RmsNorm & RmsNormGrad
算子基础信息
|
算子名称 |
RmsNorm & RmsNormGrad |
|---|---|
|
torch_npu api接口 |
torch_npu.npu_rms_norm(x, gamma, epsilon) |
|
支持的torch_npu版本 |
1.11.0, 2.1.0, 2.2.0 |
|
支持的芯片类型 |
Atlas A2 训练系列产品 |
|
支持的数据类型 |
float16, bfloat16, float |
算子IR及torch_npu接口参数
算子IR:
REG_OP(RmsNorm)
.INPUT(x, TensorType({DT_FLOAT, DT_FLOAT16, DT_BF16}))
.INPUT(gamma, TensorType({DT_FLOAT, DT_FLOAT16, DT_BF16}))
.OUTPUT(y, TensorType({DT_FLOAT, DT_FLOAT16, DT_BF16}))
.OUTPUT(rstd, TensorType({DT_FLOAT, DT_FLOAT, DT_FLOAT}))
.ATTR(epsilon, Float, 1e-6)
.OP_END_FACTORY_REG(RmsNorm)
torch_npu接口:
torch_npu.npu_rms_norm(Tensor self, Tensor gamma, float epsilon=1e-06) -> (Tensor, Tensor)
参数说明:
- x:Tensor类型,shape支持1-8维。
- gamma:Tensor类型,通常为weight,shape要求与x的后几维保持一致。
- epsilon:float数据类型,用于防止除0错误。
输出说明:
- 第1个输出为Tensor,计算公式的最终输出y。
- 第2个输出为Tensor,rms_norm的中间结果rstd,用于反向计算。
模型中替换代码及算子计算逻辑
RmsNorm算子常见于LLaMA、LLaMA2、Baichuan等LLM模型中,由于torch侧没有提供RmsNorm算子的接口,因此在模型中通常是以自定义类的形式出现,在forward函数下定义计算逻辑,例如:
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
"""
Initialize the RMSNorm normalization layer.
Args:
dim (int): The dimension of the input tensor.
eps (float, optional): A small value added to the denominator for numerical stability. Default is 1e-6.
Attributes:
eps (float): A small value added to the denominator for numerical stability.
weight (nn.Parameter): Learnable scaling parameter.
"""
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
"""
Apply the RMSNorm normalization to the input tensor.
Args:
x (torch.Tensor): The input tensor.
Returns:
torch.Tensor: The normalized tensor.
"""
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
"""
Forward pass through the RMSNorm layer.
Args:
x (torch.Tensor): The input tensor.
Returns:
torch.Tensor: The output tensor after applying RMSNorm.
"""
output = self._norm(x.float()).type_as(x)
return output * self.weight
替换为:
import torch_npu
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
"""
Initialize the RMSNorm normalization layer.
Args:
dim (int): The dimension of the input tensor.
eps (float, optional): A small value added to the denominator for numerical stability. Default is 1e-6.
Attributes:
eps (float): A small value added to the denominator for numerical stability.
weight (nn.Parameter): Learnable scaling parameter.
"""
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x):
"""
Forward pass through the RMSNorm layer.
Args:
x (torch.Tensor): The input tensor.
Returns:
torch.Tensor: The output tensor after applying RMSNorm.
"""
return torch_npu.npu_rms_norm(x, self.weight, epsilon=self.eps)[0]
图1 计算流程
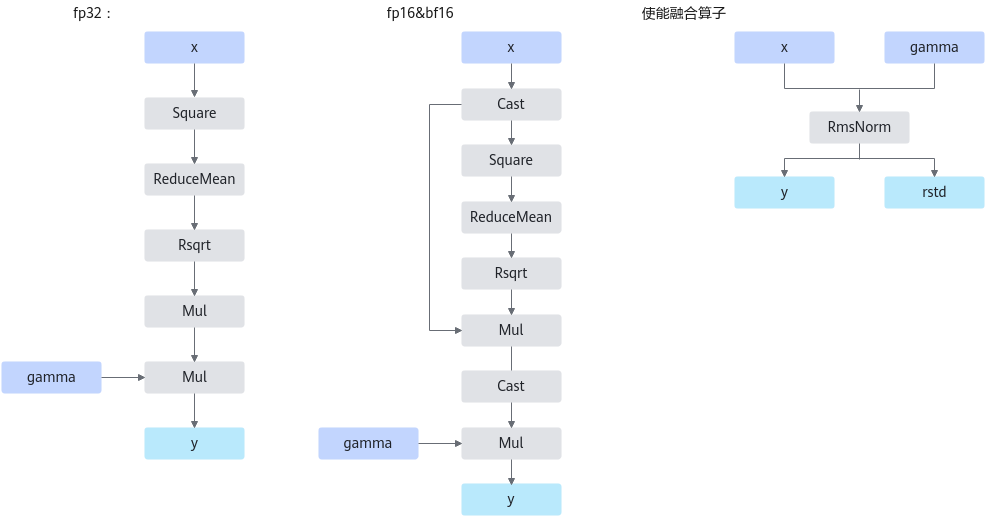
融合后多了一个输出rstd,为计算中间结果,对应torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) ,用于反向算子输入。
算子替换的模型中小算子

使用限制
Atlas A2 训练系列产品支持全泛化case,Atlas 推理系列产品当前仅支持gamma shape大于等于32byte。
父主题: 融合算子替换