MatmulAllReduce
算子基础信息
算子IR及torch_npu接口参数
算子IR:
REG_OP(MatmulAllReduce)
.INPUT(x1, TensorType({DT_FLOAT16, DT_BF16, DT_INT8}))
.INPUT(x2, TensorType({DT_FLOAT16, DT_BF16, DT_INT8, DT_INT4}))
.OPTIONAL_INPUT(bias, TensorType({DT_FLOAT16, DT_BF16, DT_INT32}))
.OPTIONAL_INPUT(x3, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(antiquant_scale, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(antiquant_offset, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(dequant_scale, TensorType({DT_FLOAT16, DT_BF16, DT_UINT64, DT_INT64, DT_FLOAT}))
.OPTIONAL_INPUT(pertoken_scale, TensorType({DT_FLOAT}))
.OUTPUT(y, TensorType({DT_FLOAT16, DT_BF16}))
.REQUIRED_ATTR(group, String)
.ATTR(reduce_op, String, "sum")
.ATTR(is_trans_a, Bool, false)
.ATTR(is_trans_b, Bool, false)
.ATTR(comm_turn, Int, 0)
.ATTR(antiquant_group_size, Int, 0)
.OP_END_FACTORY_REG(MatmulAllReduce)
torch_npu接口:
npu_mm_all_reduce_base(Tensor x1, Tensor x2, str hcom, *, str reduce_op='sum', Tensor? bias=None, Tensor? antiquant_scale=None, Tensor? antiquant_offset=None, Tensor? x3=None, Tensor? dequant_scale=None, Tensor? pertoken_scale=None, int comm_turn=0, int antiquant_group_size=0) -> Tensor

torch_npu接口中的问号表示这个输入参数是可选的。
参数说明、输出说明和约束说明具体请参考《API 参考》中的“torch_npu.npu_mm_all_reduce_base”章节。
模型中替换代码及算子计算逻辑
模型中替换代码:
import torch.distributed as dist
world_size = 8
rank = 8
master_ip = '127.0.0.1'
master_port = '50001'
m = 64
k = 512
n = 128
input_shape = [m,k]
weight_shape = [k,n]
torch_npu.npu.set_device(rank)
init_method = 'tcp://'
init_method += master_ip + ':' + master_port
dist.init_process_group(backend="hccl", rank=rank, world_size=world_size, init_method=init_method)
if dist.is_available():
from torch.distributed.distributed_c10d import _get_default_group, ReduceOp
default_pg = _get_default_group()
world_size = torch.distributed.get_world_size(default_pg)
if torch.__version__ > '2.0.1':
hcomm_info = default_pg._get_backend(torch.device("npu")).get_hccl_comm_name(rank)
else:
hcomm_info = default_pg.get_hccl_comm_name(rank)
weight = torch.randn(weight_shape, dtype=dtype).npu()
input = torch.randn(input_shape, dtype=dtype).npu()
output = torch.matmul(input, weight)
dist.all_reduce(output,op=ReduceOp.SUM)
其中output替换为:
output = torch_npu.npu_mm_all_reduce_base(input, weight, hcomm_info, reduce_op="sum", comm_turn=0)
算子替换的模型中小算子
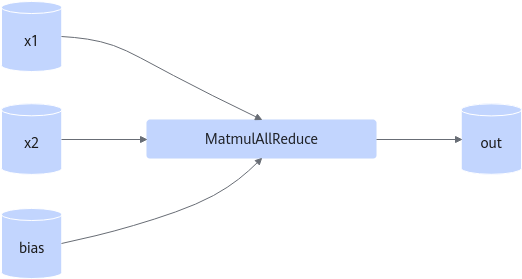
MatMul/hcom_allReduce
图1 计算图
使用限制
当前仅支持Atlas A2 训练系列产品TP切分场景
已支持模型典型case
GPT3 65B
- case 1:
x1: S = 1 ~ 8192,{S,1024}, BF16/FP16
x2: {1024,8192}, BF16/FP16
bias: {8192}
- case 2:
x1: S = 1 ~ 8192,{S,2732}, BF16/FP16
x2: {2732,8192}, BF16/FP16
bias: {8192}
- case 3:
x1: B = 1 ~ 24,{B,1024}, BF16/FP16
x2: {1024,8192}, BF16/FP16
bias: {8192}
- case 4:
x1: B = 1 ~ 24,{B,2732}, BF16/FP16
x2: {2732,8192}, BF16/FP16
bias: {8192}
父主题: 融合算子替换