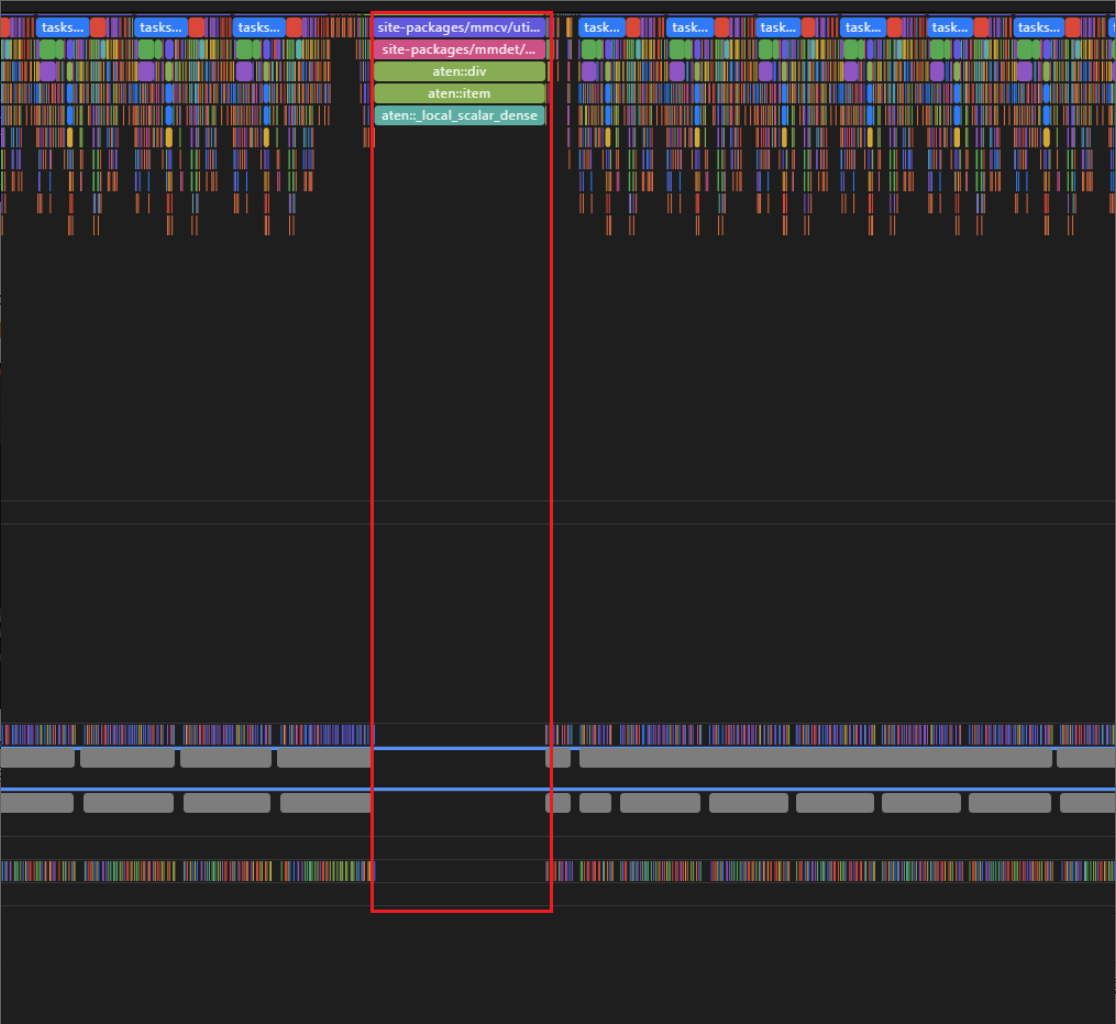
- Python侧存在轮空现象,如图2所示,与之前某些用户存在的现象类似,疑似CPU资源被抢占。
产生这一空隙之前的算子是“site-packages/mmdet/models/losses/utils.py(29): weight_reduce_loss”29行,算子为aclnnReduceSum。
- 不同卡的batmatmulv2耗时差距巨大,从170ms到240ms波动。
优化方案
20节点的共网任务,截止到目前的syncbn优化措施,单步时延已从5.693s优化到3.866s,优化效果明显。
表2为具体的优化措施,请用户根据实际情况来选择优化。
|
优化类型 |
分析 |
优化措施 |
实验结果 |
|---|---|---|---|
|
算子优化 |
syncbn基于torch原生代码,为使能路径3,加入过patch;若去掉patch,在当前版本上会走到路径5。 |
去掉syncbn上为NPU适配的patch |
|
|
消除transdata。 |
torch_npu.config.allow_internal_format = False |
2.55s -> 2.53s |
|
|
模型优化 |
资源抢占问题。 |
建议关闭gc |
5节点,2.68s -> 2.6s |
|
小算子太多,下发频繁,性能不好。当前numa为8,需要额外尝试绑核。 |
绑核 |
5节点,2.6s -> 2.555s |
|
|
融合优化器。 |
使能融合优化器 |
2.53s -> 2.49s |
父主题: 典型案例分析