权重更新通信隐藏
问题分析
在大规模模型的训练过程中,数据并行策略被普遍采用。在梯度更新阶段,传统方法要求数据并行组内的通信操作必须在反向传播计算完全结束后才启动,这种串行执行模式导致计算与通信流程中存在明显的空闲等待期,从而降低了整体执行效率。
解决方案
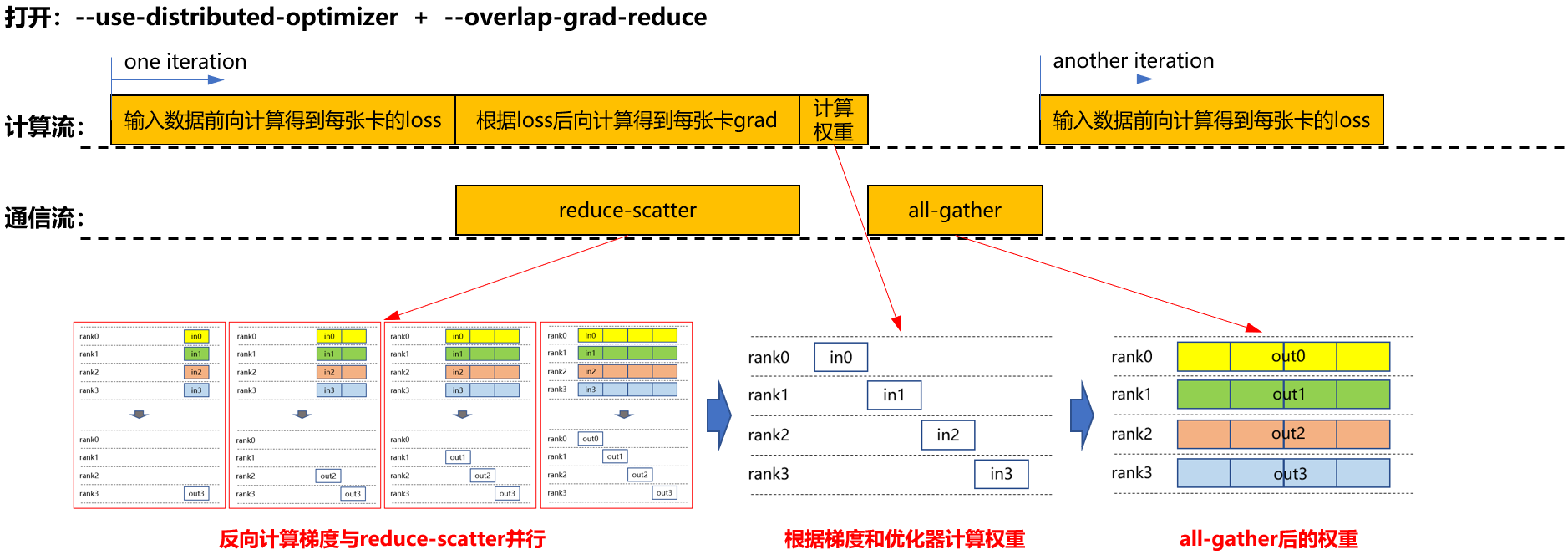
为解决上述问题,引入了计算与通信任务的并行执行策略,通过流水线技术来实现计算与通信的流水掩盖,有效提升资源利用率。
- 仅启用分布式优化器(--use-distributed-optimizer)
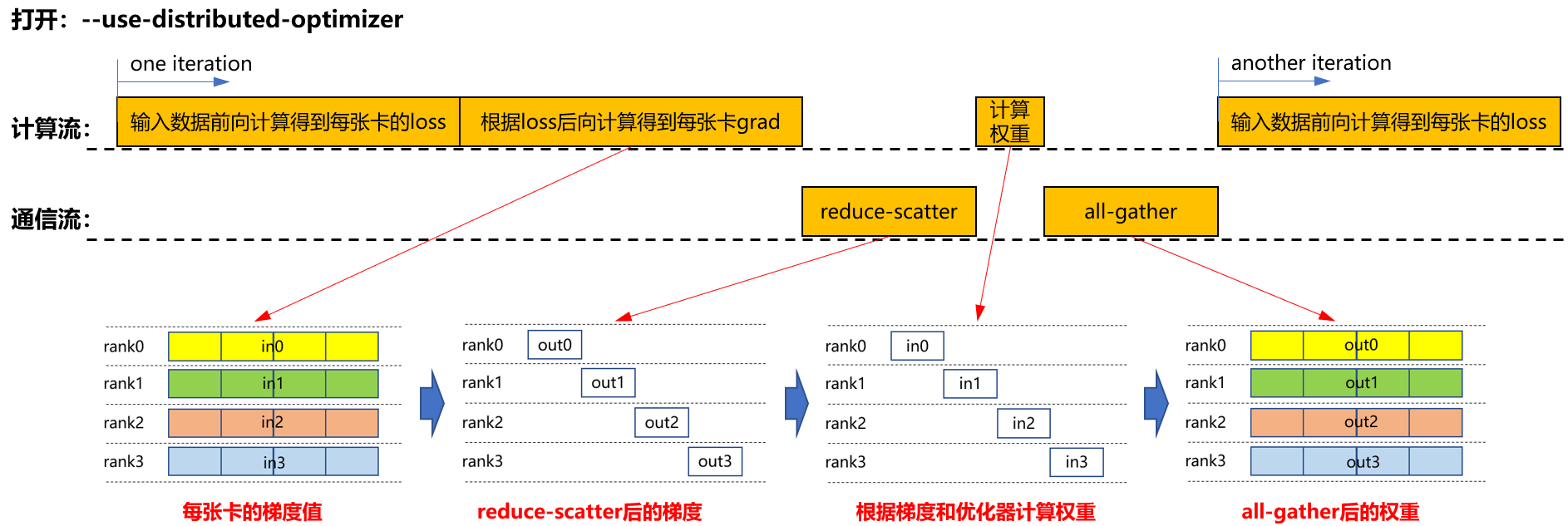
- 同时启用分布式优化器与梯度通信重叠(--overlap-grad-reduce)
- 启用分布式优化器、梯度通信重叠、参数聚合重叠(--overlap-param-gather)
在上述基础(启用分布式优化器与梯度通信重叠)上,进一步启用参数聚合重叠,训练流程如图所示。all-gather 操作与下一轮的前向计算并行执行,从而避免了独立的 all-gather 时间段。图3 启用分布式优化器、梯度通信重叠、聚集重叠参数时的计算流和通信流
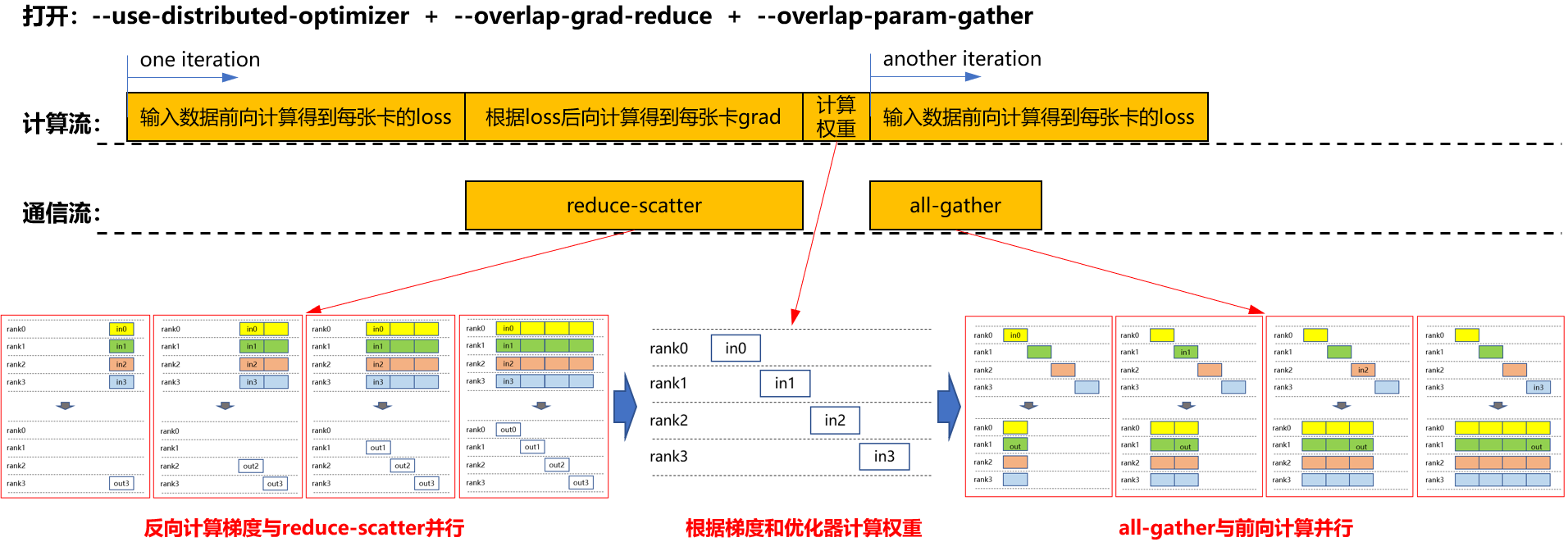
通过对比不同流程,可以观察到在启用--overlap-param-gather后,计算与通信完全并行,极大地提高了计算与通信的并行效率,从而显著提升了模型训练的效率。
使用场景
在采用数据并行策略的训练场景下,推荐启用此特性。
使用方法
- 要启用权重更新通信隐藏功能,需在训练配置中加入以下参数
--overlap-param-gather
- 确保同时开启了以下两个参数。
--use-distirbuted-optimizer --overlap-grad-reduce
父主题: 通信性能优化