TP重计算通信优化
问题分析
在众多大规模模型训练实践中,结合使用重计算(Recomputation)与张量并行(Tensor Parallelism,TP)已成为标配策略。尽管重计算能显著降低内存消耗,却引入了额外的TP维度通信开销,导致TP维度通信耗时增长50%,整体计算时间增加约30%-40%。
解决方案
针对上述挑战,我们设计了一套综合通信优化方案,旨在消除不必要的通信算子,优化重计算层划分,进而显著提升大规模模型训练的通信性能。
解决思路
- 重计算通信算子消除
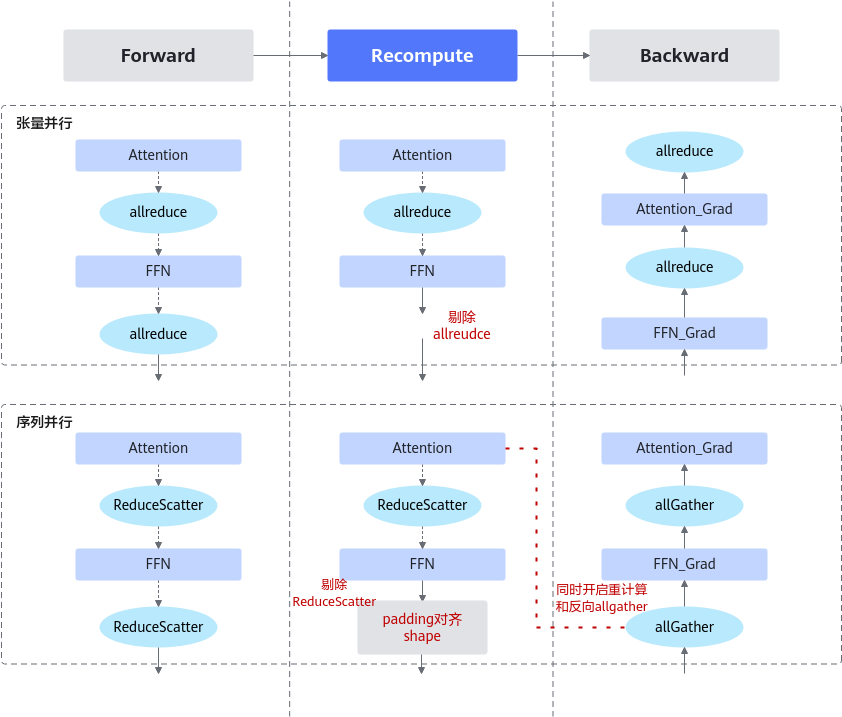
在张量并行模式下,前向传播结束时会插入AllReduce算子,其逆运算为Identity。鉴于重计算的核心目标是保留中间激活值,末端AllReduce算子的输出实为冗余,因此可安全移除,如图1所示,确保既不干扰中间计算流程也不影响后续反向传播。
- 反向通信Overlap
序列并行启用时,前向传播末尾插入ReduceScatter算子,而反向传播则对应插入AllGather算子。通过直接消除ReduceScatter算子,并将AllGather通信隐含于前向计算中,进一步优化了通信流程,如图1所示。
- 重计算层划分优化
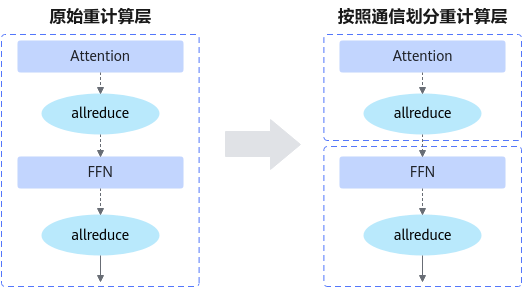
依据通信算子位置精准划分重计算层,将层内通信转换为层末端通信,如图2所示。
结合上述通信优化措施,彻底消除了重计算引入的额外通信耗时,实现了端到端TP维度通信时间的大幅缩减。
使用场景
适用于已启用全节点内张量并行且全面开启重计算的模型
使用方法
通过设置如下参数选择不同级别的通信优化方案:
--optimize-recomp-communication-level N # N可设置为1或者2
- level=1:仅对多层感知机(MLP)层实施通信优化。
- level=2:对MLP层与注意力(ATTN)层均进行通信优化。
使用效果
在Llama2-7B模型全重计算场景下,应用level=1通信优化方案可提升吞吐量2.0%,而level=2方案则带来4.1%的吞吐量增长,显著改善了训练效率。
父主题: 通信性能优化